diff --git a/README.md b/README.md
index 066bde39f..b261bcfd5 100644
--- a/README.md
+++ b/README.md
@@ -4,7 +4,7 @@
## Intro
-This repository is the home of Apify's documentation, which you can find at [docs.apify.com](https://docs.apify.com/). The documentation is written using [Markdown](https://github.com/adam-p/markdown-here/wiki/Markdown-Cheatsheet). Source files of the [platform documentation](https://docs.apify.com/platform) are located in the [/sources](https://github.com/apify/apify-docs/tree/master/sources) directory. However, other sections, such as SDKs for [JavaScript/Node.js](https://docs.apify.com/sdk/js/), [Python](https://docs.apify.com/sdk/python/), or [CLI](https://docs.apify.com/cli), have their own repositories. For more information, see the [Contributing guidelines](./CONTRIBUTING.md).
+This repository is the home of Apify's documentation, which you can find at [docs.apify.com](https://docs.apify.com/). The documentation is written using [Markdown](https://github.com/adam-p/markdown-here/wiki/Markdown-Cheatsheet). Source files of the [platform documentation](https://docs.apify.com/platform) are located in the [/sources](https://github.com/apify/apify-docs/tree/master/sources) directory. However, other sections, such as SDKs for [JavaScript/Node.js](https://docs.apify.com/sdk/js/), [Python](https://docs.apify.com/sdk/python/), or [CLI](https://docs.apify.com/cli/), have their own repositories. For more information, see the [Contributing guidelines](./CONTRIBUTING.md).
## Before you start contributing
diff --git a/sources/academy/glossary/concepts/dynamic_pages.md b/sources/academy/glossary/concepts/dynamic_pages.md
index e7e38f77b..ba38d1cc7 100644
--- a/sources/academy/glossary/concepts/dynamic_pages.md
+++ b/sources/academy/glossary/concepts/dynamic_pages.md
@@ -11,7 +11,7 @@ slug: /concepts/dynamic-pages
---
-Oftentimes, web pages load additional information dynamically, long after their main body is loaded in the browser. A subset of dynamic pages takes this approach further and loads all of its content dynamically. Such style of constructing websites is called Single-page applications (SPAs), and it's widespread thanks to some popular JavaScript libraries, such as [React](https://reactjs.org/) or [Vue](https://vuejs.org/).
+Oftentimes, web pages load additional information dynamically, long after their main body is loaded in the browser. A subset of dynamic pages takes this approach further and loads all of its content dynamically. Such style of constructing websites is called Single-page applications (SPAs), and it's widespread thanks to some popular JavaScript libraries, such as [React](https://react.dev/) or [Vue](https://vuejs.org/).
As you progress in your scraping journey, you'll quickly realize that different websites load their content and populate their pages with data in different ways. Some pages are rendered entirely on the server, some retrieve the data dynamically, and some use a combination of both those methods.
diff --git a/sources/academy/glossary/concepts/http_headers.md b/sources/academy/glossary/concepts/http_headers.md
index 64266bc8d..2fce1b833 100644
--- a/sources/academy/glossary/concepts/http_headers.md
+++ b/sources/academy/glossary/concepts/http_headers.md
@@ -47,4 +47,4 @@ HTTP/1.1 and HTTP/2 headers have several differences. Here are the three key dif
2. Certain headers are no longer used in HTTP/2 (such as **Connection** along with a few others related to it like **Keep-Alive**). In HTTP/2, connection-specific headers are prohibited. While some browsers will ignore them, Safari and other Webkit-based browsers will outright reject any response that contains them. Easy to do by accident, and a big problem.
3. While HTTP/1.1 headers are case-insensitive and could be sent by the browsers with capitalized letters (e.g. **Accept-Encoding**, **Cache-Control**, **User-Agent**), HTTP/2 headers must be lower-cased (e.g. **accept-encoding**, **cache-control**, **user-agent**).
-> To learn more about the difference between HTTP/1.1 and HTTP/2 headers, check out [this](https://httptoolkit.tech/blog/translating-http-2-into-http-1/) article
+> To learn more about the difference between HTTP/1.1 and HTTP/2 headers, check out [this](https://httptoolkit.com/blog/translating-http-2-into-http-1/) article
diff --git a/sources/academy/glossary/concepts/robot_process_automation.md b/sources/academy/glossary/concepts/robot_process_automation.md
index e428f7ede..27d61dcde 100644
--- a/sources/academy/glossary/concepts/robot_process_automation.md
+++ b/sources/academy/glossary/concepts/robot_process_automation.md
@@ -27,7 +27,7 @@ In a traditional automation workflow, you
2. Program a bot that does each of those chunks.
3. Execute the chunks of code in the right order (or in parallel).
-With the advance of [machine learning](https://en.wikipedia.org/wiki/Machine_learning), it is becoming possible to [record](https://www.nice.com/rpa/rpa-guide/process-recorder-function-in-rpa/) your workflows and analyze which can be automated. However, this technology is still not perfected and at times can even be less practical than the manual process.
+With the advance of [machine learning](https://en.wikipedia.org/wiki/Machine_learning), it is becoming possible to [record](https://www.nice.com/info/rpa-guide/process-recorder-function-in-rpa/) your workflows and analyze which can be automated. However, this technology is still not perfected and at times can even be less practical than the manual process.
## Is RPA the same as web scraping? {#is-rpa-the-same-as-web-scraping}
@@ -39,6 +39,6 @@ An easy-to-follow [video](https://www.youtube.com/watch?v=9URSbTOE4YI) on what R
To learn about RPA in plain English, check out [this](https://enterprisersproject.com/article/2019/5/rpa-robotic-process-automation-how-explain) article.
-[This](https://www.cio.com/article/3236451/what-is-rpa-robotic-process-automation-explained.html) article explains what RPA is and discusses both its advantages and disadvantages.
+[This](https://www.cio.com/article/227908/what-is-rpa-robotic-process-automation-explained.html) article explains what RPA is and discusses both its advantages and disadvantages.
You might also like to check out this article on [12 Steps to Automate Workflows](https://quandarycg.com/automating-workflows/).
diff --git a/sources/academy/glossary/tools/postman.md b/sources/academy/glossary/tools/postman.md
index ea1d37db3..5f37b8f4e 100644
--- a/sources/academy/glossary/tools/postman.md
+++ b/sources/academy/glossary/tools/postman.md
@@ -13,7 +13,7 @@ slug: /tools/postman
[Postman](https://www.postman.com/) is a powerful collaboration platform for API development and testing. For scraping use-cases, it's mainly used to test requests and proxies (such as checking the response body of a raw request, without loading any additional resources such as JavaScript or CSS). This tool can do much more than that, but we will not be discussing all of its capabilities here. Postman allows us to test requests with cookies, headers, and payloads so that we can be entirely sure what the response looks like for a request URL we plan to eventually use in a scraper.
-The desktop app can be downloaded from its [official download page](https://www.postman.com/downloads/), or the web app can be used with a signup - no download required. If this is your first time working with a tool like Postman, we recommend checking out their [Getting Started guide](https://learning.postman.com/docs/getting-started/introduction/).
+The desktop app can be downloaded from its [official download page](https://www.postman.com/downloads/), or the web app can be used with a signup - no download required. If this is your first time working with a tool like Postman, we recommend checking out their [Getting Started guide](https://learning.postman.com/docs/introduction/overview/).
## Understanding the interface {#understanding-the-interface}
diff --git a/sources/academy/platform/deploying_your_code/docker_file.md b/sources/academy/platform/deploying_your_code/docker_file.md
index 43e0902dc..f69824d5f 100644
--- a/sources/academy/platform/deploying_your_code/docker_file.md
+++ b/sources/academy/platform/deploying_your_code/docker_file.md
@@ -22,7 +22,7 @@ The **Dockerfile** is a file which gives the Apify platform (or Docker, more spe
If your project doesn’t already contain a Dockerfile, don’t worry! Apify offers [many base images](/sdk/js/docs/guides/docker-images) that are optimized for building and running Actors on the platform, which can be found [here](https://hub.docker.com/u/apify). When using a language for which Apify doesn't provide a base image, [Docker Hub](https://hub.docker.com/) provides a ton of free Docker images for most use-cases, upon which you can create your own images.
-> Tip: You can see all of Apify's Docker images [on DockerHub](https://hub.docker.com/r/apify/).
+> Tip: You can see all of Apify's Docker images [on DockerHub](https://hub.docker.com/u/apify).
At the base level, each Docker image contains a base operating system and usually also a programming language runtime (such as Node.js or Python). You can also find images with preinstalled libraries or install them yourself during the build step.
diff --git a/sources/academy/platform/expert_scraping_with_apify/index.md b/sources/academy/platform/expert_scraping_with_apify/index.md
index e0160243a..f57f273fe 100644
--- a/sources/academy/platform/expert_scraping_with_apify/index.md
+++ b/sources/academy/platform/expert_scraping_with_apify/index.md
@@ -36,7 +36,7 @@ In one of the later lessons, we'll be learning how to integrate our Actor on the
### Docker {#docker}
-Docker is a massive topic on its own, but don't be worried! We only expect you to know and understand the very basics of it, which can be learned about in [this short article](https://docs.docker.com/get-started/overview/) (10 minute read).
+Docker is a massive topic on its own, but don't be worried! We only expect you to know and understand the very basics of it, which can be learned about in [this short article](https://docs.docker.com/guides/docker-overview/) (10 minute read).
### The basics of Actors {#actor-basics}
diff --git a/sources/academy/platform/expert_scraping_with_apify/solutions/using_api_and_client.md b/sources/academy/platform/expert_scraping_with_apify/solutions/using_api_and_client.md
index b43eb8ce9..2f009dac5 100644
--- a/sources/academy/platform/expert_scraping_with_apify/solutions/using_api_and_client.md
+++ b/sources/academy/platform/expert_scraping_with_apify/solutions/using_api_and_client.md
@@ -230,7 +230,7 @@ await Actor.exit();
**A:** The Apify client mimics the Apify API, so there aren't any super significant differences. It's super handy as it helps with managing the API calls (parsing, error handling, retries, etc) and even adds convenience functions.
-The one main difference is that the Apify client automatically uses [**exponential backoff**](/api/client/js#retries-with-exponential-backoff) to deal with errors.
+The one main difference is that the Apify client automatically uses [**exponential backoff**](/api/client/js/docs#retries-with-exponential-backoff) to deal with errors.
**Q: How do you pass input when running an Actor or task via API?**
diff --git a/sources/academy/platform/get_most_of_actors/actor_readme.md b/sources/academy/platform/get_most_of_actors/actor_readme.md
index 61c5508c1..4a4ae5205 100644
--- a/sources/academy/platform/get_most_of_actors/actor_readme.md
+++ b/sources/academy/platform/get_most_of_actors/actor_readme.md
@@ -16,7 +16,7 @@ slug: /get-most-of-actors/actor-readme
- Whenever you build an Actor, think of the original request/idea and the "use case" = "user need" it should solve, please take notes and share them with Apify, so we can help you write a blog post supporting your Actor with more information, more detailed explanation, better SEO.
- Consider adding a video, images, and screenshots to your README to break up the text.
- This is an example of an Actor with a README that corresponds well to the guidelines below:
- - https://apify.com/dtrungtin/airbnb-scraper
+ - [apify.com/tri_angle/airbnb-scraper](https://apify.com/tri_angle/airbnb-scraper)
- Tip no.1: if you want to add snippets of code anywhere in your README, you can use [Carbon](https://github.com/carbon-app/carbon).
- Tip no.2: if you need any quick Markdown guidance, check out https://www.markdownguide.org/cheat-sheet/
@@ -74,12 +74,12 @@ Aim for sections 1–6 below and try to include at least 300 words. You can move
- Refer to the input tab on Actor's detail page. If you like, you can add a screenshot showing the user what the input fields will look like.
- This is an example of how to refer to the input tab:
- > Twitter Scraper has the following input options. Click on the [input tab](https://apify.com/vdrmota/twitter-scraper/input-schema) for more information.
+ > Twitter Scraper has the following input options. Click on the [input tab](https://apify.com/quacker/twitter-scraper/input-schema) for more information.
7. **Output**
- Mention "You can download the dataset extracted by (Actor name) in various formats such as JSON, HTML, CSV, or Excel.”
- - Add a simplified JSON dataset example, like here: https://apify.com/drobnikj/crawler-google-places#output-example
+ - Add a simplified JSON dataset example, like here: [apify.com/compass/crawler-google-places#output-example](https://apify.com/compass/crawler-google-places#output-example)
8. **Tips or Advanced options section**
- Share any tips on how to best run the Actor, such as how to limit compute unit usage, get more accurate results, or improve speed.
diff --git a/sources/academy/platform/get_most_of_actors/index.md b/sources/academy/platform/get_most_of_actors/index.md
index 5a2e4c12c..f6f05cd54 100644
--- a/sources/academy/platform/get_most_of_actors/index.md
+++ b/sources/academy/platform/get_most_of_actors/index.md
@@ -12,7 +12,7 @@ slug: /get-most-of-actors
---
-[Apify Store](https://apify.com/store) is home to hundreds of public Actors available to the Apify community. Anyone is welcome to [publish Actors](/platform/actors/publishing) in the store, and you can even [monetize your Actors](https://get.apify.com/monetize-your-code).
+[Apify Store](https://apify.com/store) is home to hundreds of public Actors available to the Apify community. Anyone is welcome to [publish Actors](/platform/actors/publishing) in the store, and you can even [monetize your Actors](https://apify.com/partners/actor-developers).
In this section, we will go over some of the practical steps you can take to ensure the high quality of your public Actors. You will learn:
diff --git a/sources/academy/platform/get_most_of_actors/monetizing_your_actor.md b/sources/academy/platform/get_most_of_actors/monetizing_your_actor.md
index a6118bf4a..b19b8f6e3 100644
--- a/sources/academy/platform/get_most_of_actors/monetizing_your_actor.md
+++ b/sources/academy/platform/get_most_of_actors/monetizing_your_actor.md
@@ -152,7 +152,7 @@ Getting new users can be an art in itself, but there are **two proven steps** yo
Don’t underestimate your own network! Your social media connections can be a valuable ally in promoting your Actor. Not only can they use your tool to enrich their own professional activities, but also support your work by helping you promote your Actor to their network.
- For inspiration, you can check Apify’s [Twitter](https://twitter.com/apify), [Facebook](https://www.facebook.com/apifytech/), and [LinkedIn](https://linkedin.com/company/apifytech) pages, and **don’t forget to tag Apify on your posts** we will retweet and share your posts to help you reach an even broader audience.
+ For inspiration, you can check Apify’s [Twitter](https://twitter.com/apify) or [LinkedIn](https://www.linkedin.com/company/apifytech/) pages, and **don’t forget to tag Apify on your posts** we will retweet and share your posts to help you reach an even broader audience.
- **YouTube**
diff --git a/sources/academy/platform/get_most_of_actors/naming_your_actor.md b/sources/academy/platform/get_most_of_actors/naming_your_actor.md
index 93b81f573..1884865e9 100644
--- a/sources/academy/platform/get_most_of_actors/naming_your_actor.md
+++ b/sources/academy/platform/get_most_of_actors/naming_your_actor.md
@@ -17,7 +17,7 @@ Naming your Actor can be tricky. Especially when you've spent a long time coding
## Scrapers {#scrapers}
-For Actors such as [YouTube Scraper](https://apify.com/bernardo/youtube-scraper) or [Amazon Scraper](https://apify.com/vaclavrut/amazon-crawler), which scrape web pages, we usually have one Actor per domain. This helps with naming, as the domain name serves as your Actor's name.
+For Actors such as [YouTube Scraper](https://apify.com/streamers/youtube-scraper) or [Amazon Scraper](https://apify.com/junglee/amazon-crawler), which scrape web pages, we usually have one Actor per domain. This helps with naming, as the domain name serves as your Actor's name.
GOOD:
diff --git a/sources/academy/platform/get_most_of_actors/seo_and_promotion.md b/sources/academy/platform/get_most_of_actors/seo_and_promotion.md
index 4a79d34d0..b23fbcc02 100644
--- a/sources/academy/platform/get_most_of_actors/seo_and_promotion.md
+++ b/sources/academy/platform/get_most_of_actors/seo_and_promotion.md
@@ -102,11 +102,11 @@ Now that you’ve created a cool new Actor, let others see it! Share it on your
- Try to publish an article about your Actor in relevant external magazines like [hackernoon.com](https://hackernoon.com/) or [techcrunch.com](https://techcrunch.com/). Do not limit yourself to blogging platforms.
- If you publish an article in external media (magazine, blog etc.), be sure to include backlinks to your Actor and the Apify website to strengthen the domain's SEO.
- It's always better to use backlinks with the [`dofollow` attribute](https://raventools.com/marketing-glossary/dofollow-link/).
-- Always use the most relevant URL as the backlink's landing page. For example, when talking about Apify Store, link to the Store page (https://apify.com/store), not to Apify homepage (https://apify.com).
+- Always use the most relevant URL as the backlink's landing page. For example, when talking about Apify Store, link to the Store page ([apify.com/store](https://apify.com/store)), not to Apify homepage ([apify.com](https://apify.com)).
- Always use the most relevant keyword or phrase for the backlink's text. This can boost the landing page's SEO and help the readers know what to expect from the link.
-> **GOOD**: Try the [Facebook scraper](https://apify.com/pocesar/facebook-pages-scraper) now.
-> ` tag, as titles should be.
Maybe surprisingly, we find that there are actually two `` tags on the detail page. This should get us thinking.
@@ -84,7 +84,7 @@ async function pageFunction(context) {
Getting the Actor's description is a little more involved, but still pretty straightforward. We cannot search for a ` ` tag, because there's a lot of them in the page. We need to narrow our search down a little. Using the DevTools we find that the Actor description is nested within
the `` element too, same as the title. Moreover, the actual description is nested inside a `` tag with a class `actor-description`.
-
+
```js
async function pageFunction(context) {
@@ -101,7 +101,7 @@ async function pageFunction(context) {
The DevTools tell us that the `modifiedDate` can be found in a `` element.
-
+
```js
async function pageFunction(context) {
@@ -270,12 +270,12 @@ While with Web Scraper and **Puppeteer Scraper** ([apify/puppeteer-scraper](http
with Cheerio Scraper we need to dig a little deeper into the page's architecture. For this, we will use
the Network tab of the Chrome DevTools.
-> DevTools is a powerful tool with many features, so if you're not familiar with it, please [see Google's tutorial](https://developers.google.com/web/tools/chrome-devtools/network/), which explains everything much better than we ever could.
+> DevTools is a powerful tool with many features, so if you're not familiar with it, please [see Google's tutorial](https://developer.chrome.com/docs/devtools/), which explains everything much better than we ever could.
We want to know what happens when we click the **Show more** button, so we open the DevTools **Network** tab and clear it.
Then we click the **Show more** button and wait for incoming requests to appear in the list.
-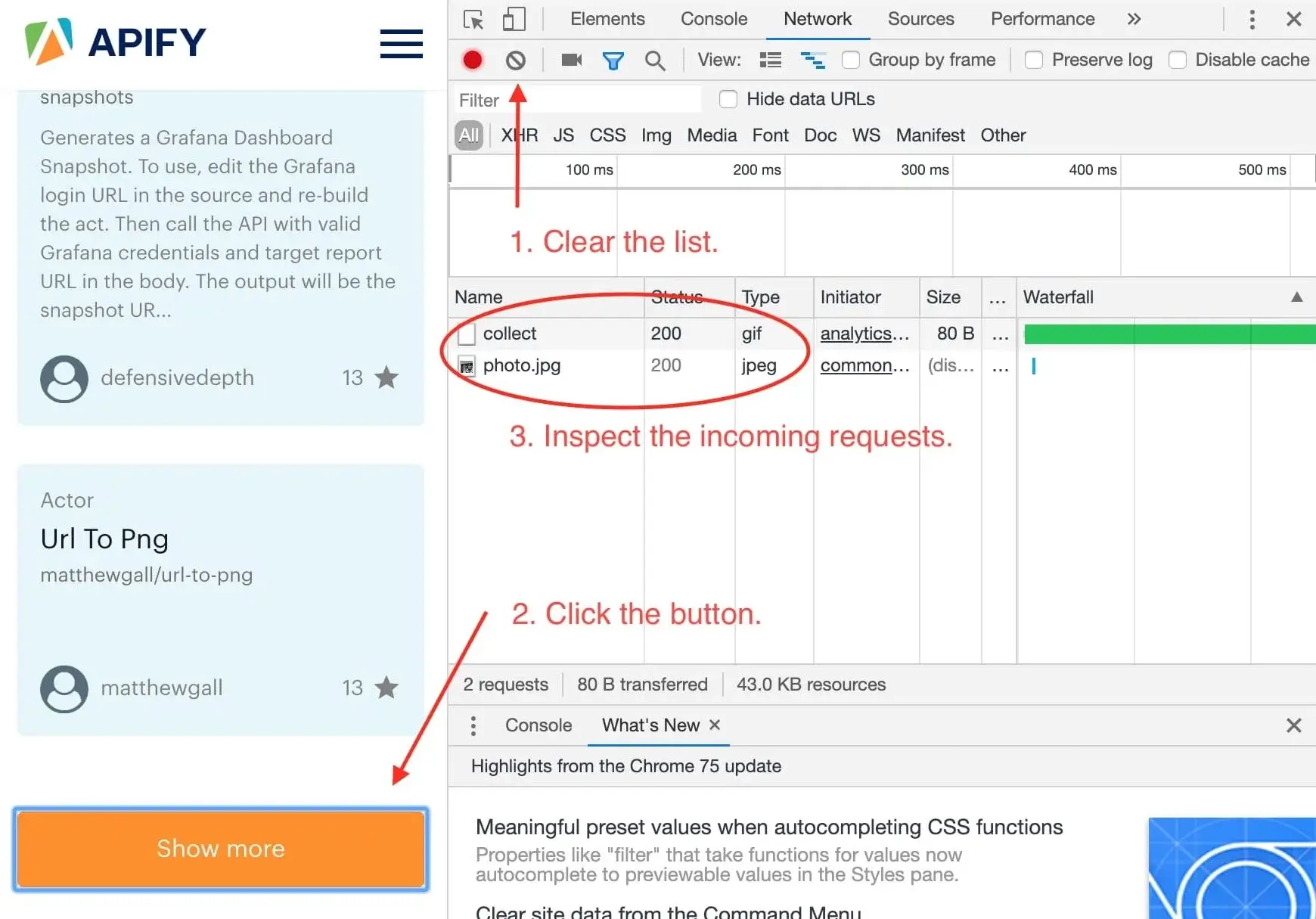
+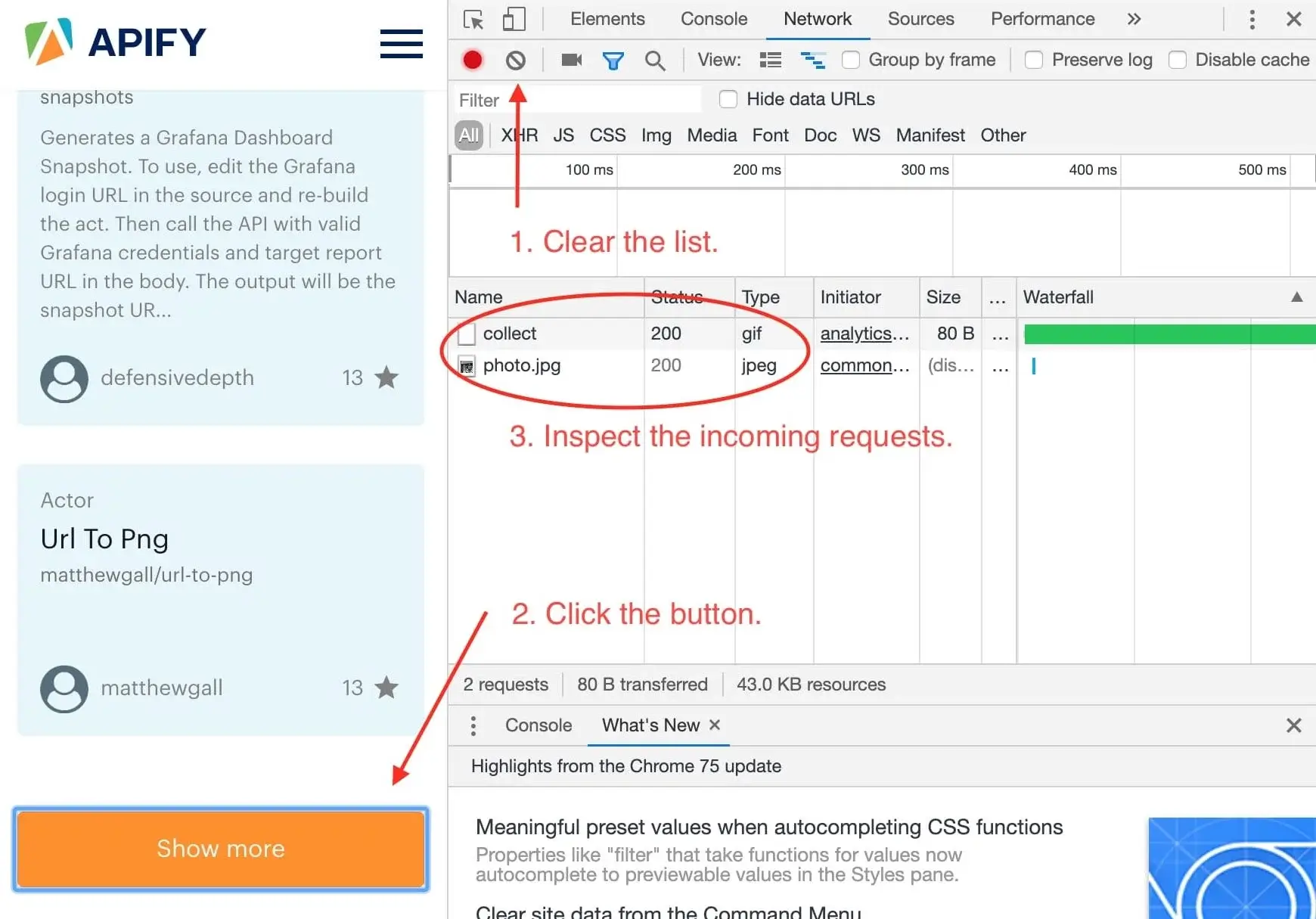
Now, this is interesting. It seems that we've only received two images after clicking the button and no additional
data. This means that the data about Actors must already be available in the page and the **Show more** button only displays it. This is good news.
@@ -288,7 +288,7 @@ few hits do not provide any interesting information, but in the end, we find our
with the ID `__NEXT_DATA__` that seems to hold a lot of information about Web Scraper. In DevTools,
you can right click an element and click **Store as global variable** to make this element available in the **Console**.
-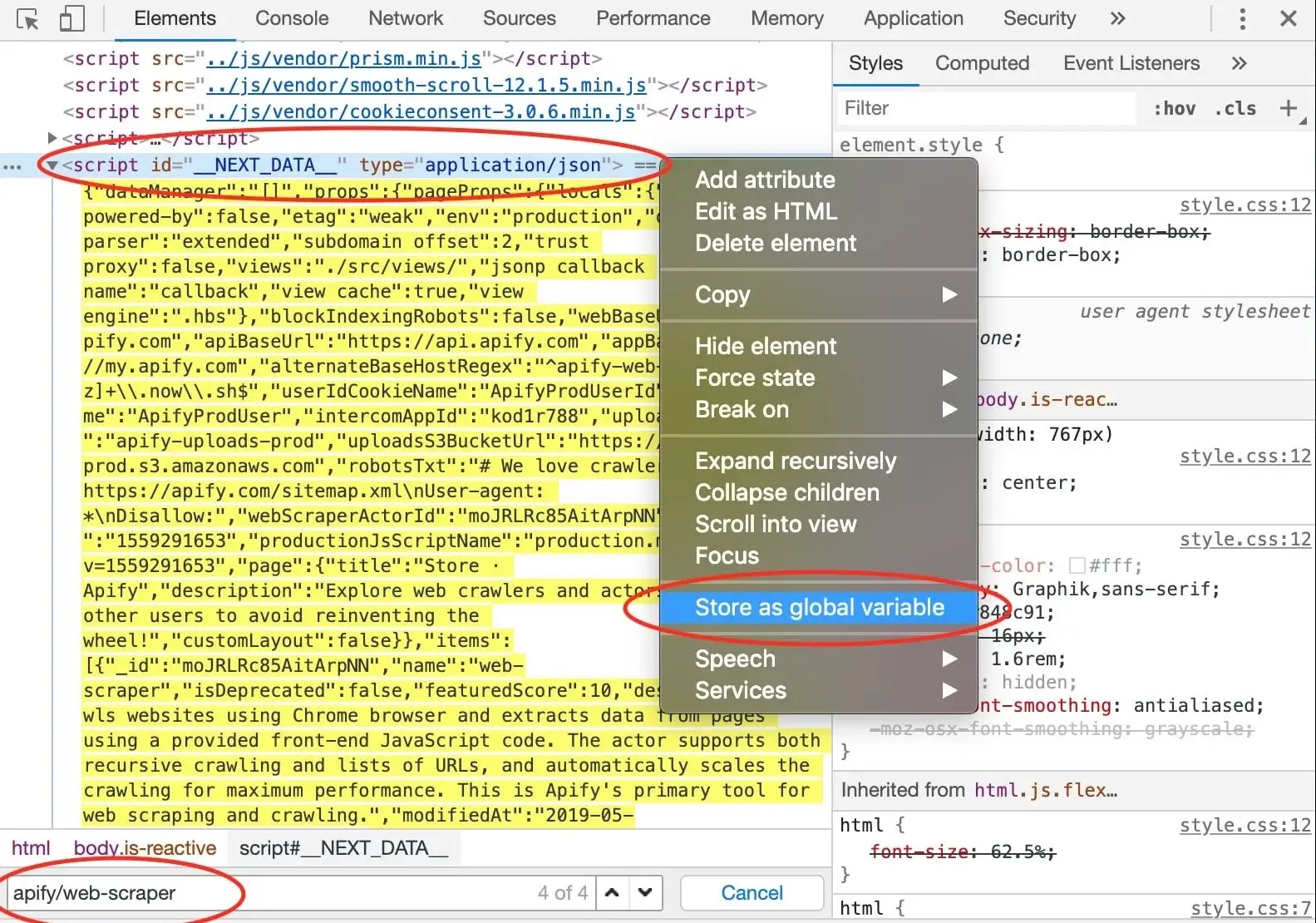
+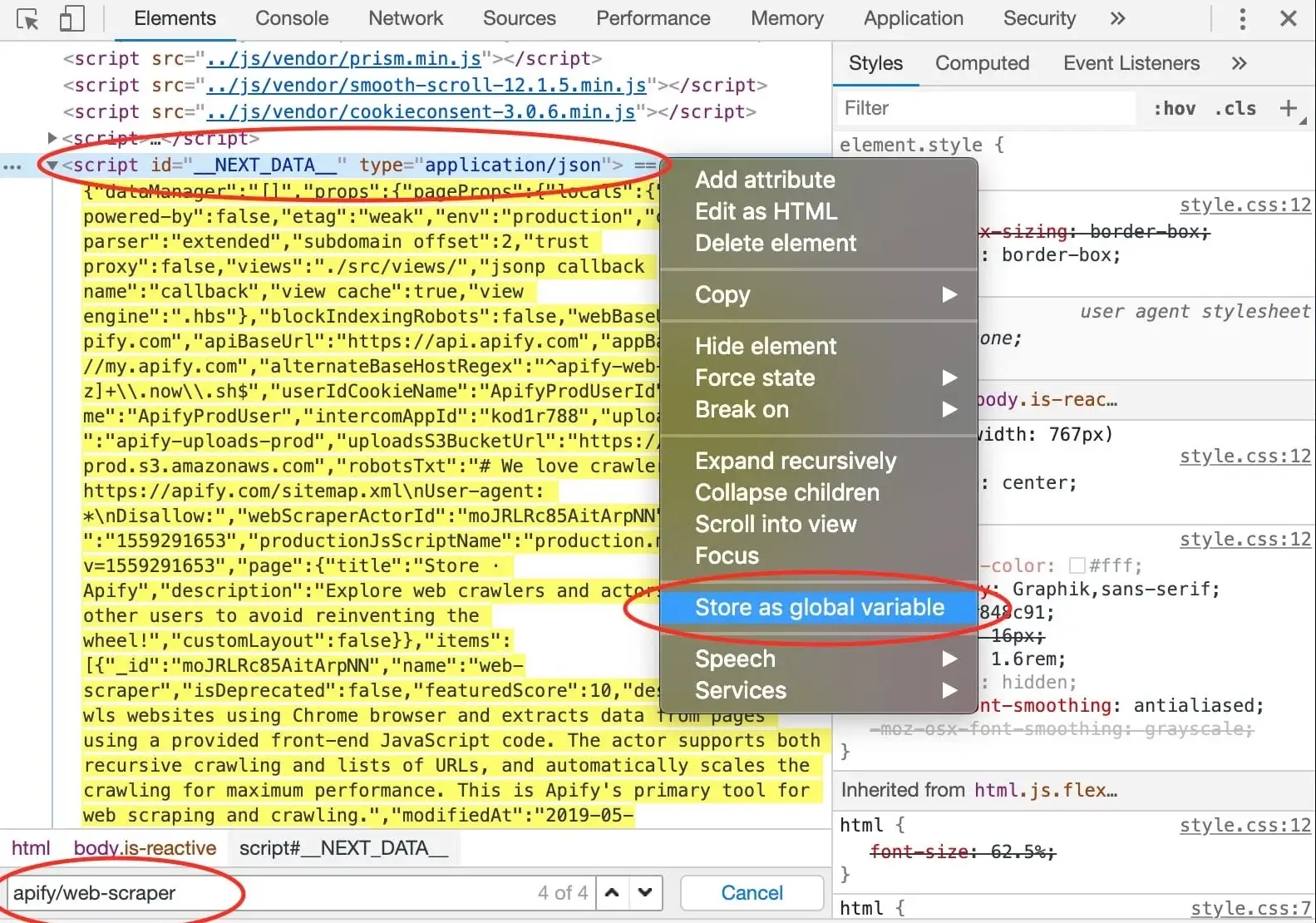
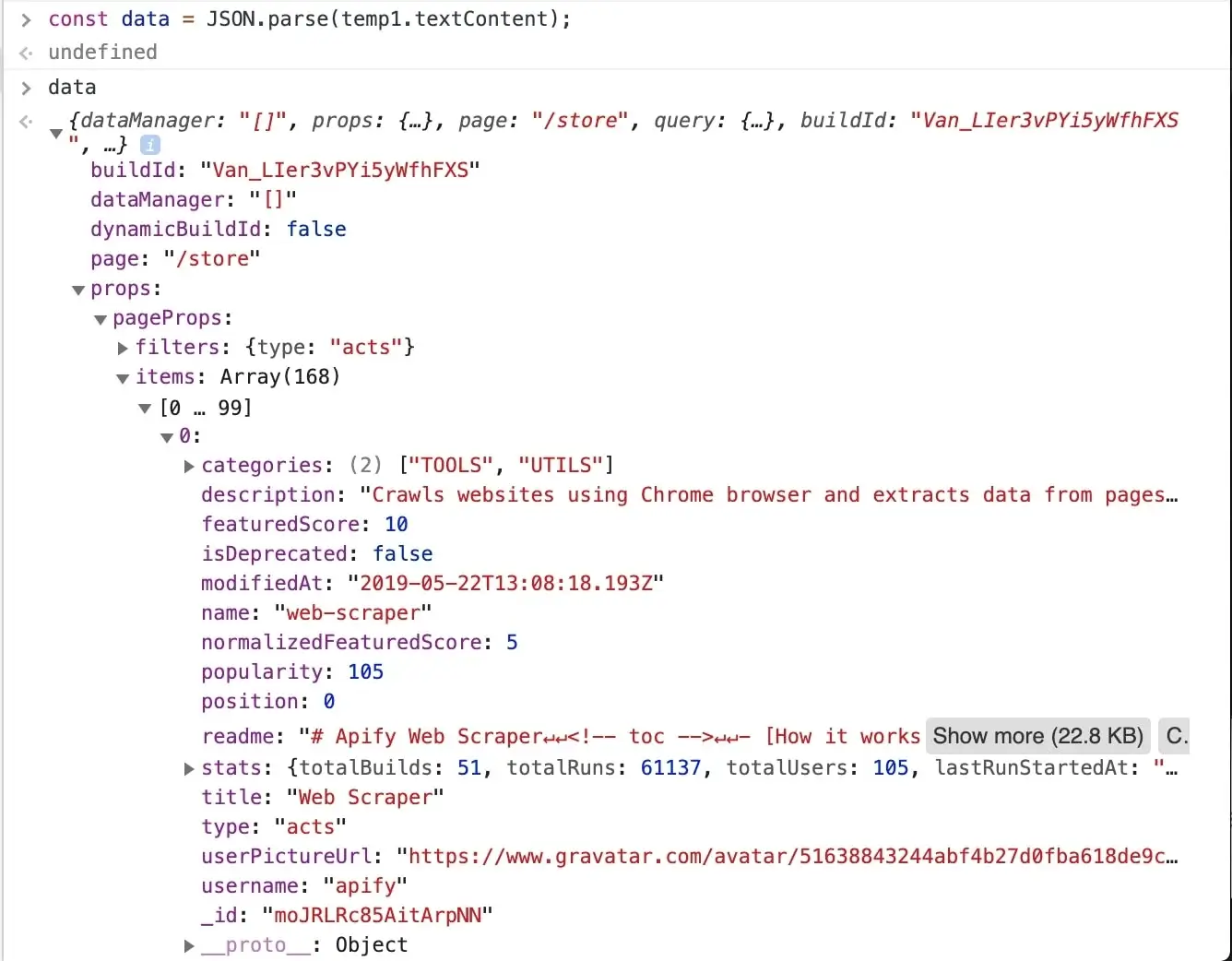
A `temp1` variable is now added to your console. We're mostly interested in its contents and we can get that using
the `temp1.textContent` property. You can see that it's a rather large JSON string. How do we know?
@@ -302,7 +302,7 @@ const data = JSON.parse(temp1.textContent);
After entering the above command into the console, we can inspect the `data` variable and see that all the information
we need is there, in the `data.props.pageProps.items` array. Great!
-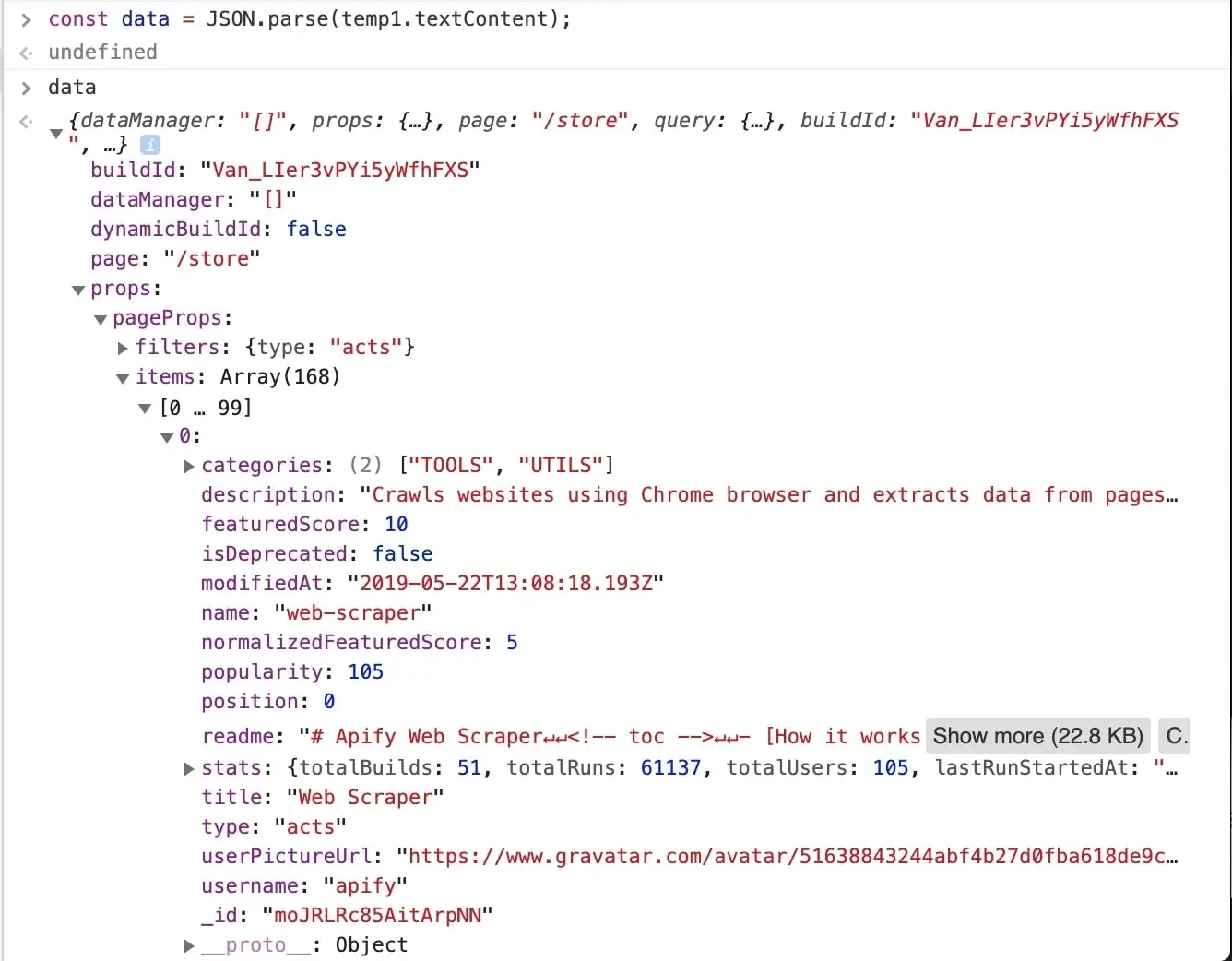
+
> It's obvious that all the information we set to scrape is available in this one data object,
so you might already be wondering, can I make one request to the store to get this JSON
@@ -501,9 +501,9 @@ Thank you for reading this whole tutorial! Really! It's important to us that our
## [](#whats-next) What's next
-* Check out the [Apify SDK](https://sdk.apify.com/) and its [Getting started](https://sdk.apify.com/docs/guides/getting-started) tutorial if you'd like to try building your own Actors. It's a bit more complex and involved than writing a `pageFunction`, but it allows you to fine-tune all the details of your scraper to your liking.
+* Check out the [Apify SDK](https://docs.apify.com/sdk) and its [Getting started](https://docs.apify.com/sdk/js/docs/guides/apify-platform) tutorial if you'd like to try building your own Actors. It's a bit more complex and involved than writing a `pageFunction`, but it allows you to fine-tune all the details of your scraper to your liking.
* [Take a deep dive into Actors](/platform/actors), from how they work to [publishing](/platform/actors/publishing) them in Apify Store, and even [making money](https://blog.apify.com/make-regular-passive-income-developing-web-automation-actors-b0392278d085/) on Actors.
-* Found out you're not into the coding part but would still to use Apify Actors? Check out our [ready-made solutions](https://apify.com/store) or [order a custom Actor](https://apify.com/custom-solutions) from an Apify-certified developer.
+* Found out you're not into the coding part but would still to use Apify Actors? Check out our [ready-made solutions](https://apify.com/store) or [order a custom Actor](https://apify.com/contact-sales) from an Apify-certified developer.
**Learn how to scrape a website using Apify's Cheerio Scraper. Build an Actor's page function, extract information from a web page and download your data.**
diff --git a/sources/academy/tutorials/apify_scrapers/getting_started.md b/sources/academy/tutorials/apify_scrapers/getting_started.md
index 68fdfe62f..6a8aa11d1 100644
--- a/sources/academy/tutorials/apify_scrapers/getting_started.md
+++ b/sources/academy/tutorials/apify_scrapers/getting_started.md
@@ -2,7 +2,7 @@
title: Getting started with Apify scrapers
menuTitle: Getting started
description: Step-by-step tutorial that will help you get started with all Apify Scrapers. Learn the foundations of scraping the web with Apify and creating your own Actors.
-externalSourceUrl: https://raw.githubusercontent.com/apifytech/actor-scraper/master/docs/build/introduction-tutorial.md
+externalSourceUrl: https://raw.githubusercontent.com/apify/actor-scraper/master/docs/build/introduction-tutorial.md
sidebar_position: 1
slug: /apify-scrapers/getting-started
---
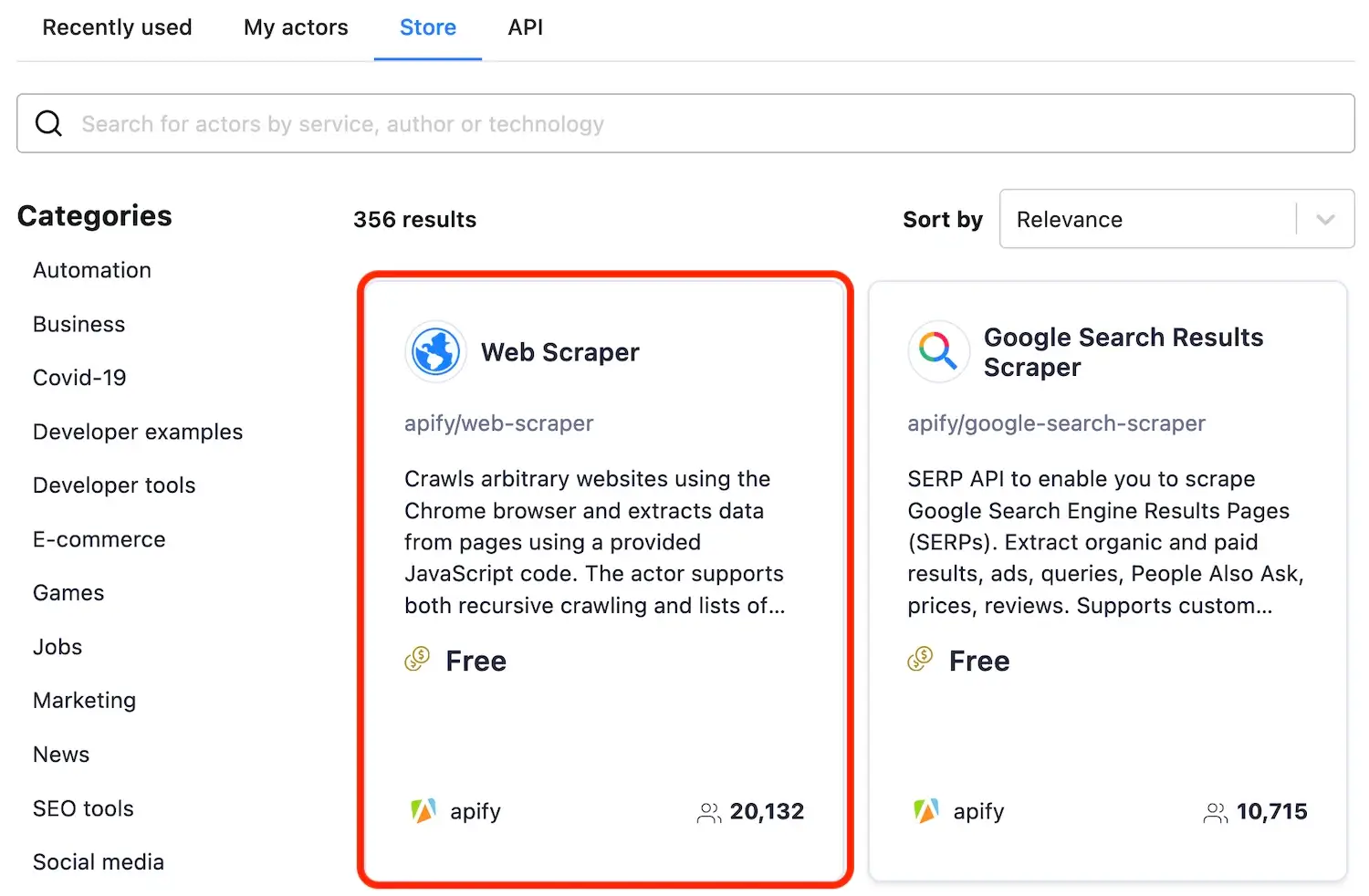
@@ -27,7 +27,7 @@ Depending on how you arrived at this tutorial, you may already have your first t
> This tutorial covers the use of **Web**, **Cheerio**, and **Puppeteer** scrapers, but a lot of the information here can be used with all Actors. For this tutorial, we will select **Web Scraper**.
-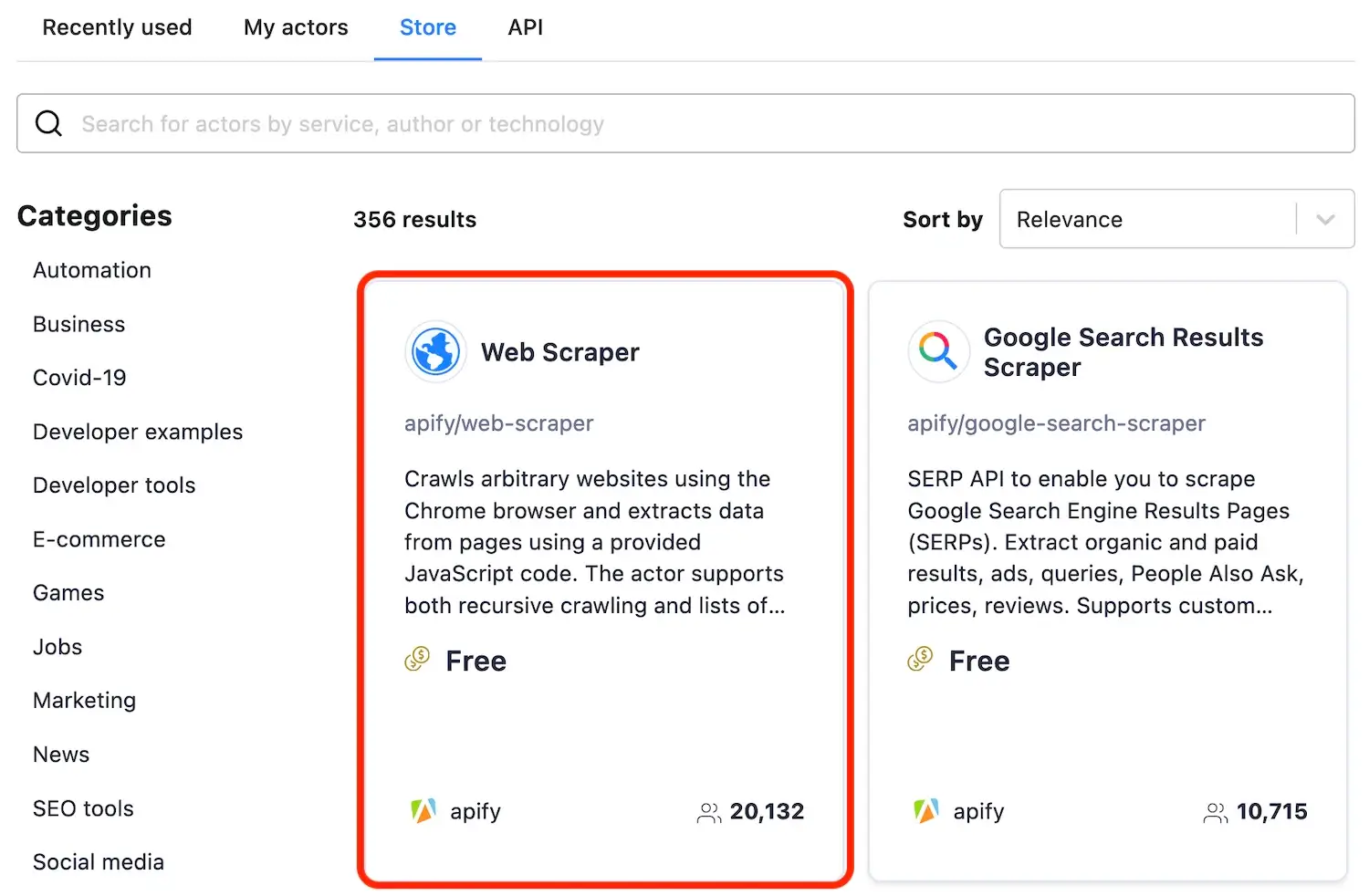
+
### [](#running-a-task) Running a task
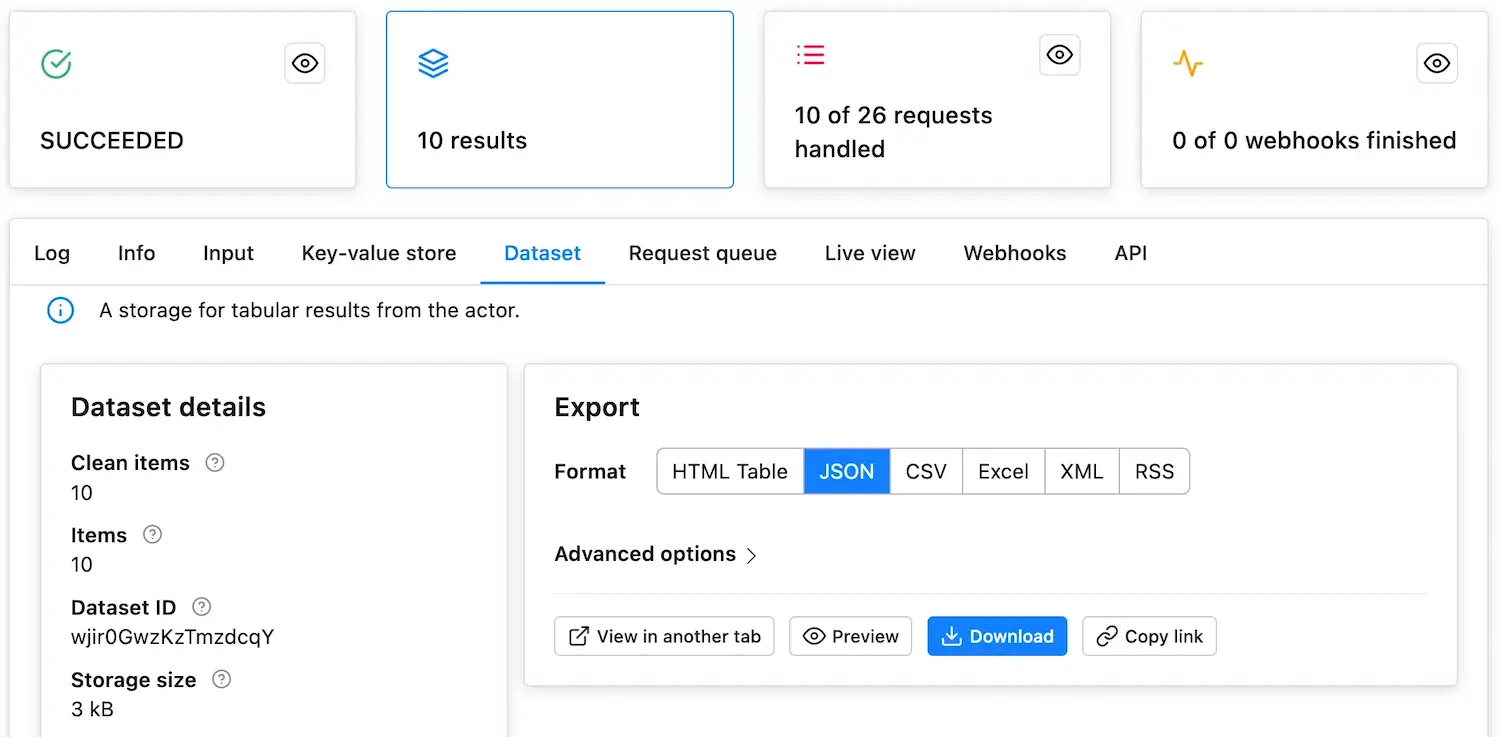
@@ -47,7 +47,7 @@ After clicking **Save & Run**, the window will change to the run detail. Here, y
Now that the run has `SUCCEEDED`, click on the glowing **Results** card to see the scrape's results. This takes you to the **Dataset** tab, where you can display or download the results in various formats. For now, click the **Preview** button. Voila, the scraped data!
-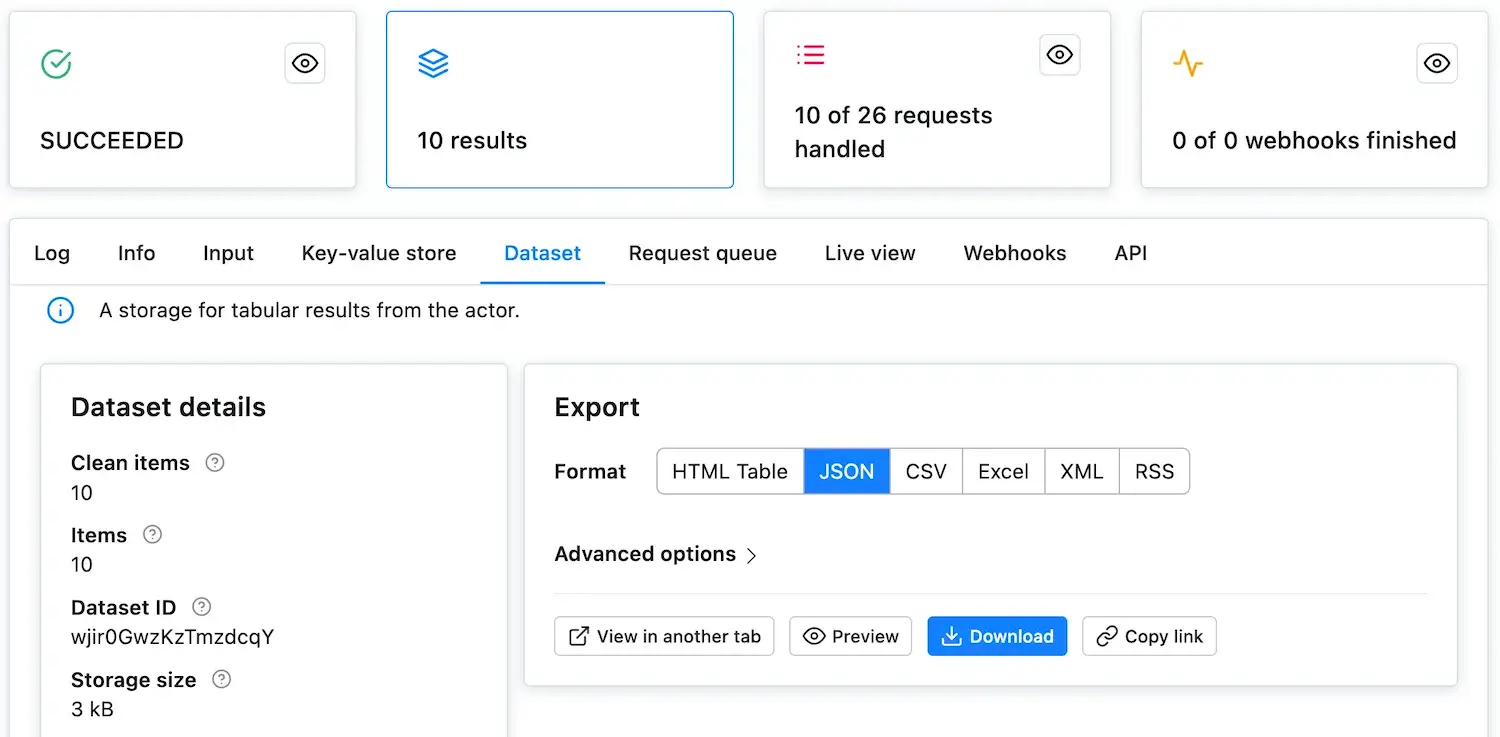
+
Good job! We've run our first task and got some results. Let's learn how to change the default configuration to scrape something more interesting than the page's ``.
@@ -55,7 +55,7 @@ Good job! We've run our first task and got some results. Let's learn how to chan
Before we jump into the scraping itself, let's have a quick look at the user interface that's available to us. Click on the task's name in the top-left corner to visit the task's configuration.
-
+
### [](#input) Input and options
@@ -110,7 +110,7 @@ Some of this information may be scraped directly from the listing pages, but for
In the **Input** tab of the task we have, we'll change the **Start URL** from **https://apify.com**. This will tell the scraper to start by opening a different URL. You can add more **Start URL**s or even [use a file with a list of thousands of them](#-crawling-the-website-with-pseudo-urls), but in this case, we'll be good with just one.
-How do we choose the new **Start URL**? The goal is to scrape all Actors in the store, which is available at https://apify.com/store, so we choose this URL as our **Start URL**.
+How do we choose the new **Start URL**? The goal is to scrape all Actors in the store, which is available at [apify.com/store](https://apify.com/store), so we choose this URL as our **Start URL**.
```text
https://apify.com/store
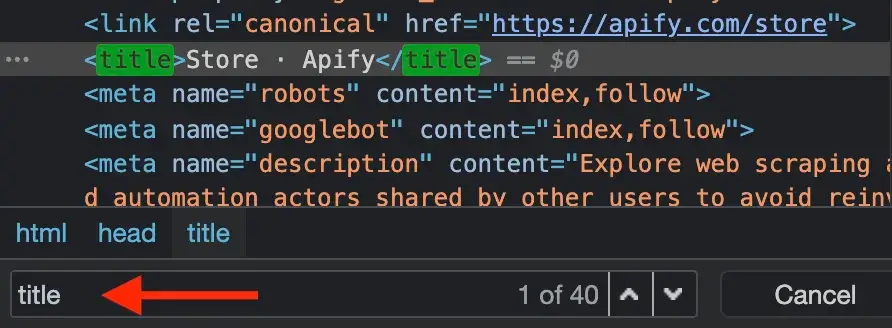
@@ -204,9 +204,9 @@ The DevTools window will pop up and display a lot of, perhaps unfamiliar, inform
You'll see that the Element tab jumps to the first `<title>` element of the current page and that the title is **Store · Apify**. It's always good practice to do your research using the DevTools before writing the `pageFunction` and running your task.
-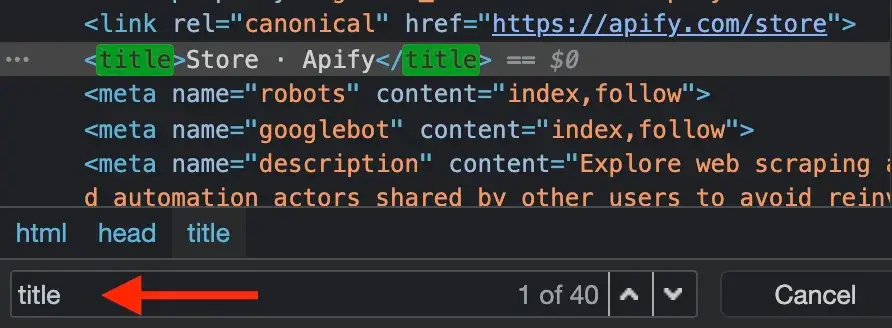
+
-> For the sake of brevity, we won't go into the details of using the DevTools in this tutorial. If you're just starting out with DevTools, this [Google tutorial](https://developers.google.com/web/tools/chrome-devtools/) is a good place to begin.
+> For the sake of brevity, we won't go into the details of using the DevTools in this tutorial. If you're just starting out with DevTools, this [Google tutorial](https://developer.chrome.com/docs/devtools/) is a good place to begin.
### [](#understanding-context) Understanding `context`
diff --git a/sources/academy/tutorials/apify_scrapers/puppeteer_scraper.md b/sources/academy/tutorials/apify_scrapers/puppeteer_scraper.md
index ab7674215..1ac1a1f5d 100644
--- a/sources/academy/tutorials/apify_scrapers/puppeteer_scraper.md
+++ b/sources/academy/tutorials/apify_scrapers/puppeteer_scraper.md
@@ -2,7 +2,7 @@
title: Scraping with Puppeteer Scraper
menuTitle: Puppeteer Scraper
description: Learn how to scrape a website using Apify's Puppeteer Scraper. Build an Actor's page function, extract information from a web page and download your data.
-externalSourceUrl: https://raw.githubusercontent.com/apifytech/actor-scraper/master/docs/build/puppeteer-scraper-tutorial.md
+externalSourceUrl: https://raw.githubusercontent.com/apify/actor-scraper/master/docs/build/puppeteer-scraper-tutorial.md
sidebar_position: 4
slug: /apify-scrapers/puppeteer-scraper
---
@@ -19,10 +19,10 @@ because this one builds on topics and code examples discussed there.
## [](#getting-to-know-our-tools) Getting to know our tools
-In the [Getting started with Apify scrapers](https://apify.com/docs/scraping/tutorial/introduction) tutorial, we've confirmed that the scraper works as expected,
+In the [Getting started with Apify scrapers](https://docs.apify.com/academy/apify-scrapers/getting-started) tutorial, we've confirmed that the scraper works as expected,
so now it's time to add more data to the results.
-To do that, we'll be using the [Puppeteer library](https://github.com/GoogleChrome/puppeteer). Puppeteer is a browser
+To do that, we'll be using the [Puppeteer library](https://github.com/puppeteer/puppeteer). Puppeteer is a browser
automation library that allows you to control a browser using JavaScript. That is, simulate a real human sitting
in front of a computer, using a mouse and a keyboard. It gives you almost unlimited possibilities, but you need to learn
quite a lot before you'll be able to use all of its features. We'll walk you through some of the basics of Puppeteer,
@@ -62,14 +62,14 @@ Before we start, let's do a quick recap of the data we chose to scrape:
5. **Last modification date** - When the Actor was last modified.
6. **Number of runs** - How many times the Actor was run.
-
+
We've already scraped numbers 1 and 2 in the [Getting started with Apify scrapers](/academy/apify-scrapers/getting-started)
tutorial, so let's get to the next one on the list: title.
### [](#title) Title
-
+
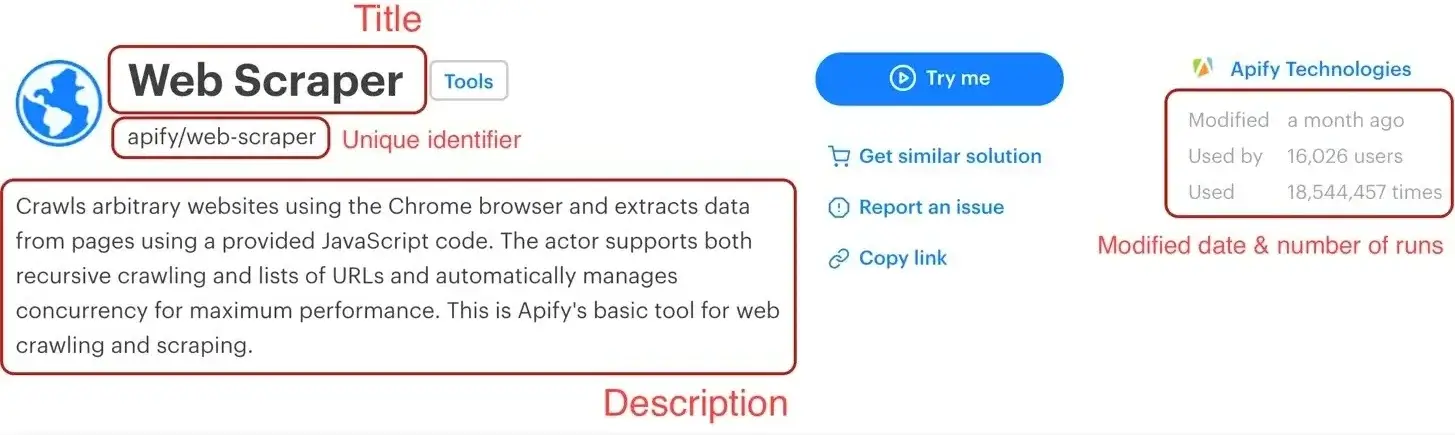
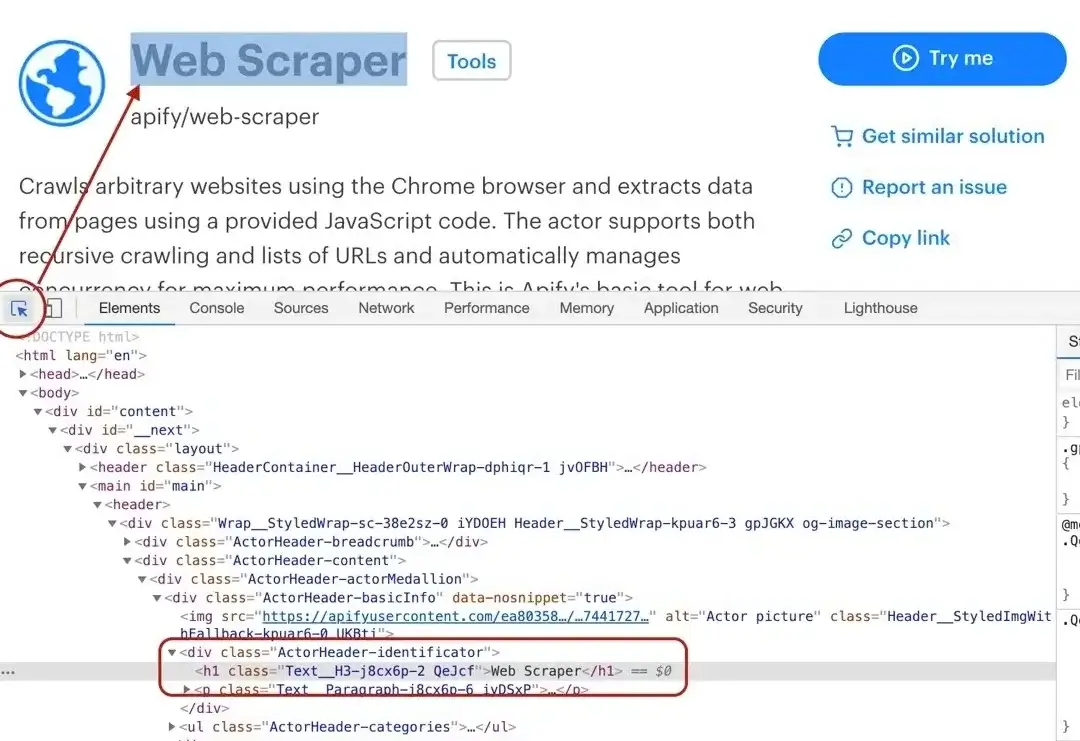
By using the element selector tool, we find out that the title is there under an `<h1>` tag, as titles should be.
Maybe surprisingly, we find that there are actually two `<h1>` tags on the detail page. This should get us thinking.
@@ -108,7 +108,7 @@ is automatically passed back to the Node.js context, so we receive an actual `st
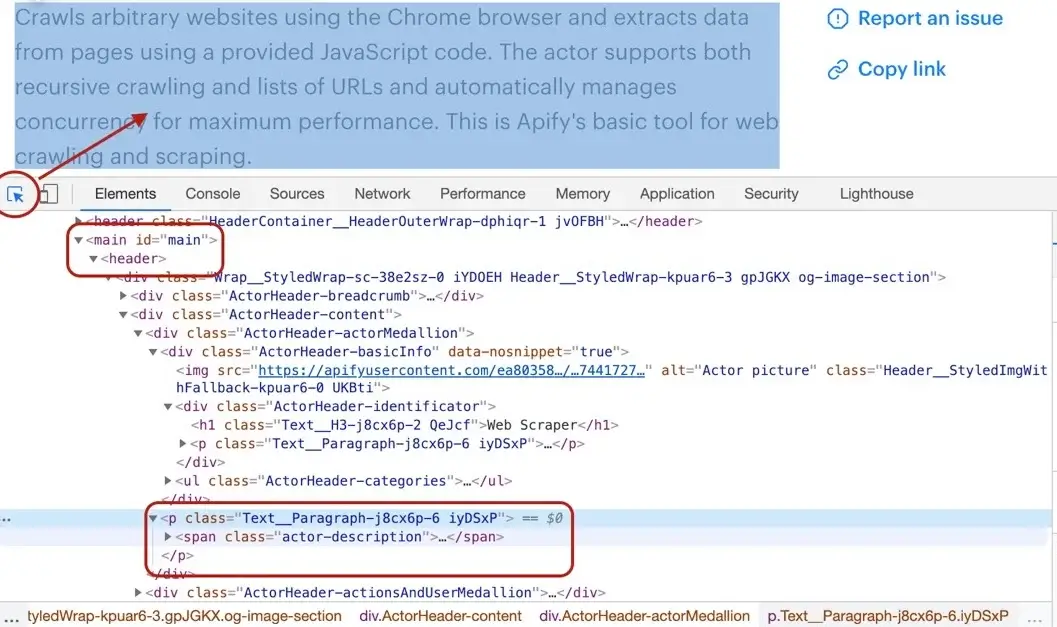
Getting the Actor's description is a little more involved, but still pretty straightforward. We cannot search for a `<p>` tag, because there's a lot of them in the page. We need to narrow our search down a little. Using the DevTools we find that the Actor description is nested within
the `<header>` element too, same as the title. Moreover, the actual description is nested inside a `<span>` tag with a class `actor-description`.
-
+
```js
async function pageFunction(context) {
@@ -133,7 +133,7 @@ async function pageFunction(context) {
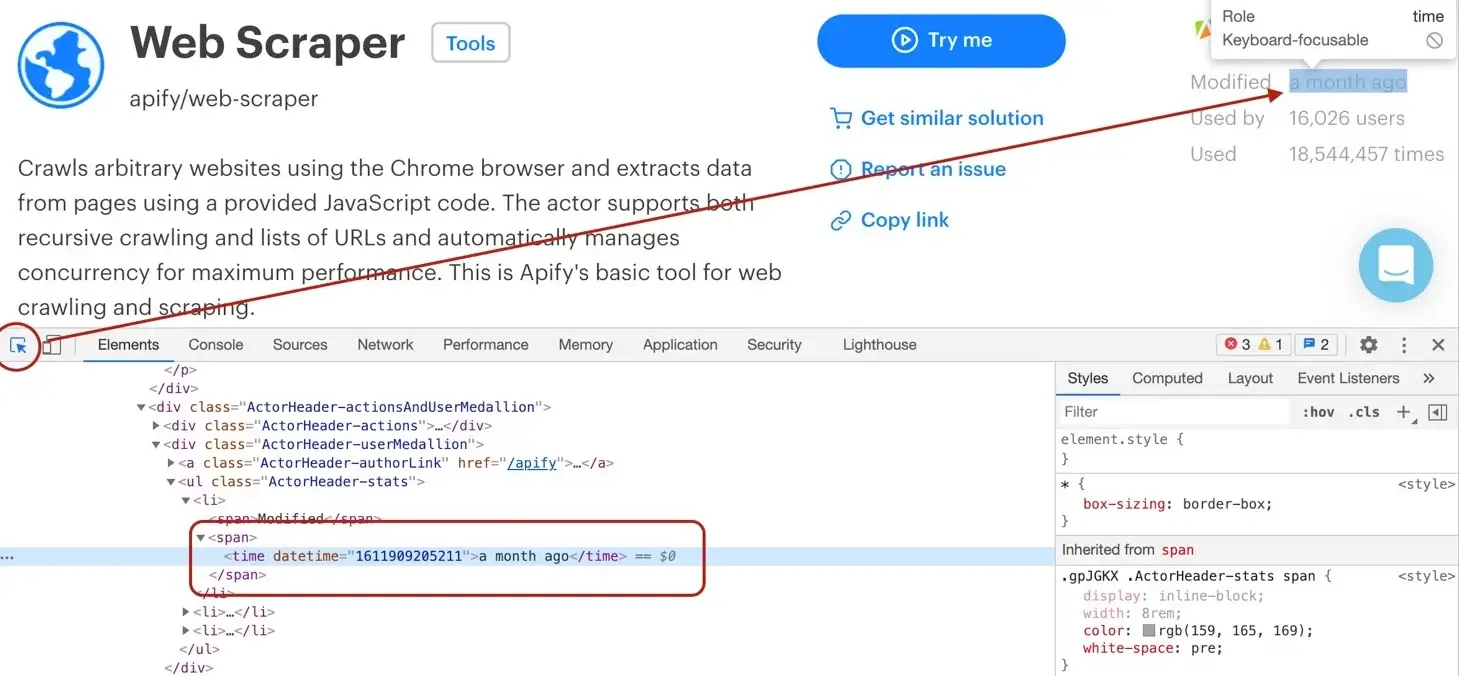
The DevTools tell us that the `modifiedDate` can be found in a `<time>` element.
-
+
```js
async function pageFunction(context) {
@@ -426,7 +426,7 @@ div.show-more > button
> Don't forget to confirm our assumption in the DevTools finder tool (CTRL/CMD + F).
-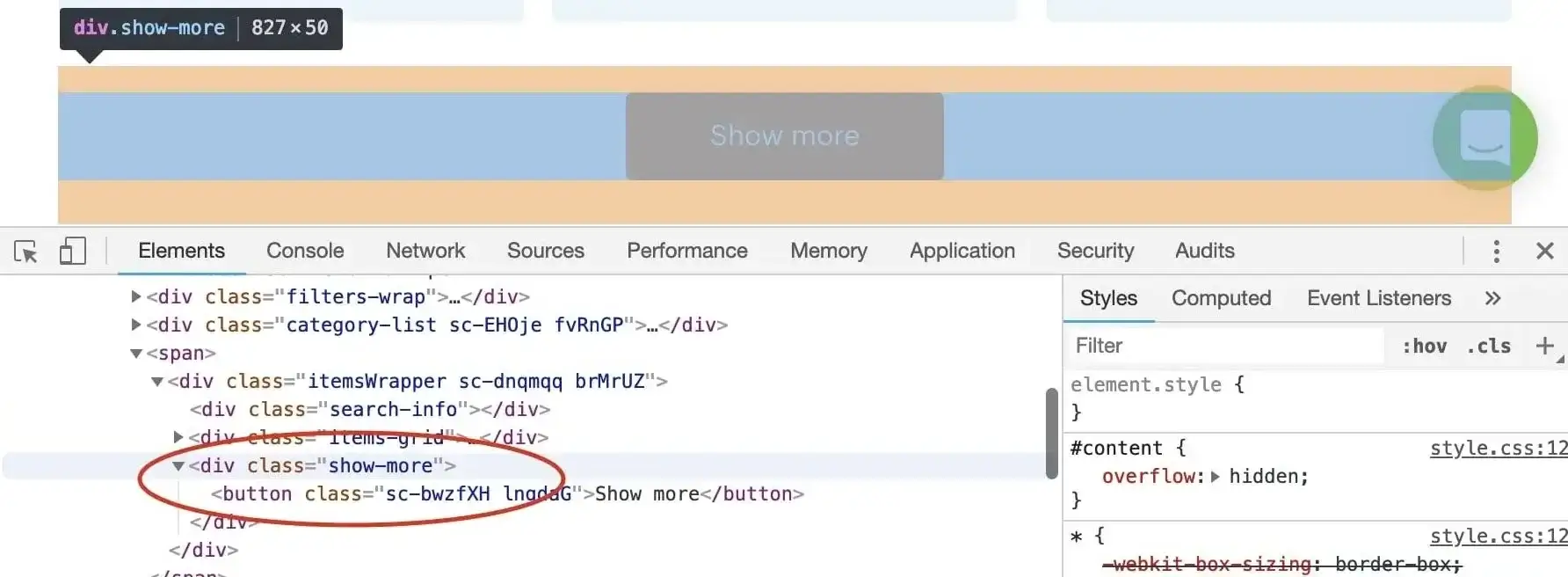
+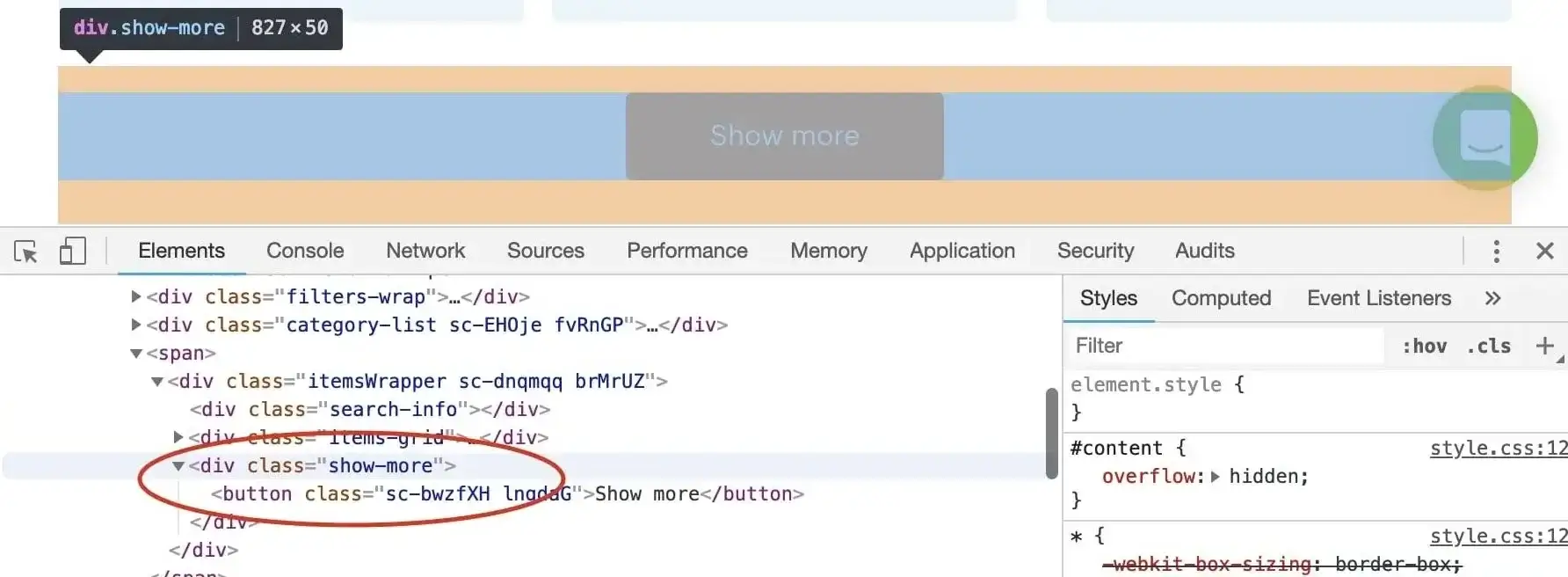
Now that we know what to wait for, we plug it into the `waitFor()` function.
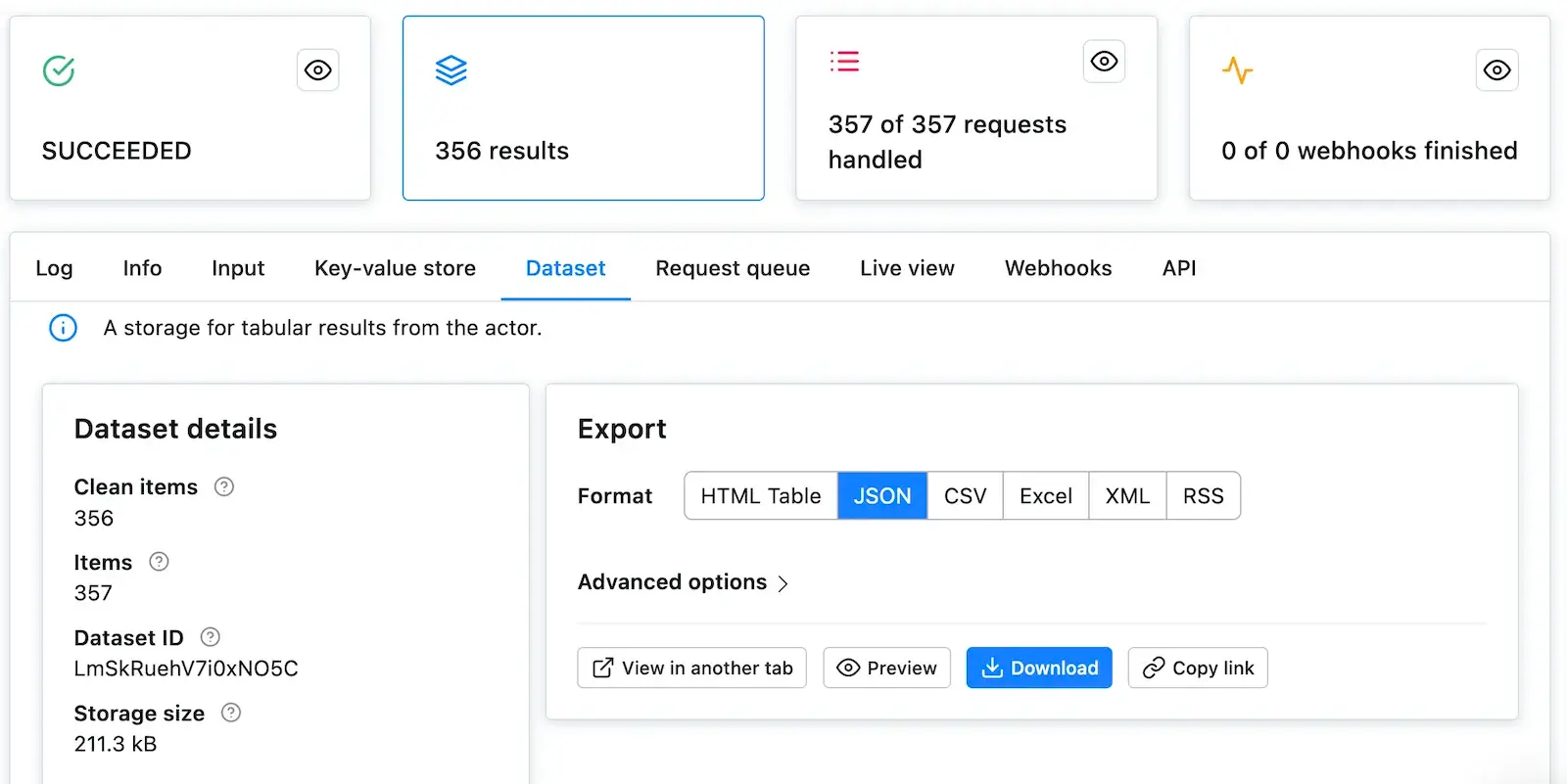
@@ -579,7 +579,7 @@ through all the Actors and then scrape all of their data. After it succeeds, ope
You've successfully scraped Apify Store. And if not, no worries, go through the code examples again,
it's probably just a typo.
-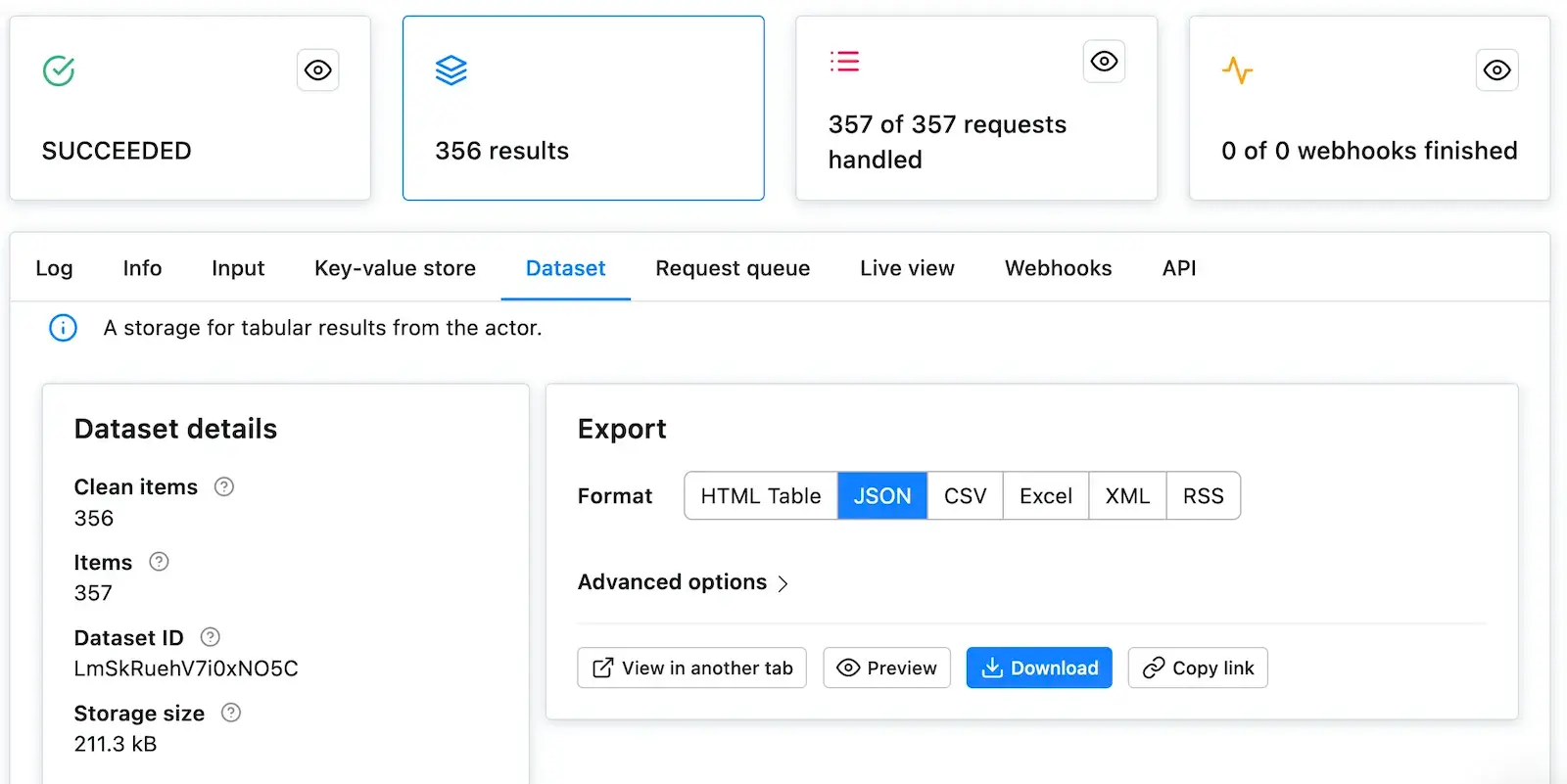
+
## [](#downloading-our-scraped-data) Downloading the scraped data
@@ -821,9 +821,9 @@ Thank you for reading this whole tutorial! Really! It's important to us that our
## [](#whats-next) What's next?
-- Check out the [Apify SDK](https://sdk.apify.com/) and its [Getting started](https://sdk.apify.com/docs/guides/getting-started) tutorial if you'd like to try building your own Actors. It's a bit more complex and involved than writing a `pageFunction`, but it allows you to fine-tune all the details of your scraper to your liking.
+- Check out the [Apify SDK](https://docs.apify.com/sdk) and its [Getting started](https://docs.apify.com/sdk/js/docs/guides/apify-platform) tutorial if you'd like to try building your own Actors. It's a bit more complex and involved than writing a `pageFunction`, but it allows you to fine-tune all the details of your scraper to your liking.
- [Take a deep dive into Actors](/platform/actors), from how they work to [publishing](/platform/actors/publishing) them in Apify Store, and even [making money](https://blog.apify.com/make-regular-passive-income-developing-web-automation-actors-b0392278d085/) on Actors.
-- Found out you're not into the coding part but would still to use Apify Actors? Check out our [ready-made solutions](https://apify.com/store) or [order a custom Actor](https://apify.com/custom-solutions) from an Apify-certified developer.
+- Found out you're not into the coding part but would still to use Apify Actors? Check out our [ready-made solutions](https://apify.com/store) or [order a custom Actor](https://apify.com/contact-sales) from an Apify-certified developer.
**Learn how to scrape a website using Apify's Puppeteer Scraper. Build an Actor's page function, extract information from a web page and download your data.**
diff --git a/sources/academy/tutorials/apify_scrapers/web_scraper.md b/sources/academy/tutorials/apify_scrapers/web_scraper.md
index 784fdf749..4610619fc 100644
--- a/sources/academy/tutorials/apify_scrapers/web_scraper.md
+++ b/sources/academy/tutorials/apify_scrapers/web_scraper.md
@@ -2,11 +2,11 @@
title: Scraping with Web Scraper
menuTitle: Web Scraper
description: Learn how to scrape a website using Apify's Web Scraper. Build an Actor's page function, extract information from a web page and download your data.
-externalSourceUrl: https://raw.githubusercontent.com/apifytech/actor-scraper/master/docs/build/web-scraper-tutorial.md
+externalSourceUrl: https://raw.githubusercontent.com/apify/actor-scraper/master/docs/build/web-scraper-tutorial.md
sidebar_position: 2
slug: /apify-scrapers/web-scraper
---
-<!-- When changing the TITLE property, make sure to edit the dependent integration test: https://github.com/apifytech/apify-web/blob/develop/tests/e2e/cypress/integration/docs.js so it doesn't break -->
+<!-- When changing the TITLE property, make sure to edit the dependent integration test: https://github.com/apify/apify-web/blob/develop/tests/e2e/cypress/integration/docs.js so it doesn't break -->
[//]: # (TODO: Should be updated)
@@ -20,7 +20,7 @@ because this one builds on topics and code examples discussed there.
## [](#getting-to-know-our-tools) Getting to know our tools
-In the [Getting started with Apify scrapers](https://apify.com/docs/scraping/tutorial/introduction) tutorial,
+In the [Getting started with Apify scrapers](https://docs.apify.com/academy/apify-scrapers/getting-started) tutorial,
we've confirmed that the scraper works as expected, so now it's time to add more data to the results.
To do that, we'll be using the [jQuery library](https://jquery.com/), because it provides some nice tools
@@ -45,14 +45,14 @@ Before we start, let's do a quick recap of the data we chose to scrape:
5. **Last modification date** - When the Actor was last modified.
6. **Number of runs** - How many times the Actor was run.
-
+
We've already scraped numbers 1 and 2 in the [Getting started with Apify scrapers](/academy/apify-scrapers/getting-started)
tutorial, so let's get to the next one on the list: title.
### [](#title) Title
-
+
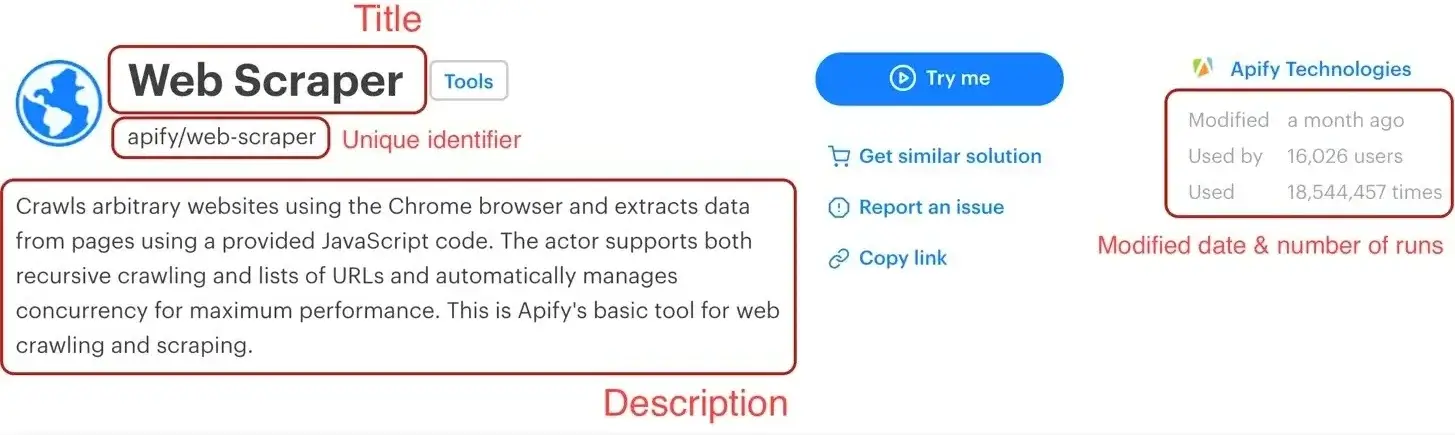
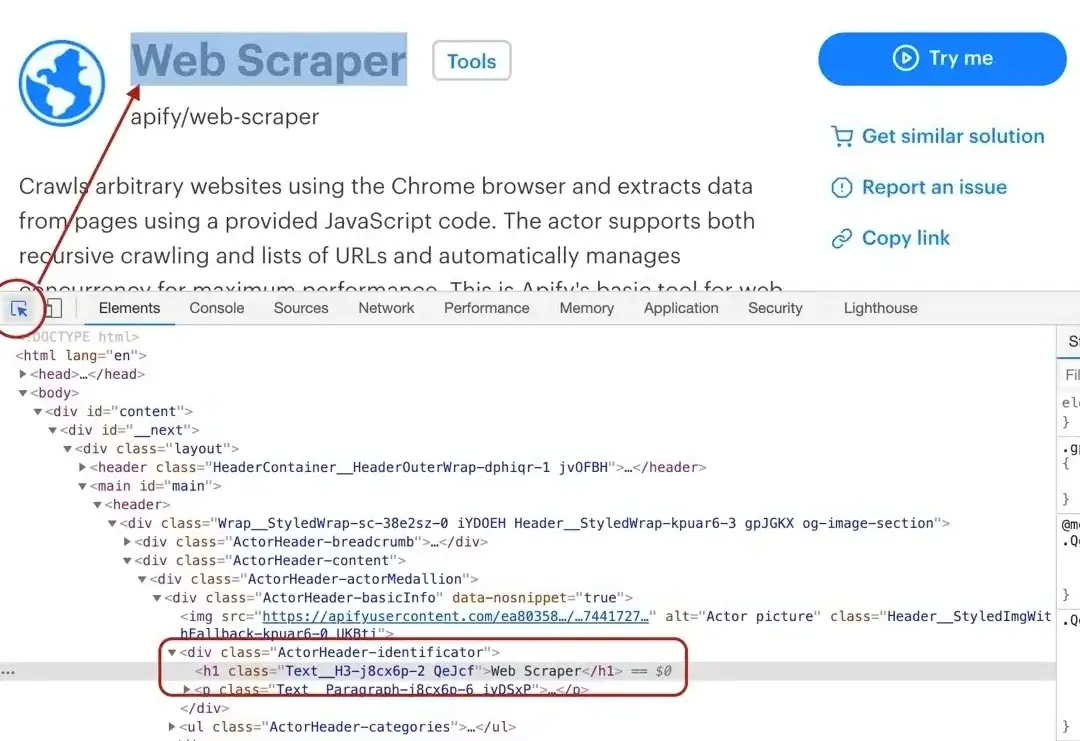
By using the element selector tool, we find out that the title is there under an `<h1>` tag, as titles should be.
Maybe surprisingly, we find that there are actually two `<h1>` tags on the detail page. This should get us thinking.
@@ -83,7 +83,7 @@ async function pageFunction(context) {
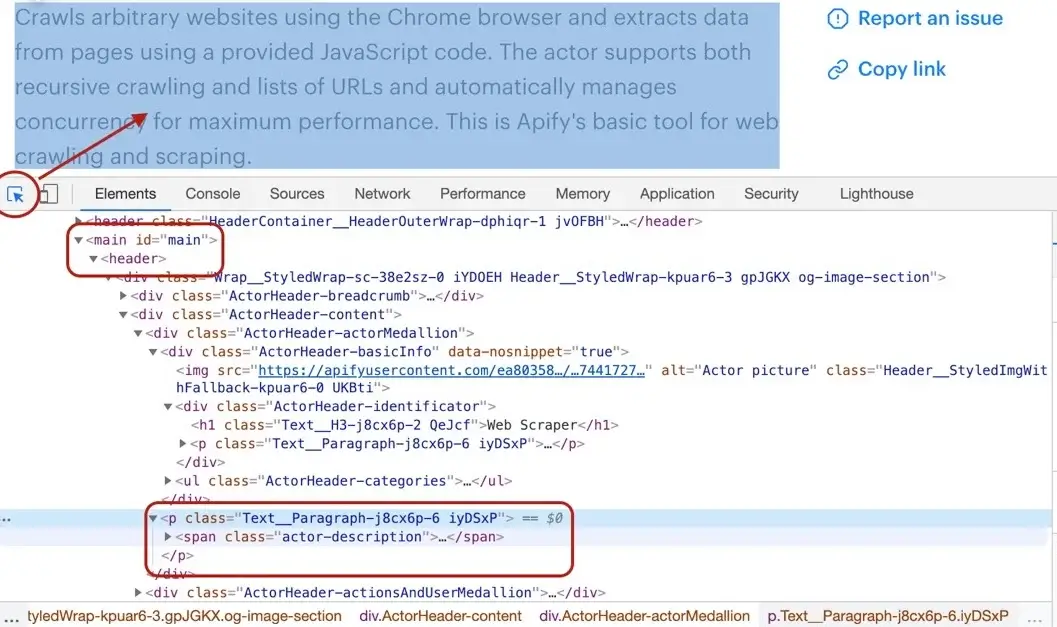
Getting the Actor's description is a little more involved, but still pretty straightforward. We cannot search for a `<p>` tag, because there's a lot of them in the page. We need to narrow our search down a little. Using the DevTools we find that the Actor description is nested within
the `<header>` element too, same as the title. Moreover, the actual description is nested inside a `<span>` tag with a class `actor-description`.
-
+
```js
async function pageFunction(context) {
@@ -101,7 +101,7 @@ async function pageFunction(context) {
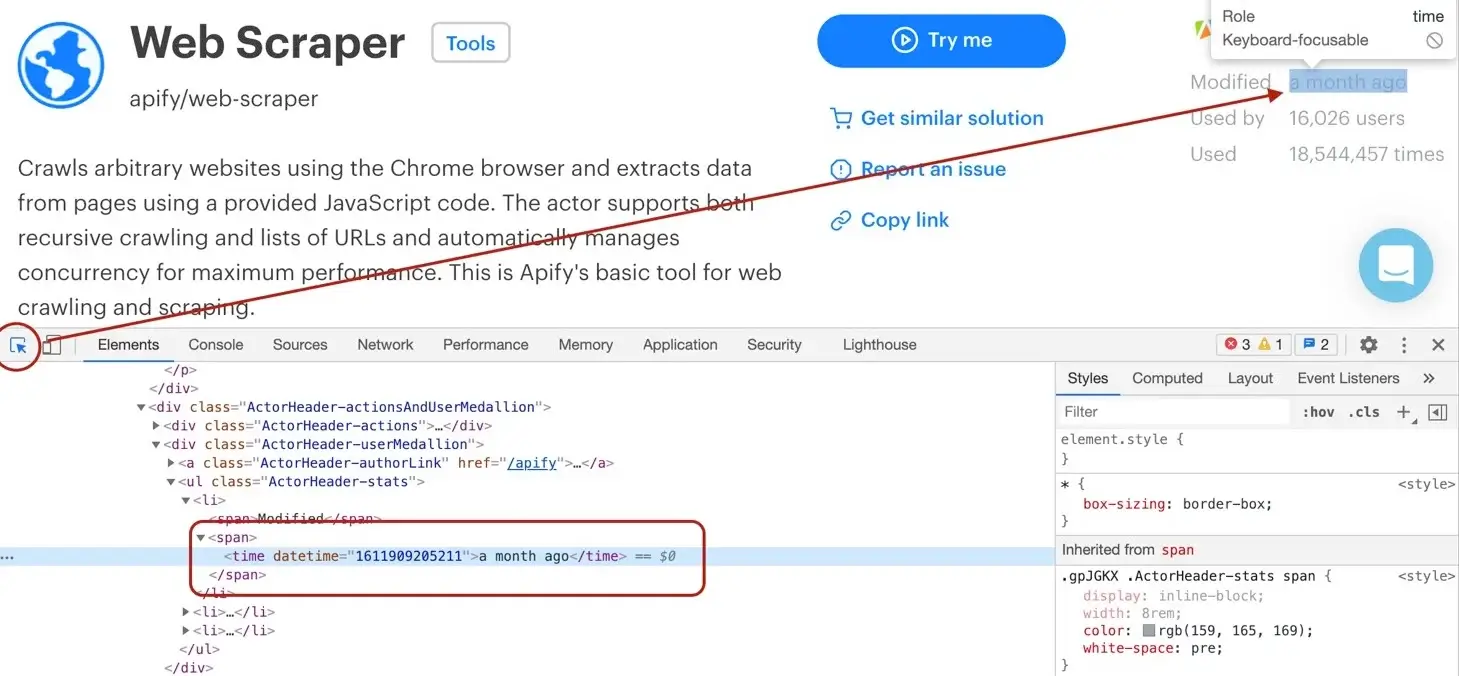
The DevTools tell us that the `modifiedDate` can be found in a `<time>` element.
-
+
```js
async function pageFunction(context) {
@@ -322,7 +322,7 @@ div.show-more > button
> Don't forget to confirm our assumption in the DevTools finder tool (CTRL/CMD + F).
-
+
Now that we know what to wait for, we plug it into the `waitFor()` function.
@@ -455,7 +455,7 @@ through all the Actors and then scrape all of their data. After it succeeds, ope
You've successfully scraped Apify Store. And if not, no worries, go through the code examples again,
it's probably just a typo.
-
+
## [](#downloading-our-scraped-data) Downloading the scraped data
@@ -555,9 +555,9 @@ Thank you for reading this whole tutorial! Really! It's important to us that our
## [](#whats-next) What's next?
-- Check out the [Apify SDK](https://sdk.apify.com/) and its [Getting started](https://sdk.apify.com/docs/guides/getting-started) tutorial if you'd like to try building your own Actors. It's a bit more complex and involved than writing a `pageFunction`, but it allows you to fine-tune all the details of your scraper to your liking.
+- Check out the [Apify SDK](https://docs.apify.com/sdk) and its [Getting started](https://docs.apify.com/sdk/js/docs/guides/apify-platform) tutorial if you'd like to try building your own Actors. It's a bit more complex and involved than writing a `pageFunction`, but it allows you to fine-tune all the details of your scraper to your liking.
- [Take a deep dive into Actors](/platform/actors), from how they work to [publishing](/platform/actors/publishing) them in Apify Store, and even [making money](https://blog.apify.com/make-regular-passive-income-developing-web-automation-actors-b0392278d085/) on Actors.
-- Found out you're not into the coding part but would still to use Apify Actors? Check out our [ready-made solutions](https://apify.com/store) or [order a custom Actor](https://apify.com/custom-solutions) from an Apify-certified developer.
+- Found out you're not into the coding part but would still to use Apify Actors? Check out our [ready-made solutions](https://apify.com/store) or [order a custom Actor](https://apify.com/contact-sales) from an Apify-certified developer.
**Learn how to scrape a website using Apify's Web Scraper. Build an Actor's page function, extract information from a web page and download your data.**
diff --git a/sources/academy/tutorials/node_js/avoid_eacces_error_in_actor_builds.md b/sources/academy/tutorials/node_js/avoid_eacces_error_in_actor_builds.md
index 67dacd567..7c8337064 100644
--- a/sources/academy/tutorials/node_js/avoid_eacces_error_in_actor_builds.md
+++ b/sources/academy/tutorials/node_js/avoid_eacces_error_in_actor_builds.md
@@ -31,6 +31,6 @@ use
COPY --chown=myuser:myuser . ./
```
-where `myuser` is the user and group defined by the `USER` instruction in the base Docker image. To learn more, see [Dockerfile documentation](https://docs.docker.com/engine/reference/builder/#copy).
+where `myuser` is the user and group defined by the `USER` instruction in the base Docker image. To learn more, see [Dockerfile documentation](https://docs.docker.com/reference/dockerfile/#copy).
Hope this helps!
diff --git a/sources/academy/tutorials/node_js/caching_responses_in_puppeteer.md b/sources/academy/tutorials/node_js/caching_responses_in_puppeteer.md
index 0466ad7bd..70b0f2ab0 100644
--- a/sources/academy/tutorials/node_js/caching_responses_in_puppeteer.md
+++ b/sources/academy/tutorials/node_js/caching_responses_in_puppeteer.md
@@ -23,7 +23,7 @@ In this example, we will use a scraper which goes through top stories on the CNN

-As you can see, we used 177MB of traffic for 10 posts (that is how many posts are in the top-stories column) and 1 main page. We also stored all the screenshots, which you can find [here](https://my.apify.com/storage/key-value/q2ipoeLLy265NtSiL).
+As you can see, we used 177MB of traffic for 10 posts (that is how many posts are in the top-stories column) and 1 main page.
From the screenshot above, it's clear that most of the traffic is coming from script files (124MB) and documents (22.8MB). For this kind of situation, it's always good to check if the content of the page is cache-able. You can do that using Chromes Developer tools.
diff --git a/sources/academy/tutorials/node_js/filter_blocked_requests_using_sessions.md b/sources/academy/tutorials/node_js/filter_blocked_requests_using_sessions.md
index 61a869e32..318c66b48 100644
--- a/sources/academy/tutorials/node_js/filter_blocked_requests_using_sessions.md
+++ b/sources/academy/tutorials/node_js/filter_blocked_requests_using_sessions.md
@@ -23,7 +23,7 @@ You want to crawl a website with a proxy pool, but most of your proxies are bloc
Nobody can make sure that a proxy will work infinitely. The only real solution to this problem is to use [residential proxies](/platform/proxy#residential-proxy), but they can sometimes be too costly.
-However, usually, at least some of our proxies work. To crawl successfully, it is therefore imperative to handle blocked requests properly. You first need to discover that you are blocked, which usually means that either your request returned status greater or equal to 400 (it didn't return the proper response) or that the page displayed a captcha. To ensure that this bad request is retried, you usually throw an error and it gets automatically retried later (our [SDK](/sdk/js/) handles this for you). Check out [this article](https://help.apify.com/en/articles/2190650-how-to-handle-blocked-requests-in-puppeteercrawler) as inspiration for how to handle this situation with `PuppeteerCrawler` class.
+However, usually, at least some of our proxies work. To crawl successfully, it is therefore imperative to handle blocked requests properly. You first need to discover that you are blocked, which usually means that either your request returned status greater or equal to 400 (it didn't return the proper response) or that the page displayed a captcha. To ensure that this bad request is retried, you usually throw an error and it gets automatically retried later (our [SDK](/sdk/js/) handles this for you). Check out [this article](https://docs.apify.com/academy/node-js/handle-blocked-requests-puppeteer) as inspiration for how to handle this situation with `PuppeteerCrawler` class.
### Solution
@@ -180,7 +180,7 @@ const gotoFunction = async ({ request, page }) => {
};
```
-Now we have access to the session in the `handlePageFunction` and the rest of the logic is the same as in the first example. We extract the session from the userData, try/catch the whole code and on success we add the session and on error we delete it. Also it is useful to retire the browser completely (check [here](http://kb.apify.com/actor/how-to-handle-blocked-requests-in-puppeteercrawler) for reference) since the other requests will probably have similar problem.
+Now we have access to the session in the `handlePageFunction` and the rest of the logic is the same as in the first example. We extract the session from the userData, try/catch the whole code and on success we add the session and on error we delete it. Also it is useful to retire the browser completely (check [here](https://docs.apify.com/academy/node-js/handle-blocked-requests-puppeteer) for reference) since the other requests will probably have similar problem.
```js
const handlePageFunction = async ({ request, page, puppeteerPool }) => {
diff --git a/sources/academy/tutorials/node_js/handle_blocked_requests_puppeteer.md b/sources/academy/tutorials/node_js/handle_blocked_requests_puppeteer.md
index da2a425b3..66eb7459d 100644
--- a/sources/academy/tutorials/node_js/handle_blocked_requests_puppeteer.md
+++ b/sources/academy/tutorials/node_js/handle_blocked_requests_puppeteer.md
@@ -5,7 +5,7 @@ sidebar_position: 15.9
slug: /node-js/handle-blocked-requests-puppeteer
---
-One of the main defense mechanisms websites use to ensure they are not scraped by bots is allowing only a limited number of requests from a specific IP address. That's why Apify provides a [proxy](https://www.apify.com/docs/proxy) component with intelligent rotation. With a large enough pool of proxies, you can multiply the number of allowed requests per day to cover your crawling needs. Let's look at how we can rotate proxies when using our [JavaScript SDK](https://github.com/apify/apify-sdk-js).
+One of the main defense mechanisms websites use to ensure they are not scraped by bots is allowing only a limited number of requests from a specific IP address. That's why Apify provides a [proxy](https://docs.apify.com/platform/proxy) component with intelligent rotation. With a large enough pool of proxies, you can multiply the number of allowed requests per day to cover your crawling needs. Let's look at how we can rotate proxies when using our [JavaScript SDK](https://github.com/apify/apify-sdk-js).
# BasicCrawler
@@ -54,7 +54,7 @@ const crawler = new PuppeteerCrawler({
});
```
-It is really up to a developer to spot if something is wrong with his request. A website can interfere with your crawling in [many ways](https://kb.apify.com/tips-and-tricks/several-tips-how-to-bypass-website-anti-scraping-protections). Page loading can be cancelled right away, it can timeout, the page can display a captcha, some error or warning message, or the data may be missing or corrupted. The developer can then choose if he will try to handle these problems in the code or focus on receiving the proper data. Either way, if the request went wrong, you should throw a proper error.
+It is really up to a developer to spot if something is wrong with his request. A website can interfere with your crawling in [many ways](https://docs.apify.com/academy/anti-scraping). Page loading can be cancelled right away, it can timeout, the page can display a captcha, some error or warning message, or the data may be missing or corrupted. The developer can then choose if he will try to handle these problems in the code or focus on receiving the proper data. Either way, if the request went wrong, you should throw a proper error.
Now that we know when the request is blocked, we can use the retire() function and continue crawling with a new proxy. Google is one of the most popular websites for scrapers, so let's code a Google search crawler. The two main blocking mechanisms used by Google is either to display their (in)famous 'sorry' captcha or to not load the page at all so we will focus on covering these.
diff --git a/sources/academy/tutorials/node_js/how_to_save_screenshots_puppeteer.md b/sources/academy/tutorials/node_js/how_to_save_screenshots_puppeteer.md
index da90807f5..de23e4371 100644
--- a/sources/academy/tutorials/node_js/how_to_save_screenshots_puppeteer.md
+++ b/sources/academy/tutorials/node_js/how_to_save_screenshots_puppeteer.md
@@ -10,7 +10,7 @@ A good way to debug your puppeteer crawler in Apify Actors is to save a screensh
```js
/**
* Store screen from puppeteer page to Apify key-value store
-* @param page - Instance of puppeteer Page class https://github.com/GoogleChrome/puppeteer/blob/master/docs/api.md#class-page
+* @param page - Instance of puppeteer Page class https://pptr.dev/api/puppeteer.page
* @param [key] - Function stores your screen in Apify key-value store under this key
* @return {Promise<void>}
*/
diff --git a/sources/academy/tutorials/node_js/processing_multiple_pages_web_scraper.md b/sources/academy/tutorials/node_js/processing_multiple_pages_web_scraper.md
index da4612b43..74cd78c33 100644
--- a/sources/academy/tutorials/node_js/processing_multiple_pages_web_scraper.md
+++ b/sources/academy/tutorials/node_js/processing_multiple_pages_web_scraper.md
@@ -43,7 +43,7 @@ async function pageFunction(context) {
}
```
-To set the keywords, we're using the customData scraper parameter. This is useful for smaller data sets, but may not be perfect for bigger ones. For such cases you may want to use something like [Importing a list of URLs from an external source](http://kb.apify.com/integration/importing-a-list-of-urls-from-an-external-source).
+To set the keywords, we're using the customData scraper parameter. This is useful for smaller data sets, but may not be perfect for bigger ones. For such cases you may want to use something like [Importing a list of URLs from an external source](https://docs.apify.com/academy/node-js/scraping-urls-list-from-google-sheets).
Since we're enqueuing the same page more than once, we need to set our own uniqueKey so the page will be added to the queue (by default uniqueKey is set to be the same as the URL). The label for the next page will be "fill-form". We're passing the keyword to the next page in the userData field (this can contain any data).
diff --git a/sources/academy/tutorials/node_js/scraping_from_sitemaps.md b/sources/academy/tutorials/node_js/scraping_from_sitemaps.md
index f8cbdb695..3e4e843f9 100644
--- a/sources/academy/tutorials/node_js/scraping_from_sitemaps.md
+++ b/sources/academy/tutorials/node_js/scraping_from_sitemaps.md
@@ -13,13 +13,13 @@ import Example from '!!raw-loader!roa-loader!./scraping_from_sitemaps.js';
---
-Let's say we want to scrape a database of craft beers ([brewbound.com](https://brewbound.com)) before summer starts. If we are lucky, the website will contain a sitemap at https://www.brewbound.com/sitemap.xml.
+Let's say we want to scrape a database of craft beers ([brewbound.com](https://www.brewbound.com/)) before summer starts. If we are lucky, the website will contain a sitemap at [brewbound.com/sitemap.xml](https://www.brewbound.com/sitemap.xml).
> Check out [Sitemap Sniffer](https://apify.com/vaclavrut/sitemap-sniffer), which can discover sitemaps in hidden locations!
## Analyzing the sitemap {#analyzing-the-sitemap}
-The sitemap is usually located at the path **/sitemap.xml**. It is always worth trying that URL, as it is rarely linked anywhere on the site. It usually contains a list of all pages in [XML format](https://www.w3.org/standards/xml/core).
+The sitemap is usually located at the path **/sitemap.xml**. It is always worth trying that URL, as it is rarely linked anywhere on the site. It usually contains a list of all pages in [XML format](https://en.wikipedia.org/wiki/XML).
```XML
<?xml version="1.0" encoding="UTF-8"?>
diff --git a/sources/academy/tutorials/node_js/scraping_shadow_doms.md b/sources/academy/tutorials/node_js/scraping_shadow_doms.md
index ba702f742..bf45a7683 100644
--- a/sources/academy/tutorials/node_js/scraping_shadow_doms.md
+++ b/sources/academy/tutorials/node_js/scraping_shadow_doms.md
@@ -11,7 +11,7 @@ slug: /node-js/scraping-shadow-doms
---
-Each website is represented by an HTML DOM, a tree-like structure consisting of HTML elements (e.g. paragraphs, images, videos) and text. [Shadow DOM](https://developer.mozilla.org/en-US/docs/Web/Web_Components/Using_shadow_DOM) allows the separate DOM trees to be attached to the main DOM while remaining isolated in terms of CSS inheritance and JavaScript DOM manipulation. The CSS and JavaScript codes of separate shadow DOM components do not clash, but the downside is that you can't access the content from outside.
+Each website is represented by an HTML DOM, a tree-like structure consisting of HTML elements (e.g. paragraphs, images, videos) and text. [Shadow DOM](https://developer.mozilla.org/en-US/docs/Web/API/Web_components/Using_shadow_DOM) allows the separate DOM trees to be attached to the main DOM while remaining isolated in terms of CSS inheritance and JavaScript DOM manipulation. The CSS and JavaScript codes of separate shadow DOM components do not clash, but the downside is that you can't access the content from outside.
Let's take a look at this page [alodokter.com](https://www.alodokter.com/). If you click on the menu and open a Chrome debugger, you will see that the menu tree is attached to the main DOM as shadow DOM under the element `<top-navbar-view id="top-navbar-view">`.
diff --git a/sources/academy/tutorials/node_js/scraping_urls_list_from_google_sheets.md b/sources/academy/tutorials/node_js/scraping_urls_list_from_google_sheets.md
index 2fdadb0fc..fa0c546a7 100644
--- a/sources/academy/tutorials/node_js/scraping_urls_list_from_google_sheets.md
+++ b/sources/academy/tutorials/node_js/scraping_urls_list_from_google_sheets.md
@@ -5,7 +5,7 @@ sidebar_position: 15
slug: /node-js/scraping-urls-list-from-google-sheets
---
-You can export URLs from [Google Sheets](https://www.google.com/sheets/about/) such as [this one](https://docs.google.com/spreadsheets/d/1-2mUcRAiBbCTVA5KcpFdEYWflLMLp9DDU3iJutvES4w) directly into an [Actor](/platform/actors)'s Start URLs field.
+You can export URLs from [Google Sheets](https://workspace.google.com/products/sheets/) such as [this one](https://docs.google.com/spreadsheets/d/1-2mUcRAiBbCTVA5KcpFdEYWflLMLp9DDU3iJutvES4w) directly into an [Actor](/platform/actors)'s Start URLs field.
1. Make sure the spreadsheet has one sheet and a simple structure to help the Actor find the URLs.
diff --git a/sources/academy/tutorials/node_js/submitting_form_with_file_attachment.md b/sources/academy/tutorials/node_js/submitting_form_with_file_attachment.md
index 77d47609e..3977545a9 100644
--- a/sources/academy/tutorials/node_js/submitting_form_with_file_attachment.md
+++ b/sources/academy/tutorials/node_js/submitting_form_with_file_attachment.md
@@ -5,7 +5,7 @@ sidebar_position: 15.5
slug: /node-js/submitting-form-with-file-attachment
---
-When doing web automation with Apify, it can sometimes be necessary to submit an HTML form with a file attachment. This article will cover a situation where the file is publicly accessible (e.g. hosted somewhere) and will use an Apify Actor. If it's impossible to use request-promise, it might be necessary to use [Puppeteer](http://kb.apify.com/actor/submitting-a-form-with-file-attachment-using-puppeteer).
+When doing web automation with Apify, it can sometimes be necessary to submit an HTML form with a file attachment. This article will cover a situation where the file is publicly accessible (e.g. hosted somewhere) and will use an Apify Actor. If it's impossible to use request-promise, it might be necessary to use [Puppeteer](https://docs.apify.com/academy/puppeteer-playwright/common-use-cases/submitting-a-form-with-a-file-attachment).
# Downloading the file to memory
diff --git a/sources/academy/tutorials/node_js/submitting_forms_on_aspx_pages.md b/sources/academy/tutorials/node_js/submitting_forms_on_aspx_pages.md
index 523485ada..344cd7236 100644
--- a/sources/academy/tutorials/node_js/submitting_forms_on_aspx_pages.md
+++ b/sources/academy/tutorials/node_js/submitting_forms_on_aspx_pages.md
@@ -7,7 +7,7 @@ slug: /node-js/submitting-forms-on-aspx-pages
Apify users sometimes need to submit a form on pages created with ASP.NET (URL typically ends with .aspx). These pages have a different approach for how they submit forms and navigate through pages.
-This tutorial shows you how to handle these kinds of pages. This approach is based on a [blog post](http://toddhayton.com/2015/05/04/scraping-aspnet-pages-with-ajax-pagination/) from Todd Hayton, where he explains how crawlers for ASP.NET pages should work.
+This tutorial shows you how to handle these kinds of pages. This approach is based on a [blog post](https://toddhayton.com/2015/05/04/scraping-aspnet-pages-with-ajax-pagination/) from Todd Hayton, where he explains how crawlers for ASP.NET pages should work.
First of all, you need to copy&paste this function to your [Web Scraper](https://apify.com/apify/web-scraper) _Page function_:
diff --git a/sources/academy/tutorials/node_js/using_proxy_to_intercept_requests_puppeteer.md b/sources/academy/tutorials/node_js/using_proxy_to_intercept_requests_puppeteer.md
index af15f9f8e..ad6805f5c 100644
--- a/sources/academy/tutorials/node_js/using_proxy_to_intercept_requests_puppeteer.md
+++ b/sources/academy/tutorials/node_js/using_proxy_to_intercept_requests_puppeteer.md
@@ -42,7 +42,7 @@ const setupProxy = async (port) => {
};
```
-Then we'll need a Docker image that has the `certutil` utility. Here is an [example of a Dockerfile](https://github.com/apifytech/act-proxy-intercept-request/blob/master/Dockerfile) that can create such an image and is based on the [apify/actor-node-chrome](https://hub.docker.com/r/apify/actor-node-chrome/) image that contains Puppeteer.
+Then we'll need a Docker image that has the `certutil` utility. Here is an [example of a Dockerfile](https://github.com/apify/actor-example-proxy-intercept-request/blob/master/Dockerfile) that can create such an image and is based on the [apify/actor-node-chrome](https://hub.docker.com/r/apify/actor-node-chrome/) image that contains Puppeteer.
Now we need to specify how the proxy shall handle the intercepted requests:
@@ -75,7 +75,7 @@ const browser = await puppeteer.launch({
And we're done! By adjusting the `blockRequests` variable, you can allow or block any request initiated through Puppeteer.
-Here is a GitHub repository with a full example and all necessary files: https://github.com/apifytech/actor-example-proxy-intercept-request
+Here is a GitHub repository with a full example and all necessary files: https://github.com/apify/actor-example-proxy-intercept-request
If you have any questions, feel free to contact us in the chat.
diff --git a/sources/academy/webscraping/anti_scraping/index.md b/sources/academy/webscraping/anti_scraping/index.md
index 8d2cfb32f..5afa7e654 100644
--- a/sources/academy/webscraping/anti_scraping/index.md
+++ b/sources/academy/webscraping/anti_scraping/index.md
@@ -33,7 +33,7 @@ In the vast majority of cases, this configuration should lead to success. Succes
If the above tips didn't help, you can try to fiddle with the following:
-- Try different browsers. Crawlee & Playwright support Chromium, Firefox and WebKit out of the box. You can also try the [Brave browser](https://brave.com) which [can be configured for Playwright](https://blog.apify.com/unlocking-the-potential-of-brave-and-playwright-for-browser-automation).
+- Try different browsers. Crawlee & Playwright support Chromium, Firefox and WebKit out of the box. You can also try the [Brave browser](https://brave.com) which [can be configured for Playwright](https://blog.apify.com/unlocking-the-potential-of-brave-and-playwright-for-browser-automation/).
- Don't use browsers at all. Sometimes the anti-scraping protections are extremely sensitive to browser behavior but will allow plain HTTP requests (with the right headers) just fine. Don't forget to match the specific [HTTP headers](/academy/concepts/http-headers) for each request.
- Decrease concurrency. Slower scraping means you can blend in better with the rest of the traffic.
- Add human-like behavior. Don't traverse the website like a bot (paginating quickly from 1 to 100). Instead, visit various types of pages, add time randomizations and you can even introduce some mouse movements and clicks.
@@ -54,7 +54,7 @@ What's up with that?! A website might have a variety of reasons to block bots fr
- To not skew their analytics data with bot traffic.
- If it is a social media website, they might be attempting to keep away bots programmed to mass create fake profiles (which are usually sold later).
-> We recommend checking out [this article about legal and ethical ramifications of web scraping](https://blog.apify.com/is-web-scraping-legal).
+> We recommend checking out [this article about legal and ethical ramifications of web scraping](https://blog.apify.com/is-web-scraping-legal/).
Unfortunately for these websites, they have to make compromises and tradeoffs. While super strong anti-bot protections will surely prevent the majority of bots from accessing their content, there is also a higher chance of regular users being flagged as bots and being blocked as well. Because of this, different sites have different scraping-difficulty levels based on the anti-scraping measures they take.
diff --git a/sources/academy/webscraping/anti_scraping/techniques/geolocation.md b/sources/academy/webscraping/anti_scraping/techniques/geolocation.md
index fe964d1c0..d2603c4ea 100644
--- a/sources/academy/webscraping/anti_scraping/techniques/geolocation.md
+++ b/sources/academy/webscraping/anti_scraping/techniques/geolocation.md
@@ -15,7 +15,7 @@ Geolocation is yet another way websites can detect and block access or show limi
## Cookies & headers {#cookies-headers}
-Certain websites might use certain location-specific/language-specific [headers](../../../glossary/concepts/http_headers.md)/[cookies](../../../glossary/concepts/http_cookies.md) to geolocate a user. Some examples of these headers are `Accept-Language` and `CloudFront-Viewer-Country` (which is a custom HTTP header from [CloudFront](https://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/using-cloudfront-headers.html)).
+Certain websites might use certain location-specific/language-specific [headers](../../../glossary/concepts/http_headers.md)/[cookies](../../../glossary/concepts/http_cookies.md) to geolocate a user. Some examples of these headers are `Accept-Language` and `CloudFront-Viewer-Country` (which is a custom HTTP header from [CloudFront](https://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/adding-cloudfront-headers.html)).
On targets which are utilizing just cookies and headers to identify the location from which a request is coming from, it is pretty straightforward to make requests which appear like they are coming from somewhere else.
diff --git a/sources/academy/webscraping/api_scraping/general_api_scraping/handling_pagination.md b/sources/academy/webscraping/api_scraping/general_api_scraping/handling_pagination.md
index 1f2af83fb..7782b8fad 100644
--- a/sources/academy/webscraping/api_scraping/general_api_scraping/handling_pagination.md
+++ b/sources/academy/webscraping/api_scraping/general_api_scraping/handling_pagination.md
@@ -41,7 +41,7 @@ Becoming more and more common is cursor-based pagination. Like with offset-based
One of the most painful things about scraping APIs with cursor pagination is that you can't skip to, for example, the 5th page. You have to paginate through each page one by one.
-> Note: SoundCloud [migrated](https://developers.soundcloud.com/blog/pagination-updates-on-our-api) over to using cursor-based pagination; however, they did not change the parameter name from **offset** to **cursor**. Always be on the lookout for this type of stuff!
+> Note: SoundCloud [migrated](https://developers.soundcloud.com/blog/pagination-updates-on-our-api/) over to using cursor-based pagination; however, they did not change the parameter name from **offset** to **cursor**. Always be on the lookout for this type of stuff!
## Using "next page" {#using-next-page}
diff --git a/sources/academy/webscraping/api_scraping/graphql_scraping/custom_queries.md b/sources/academy/webscraping/api_scraping/graphql_scraping/custom_queries.md
index a9c2d2e73..16bdd5f8b 100644
--- a/sources/academy/webscraping/api_scraping/graphql_scraping/custom_queries.md
+++ b/sources/academy/webscraping/api_scraping/graphql_scraping/custom_queries.md
@@ -67,7 +67,7 @@ const scrapeAppToken = async () => {
}
});
- await page.goto('https://cheddar.com/');
+ await page.goto('https://www.cheddar.com/');
await page.waitForNetworkIdle();
@@ -302,7 +302,7 @@ const scrapeAppToken = async () => {
}
});
- await page.goto('https://cheddar.com/');
+ await page.goto('https://www.cheddar.com/');
await page.waitForNetworkIdle();
diff --git a/sources/academy/webscraping/api_scraping/graphql_scraping/index.md b/sources/academy/webscraping/api_scraping/graphql_scraping/index.md
index 291a73c93..e3ed00b09 100644
--- a/sources/academy/webscraping/api_scraping/graphql_scraping/index.md
+++ b/sources/academy/webscraping/api_scraping/graphql_scraping/index.md
@@ -15,7 +15,7 @@ slug: /api-scraping/graphql-scraping
## How do I know if it's a GraphQL API? {#graphql-endpoints}
-In this section, we'll be scraping [cheddar.com](https://cheddar.com)'s GraphQL API. When you visit the website and make a search for anything while your **Network Tab** is open, you'll see a request that has been sent to the endpoint **api.cheddar.com/graphql**.
+In this section, we'll be scraping [cheddar.com](https://www.cheddar.com/)'s GraphQL API. When you visit the website and make a search for anything while your **Network Tab** is open, you'll see a request that has been sent to the endpoint **api.cheddar.com/graphql**.

diff --git a/sources/academy/webscraping/api_scraping/graphql_scraping/introspection.md b/sources/academy/webscraping/api_scraping/graphql_scraping/introspection.md
index c6b9e328b..f3016b87a 100644
--- a/sources/academy/webscraping/api_scraping/graphql_scraping/introspection.md
+++ b/sources/academy/webscraping/api_scraping/graphql_scraping/introspection.md
@@ -21,7 +21,7 @@ Not only does becoming comfortable with and understanding the ins and outs of us
! Cheddar website was changed and the below example no longer works there. Nonetheless, the general approach is still viable on some websites even though introspection is disabled on most.
-In order to perform introspection on our [target website](https://cheddar.com), we need to make a request to their GraphQL API with this introspection query using [Insomnia](../../../glossary/tools/insomnia.md) or another HTTP client that supports GraphQL:
+In order to perform introspection on our [target website](https://www.cheddar.com), we need to make a request to their GraphQL API with this introspection query using [Insomnia](../../../glossary/tools/insomnia.md) or another HTTP client that supports GraphQL:
> To make a GraphQL query in Insomnia, make sure you've set the HTTP method to **POST** and the request body type to **GraphQL Query**.
@@ -148,7 +148,7 @@ Now that we have this visualization to work off of, it will be much easier to bu
In future lessons, we'll be building more complex queries using **dynamic variables** and advanced features such as **fragments**; however, for now let's get our feet wet by using the data we have from GraphQL Voyager to build a query.
-Right now, our goal is to fetch the 1000 most recent articles on [Cheddar](https://cheddar.com). From each article, we'd like to fetch the **title** and the **publish date**. After a bit of digging through the schema, we've come across the **media** field within the **organization** type, which has both **title** and **public_at** fields - seems to check out!
+Right now, our goal is to fetch the 1000 most recent articles on [Cheddar](https://www.cheddar.com). From each article, we'd like to fetch the **title** and the **publish date**. After a bit of digging through the schema, we've come across the **media** field within the **organization** type, which has both **title** and **public_at** fields - seems to check out!

diff --git a/sources/academy/webscraping/api_scraping/graphql_scraping/modifying_variables.md b/sources/academy/webscraping/api_scraping/graphql_scraping/modifying_variables.md
index 9e8da6635..8a5dccdd6 100644
--- a/sources/academy/webscraping/api_scraping/graphql_scraping/modifying_variables.md
+++ b/sources/academy/webscraping/api_scraping/graphql_scraping/modifying_variables.md
@@ -11,7 +11,7 @@ slug: /api-scraping/graphql-scraping/modifying-variables
---
-In the introduction of this course, we searched for the term **test** on the [Cheddar](https://cheddar.com) website and discovered a request to their GraphQL API. The payload looked like this:
+In the introduction of this course, we searched for the term **test** on the [Cheddar](https://www.cheddar.com/) website and discovered a request to their GraphQL API. The payload looked like this:
```json
{
diff --git a/sources/academy/webscraping/puppeteer_playwright/common_use_cases/logging_into_a_website.md b/sources/academy/webscraping/puppeteer_playwright/common_use_cases/logging_into_a_website.md
index 004a4a4e8..6cd7ef043 100644
--- a/sources/academy/webscraping/puppeteer_playwright/common_use_cases/logging_into_a_website.md
+++ b/sources/academy/webscraping/puppeteer_playwright/common_use_cases/logging_into_a_website.md
@@ -16,7 +16,7 @@ import TabItem from '@theme/TabItem';
Whether it's auto-renewing a service, automatically sending a message on an interval, or automatically cancelling a Netflix subscription, one of the most popular things headless browsers are used for is automating things within a user's account on a certain website. Of course, automating anything on a user's account requires the automation of the login process as well. In this lesson, we'll be covering how to build a login flow from start to finish with Playwright or Puppeteer.
-> In this lesson, we'll be using [yahoo.com](https://yahoo.com) as an example. Feel free to follow along using the academy Yahoo account credentials, or even deviate from the lesson a bit and try building a login flow for a different website of your choosing!
+> In this lesson, we'll be using [yahoo.com](https://www.yahoo.com/) as an example. Feel free to follow along using the academy Yahoo account credentials, or even deviate from the lesson a bit and try building a login flow for a different website of your choosing!
## Inputting credentials {#inputting-credentials}
diff --git a/sources/academy/webscraping/puppeteer_playwright/common_use_cases/submitting_a_form_with_a_file_attachment.md b/sources/academy/webscraping/puppeteer_playwright/common_use_cases/submitting_a_form_with_a_file_attachment.md
index 1bb718d01..ce4f73308 100644
--- a/sources/academy/webscraping/puppeteer_playwright/common_use_cases/submitting_a_form_with_a_file_attachment.md
+++ b/sources/academy/webscraping/puppeteer_playwright/common_use_cases/submitting_a_form_with_a_file_attachment.md
@@ -63,7 +63,7 @@ await page.type('input[name=surname]', 'Doe');
await page.type('input[name=email]', 'john.doe@example.com');
```
-To add the file to the appropriate input, we first need to find it and then use the [`uploadFile()`](https://pptr.dev/next/api/puppeteer.elementhandle.uploadfile) function.
+To add the file to the appropriate input, we first need to find it and then use the [`uploadFile()`](https://pptr.dev/api/puppeteer.elementhandle.uploadfile) function.
```js
const fileInput = await page.$('input[type=file]');
diff --git a/sources/academy/webscraping/puppeteer_playwright/executing_scripts/index.md b/sources/academy/webscraping/puppeteer_playwright/executing_scripts/index.md
index 9ea82ab37..e8e08e254 100644
--- a/sources/academy/webscraping/puppeteer_playwright/executing_scripts/index.md
+++ b/sources/academy/webscraping/puppeteer_playwright/executing_scripts/index.md
@@ -28,7 +28,7 @@ const browser = await chromium.launch({ headless: false });
const page = await browser.newPage();
// visit google
-await page.goto('https://google.com/');
+await page.goto('https://www.google.com/');
// change background to green
document.body.style.background = 'green';
@@ -59,7 +59,7 @@ import { chromium } from 'playwright';
const browser = await chromium.launch({ headless: false });
const page = await browser.newPage();
-await page.goto('https://google.com/');
+await page.goto('https://www.google.com/');
await page.evaluate(() => {
document.body.style.background = 'green';
@@ -79,7 +79,7 @@ import puppeteer from 'puppeteer';
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
-await page.goto('https://google.com/');
+await page.goto('https://www.google.com/');
await page.evaluate(() => {
document.body.style.background = 'green';
@@ -116,7 +116,7 @@ import { chromium } from 'playwright';
const browser = await chromium.launch({ headless: false });
const page = await browser.newPage();
-await page.goto('https://google.com/');
+await page.goto('https://www.google.com/');
const params = { randomString: Math.random().toString(36).slice(2) };
@@ -138,7 +138,7 @@ import puppeteer from 'puppeteer';
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
-await page.goto('https://google.com/');
+await page.goto('https://www.google.com/');
const params = { randomString: Math.random().toString(36).slice(2) };
diff --git a/sources/academy/webscraping/puppeteer_playwright/page/interacting_with_a_page.md b/sources/academy/webscraping/puppeteer_playwright/page/interacting_with_a_page.md
index a3564ef27..db20f04a9 100644
--- a/sources/academy/webscraping/puppeteer_playwright/page/interacting_with_a_page.md
+++ b/sources/academy/webscraping/puppeteer_playwright/page/interacting_with_a_page.md
@@ -83,7 +83,7 @@ const browser = await chromium.launch({ headless: false });
const page = await browser.newPage();
-await page.goto('https://google.com/');
+await page.goto('https://www.google.com/');
// Click the "I agree" button
await page.click('button:has-text("Accept all")');
@@ -108,7 +108,7 @@ const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
-await page.goto('https://google.com/');
+await page.goto('https://www.google.com/');
// Click the "I agree" button
await page.click('button + button');
@@ -142,7 +142,7 @@ const browser = await chromium.launch({ headless: false });
const page = await browser.newPage();
-await page.goto('https://google.com/');
+await page.goto('https://www.google.com/');
await page.click('button:has-text("Accept all")');
@@ -168,7 +168,7 @@ const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
-await page.goto('https://google.com/');
+await page.goto('https://www.google.com/');
await page.click('button + button');
diff --git a/sources/academy/webscraping/puppeteer_playwright/page/waiting.md b/sources/academy/webscraping/puppeteer_playwright/page/waiting.md
index a47697d48..abfc1af57 100644
--- a/sources/academy/webscraping/puppeteer_playwright/page/waiting.md
+++ b/sources/academy/webscraping/puppeteer_playwright/page/waiting.md
@@ -35,7 +35,7 @@ import puppeteer from 'puppeteer';
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
-await page.goto('https://google.com/');
+await page.goto('https://www.google.com/');
await page.click('button + button');
diff --git a/sources/academy/webscraping/scraping_basics_javascript/challenge/index.md b/sources/academy/webscraping/scraping_basics_javascript/challenge/index.md
index 0db3f48a1..4a347ea3d 100644
--- a/sources/academy/webscraping/scraping_basics_javascript/challenge/index.md
+++ b/sources/academy/webscraping/scraping_basics_javascript/challenge/index.md
@@ -20,7 +20,7 @@ We recommend that you make sure you've gone through both the [data extraction](.
Before continuing, it is highly recommended to do the following:
- Look over [how to build a crawler in Crawlee](https://crawlee.dev/docs/introduction/first-crawler) and ideally **code along**.
-- Read [this short article](https://help.apify.com/en/articles/1829103-request-labels-and-how-to-pass-data-to-other-requests) about [**request labels**](https://crawlee.dev/api/core/class/Request#label) (this will be extremely useful later on).
+- Read [this short article](https://docs.apify.com/academy/node-js/request-labels-in-apify-actors) about [**request labels**](https://crawlee.dev/api/core/class/Request#label) (this will be extremely useful later on).
- Check out [this tutorial](../../../tutorials/node_js/dealing_with_dynamic_pages.md) about dynamic pages.
- Read about the [RequestQueue](https://crawlee.dev/api/core/class/RequestQueue).
diff --git a/sources/academy/webscraping/scraping_basics_javascript/challenge/scraping_amazon.md b/sources/academy/webscraping/scraping_basics_javascript/challenge/scraping_amazon.md
index de17ebc4f..ec407acf8 100644
--- a/sources/academy/webscraping/scraping_basics_javascript/challenge/scraping_amazon.md
+++ b/sources/academy/webscraping/scraping_basics_javascript/challenge/scraping_amazon.md
@@ -40,7 +40,7 @@ After clicking this button and checking back in Proxyman, we discovered this lin
https://www.amazon.com/gp/aod/ajax/ref=auto_load_aod?asin=B07ZPKBL9V&pc=dp
```
-The `asin` [query parameter](https://branch.io/glossary/query-parameters/) matches up with our product's ASIN, which means we can use this for any product of which we have the ASIN.
+The `asin` [query parameter](https://www.branch.io/glossary/query-parameters/) matches up with our product's ASIN, which means we can use this for any product of which we have the ASIN.
Here's what this page looks like:
diff --git a/sources/academy/webscraping/scraping_basics_javascript/data_extraction/browser_devtools.md b/sources/academy/webscraping/scraping_basics_javascript/data_extraction/browser_devtools.md
index 76f13dc62..39b8b08a6 100644
--- a/sources/academy/webscraping/scraping_basics_javascript/data_extraction/browser_devtools.md
+++ b/sources/academy/webscraping/scraping_basics_javascript/data_extraction/browser_devtools.md
@@ -11,7 +11,7 @@ slug: /web-scraping-for-beginners/data-extraction/browser-devtools
Even though DevTools stands for developer tools, everyone can use them to inspect a website. Each major browser has its own DevTools. We will use Chrome DevTools as an example, but the advice is applicable to any browser, as the tools are extremely similar. To open Chrome DevTools, you can press **F12** or right-click anywhere in the page and choose **Inspect**.
-Now go to [Wikipedia](https://wikipedia.com) and open your DevTools there. Inspecting the same website as us will make this lesson easier to follow.
+Now go to [Wikipedia](https://www.wikipedia.org/) and open your DevTools there. Inspecting the same website as us will make this lesson easier to follow.

diff --git a/sources/academy/webscraping/typescript/watch_mode_and_tsconfig.md b/sources/academy/webscraping/typescript/watch_mode_and_tsconfig.md
index 9cb6049ed..b3ceaee77 100644
--- a/sources/academy/webscraping/typescript/watch_mode_and_tsconfig.md
+++ b/sources/academy/webscraping/typescript/watch_mode_and_tsconfig.md
@@ -225,7 +225,7 @@ By default TypeScript will allow us to use things like `document.querySelector()
}
```
-> Learn more about the **lib** configuration option [in the TypeScript documentation](https://www.typescriptlang.org/tsconfig#lib).
+> Learn more about the **lib** configuration option [in the TypeScript documentation](https://www.typescriptlang.org/tsconfig/#lib).
#### Removing comments {#removing-comments}
diff --git a/sources/legal/latest/policies/gdpr-information.md b/sources/legal/latest/policies/gdpr-information.md
index 031476385..05688a1da 100644
--- a/sources/legal/latest/policies/gdpr-information.md
+++ b/sources/legal/latest/policies/gdpr-information.md
@@ -48,7 +48,7 @@ First and foremost, we process data that is necessary for us to perform our cont
6. **Right to object:** you have the right to object to the processing of personal data which are processed for the purpose of protecting our legitimate interests or for the purpose of fulfilling a task performed in the public interest or in the exercise of public power. If Apify does not prove that there is a justified legitimate reason for the processing which overrides your interest or rights and freedoms, we shall terminate the processing on the basis of the objection without an undue delay.
-7. **Right to file a complaint:** you can file a complaint with the Office for Personal Data Protection if you claim that processing of data has violated your right to personal data protection during their processing or related legislation, including violating the above-mentioned rights. The Office for Personal Data Protection is located at the address Pplk. Sochora 27, 170 00 Prague 7. More information about its activities is available on the website https://www.uoou.cz/.
+7. **Right to file a complaint:** you can file a complaint with the Office for Personal Data Protection if you claim that processing of data has violated your right to personal data protection during their processing or related legislation, including violating the above-mentioned rights. The Office for Personal Data Protection is located at the address Pplk. Sochora 27, 170 00 Prague 7. More information about its activities is available on the website https://uoou.gov.cz/.
As the controller for your personal data, Apify is committed to respecting all your rights under the GDPR. If you have any questions or feedback, please reach out to us by email at [legal@apify.com](mailto:legal@apify.com).
diff --git a/sources/platform/actors/development/actor_definition/docker.md b/sources/platform/actors/development/actor_definition/docker.md
index 1f1e1611a..ae80ac4a6 100644
--- a/sources/platform/actors/development/actor_definition/docker.md
+++ b/sources/platform/actors/development/actor_definition/docker.md
@@ -47,7 +47,7 @@ These images come with Python (version `3.8`, `3.9`, `3.10`, `3.11`, or `3.12`)
| ----- | ----------- |
| [`actor-python`](https://hub.docker.com/r/apify/actor-python) | Slim Debian image with only the Apify SDK for Python. Does not include headless browsers. |
| [`actor-python-playwright`](https://hub.docker.com/r/apify/actor-python-playwright) | Debian image with [`playwright`](https://github.com/microsoft/playwright) and all its browsers. |
-| [`actor-python-selenium`](https://hub.docker.com/r/apify/actor-python-selenium) | Debian image with [`selenium`](https://github.com/seleniumhq/selenium), Google Chrome, and [ChromeDriver](https://chromedriver.chromium.org/). |
+| [`actor-python-selenium`](https://hub.docker.com/r/apify/actor-python-selenium) | Debian image with [`selenium`](https://github.com/seleniumhq/selenium), Google Chrome, and [ChromeDriver](https://developer.chrome.com/docs/chromedriver/). |
## Custom Dockerfile
@@ -77,7 +77,7 @@ RUN npm --quiet set progress=false \
COPY . ./
```
-For more information about `Dockerfile` syntax and commands, see the [Dockerfile reference](https://docs.docker.com/engine/reference/builder/).
+For more information about `Dockerfile` syntax and commands, see the [Dockerfile reference](https://docs.docker.com/reference/dockerfile/).
:::note Custom base images
diff --git a/sources/platform/actors/development/actor_definition/input_schema/specification.md b/sources/platform/actors/development/actor_definition/input_schema/specification.md
index 329964d83..7215ab95f 100644
--- a/sources/platform/actors/development/actor_definition/input_schema/specification.md
+++ b/sources/platform/actors/development/actor_definition/input_schema/specification.md
@@ -28,7 +28,7 @@ The max allowed size for the input schema file is 100 kB. When you provide an in
:::note Validation aid
-You can also use our [visual input schema editor](https://apify.github.io/input-schema-editor-react) to guide you through the creation of the `INPUT_SCHEMA.json` file.
+You can also use our [visual input schema editor](https://apify.github.io/input-schema-editor-react/) to guide you through the creation of the `INPUT_SCHEMA.json` file.
If you need to validate your input schemas, you can use the [`apify validate-schema`](/cli/docs/reference#apify-validate-schema-path) command in the Apify CLI.
:::
diff --git a/sources/platform/actors/development/builds_and_runs/builds.md b/sources/platform/actors/development/builds_and_runs/builds.md
index 3dc22a34a..5d90bcb93 100644
--- a/sources/platform/actors/development/builds_and_runs/builds.md
+++ b/sources/platform/actors/development/builds_and_runs/builds.md
@@ -19,7 +19,7 @@ By default, the build has a timeout of 300 seconds and consumes 4096 MB (2048 MB
## [](#versioning)Versioning
-In order to enable active development, the Actor can have multiple versions of the source code and associated settings, such as the **Base image** and **Environment**. Each version is denoted by a version number of the form `MAJOR.MINOR`; the version numbers should adhere to the [Semantic Versioning](http://semver.org/) logic.
+In order to enable active development, the Actor can have multiple versions of the source code and associated settings, such as the **Base image** and **Environment**. Each version is denoted by a version number of the form `MAJOR.MINOR`; the version numbers should adhere to the [Semantic Versioning](https://semver.org/) logic.
For example, the Actor can have a production version **1.1**, a beta version **1.2** that contains new features but is still backward compatible, and a development version **2.0** that contains breaking changes.
diff --git a/sources/platform/actors/development/builds_and_runs/runs.md b/sources/platform/actors/development/builds_and_runs/runs.md
index 8088525ae..ff52cd23b 100644
--- a/sources/platform/actors/development/builds_and_runs/runs.md
+++ b/sources/platform/actors/development/builds_and_runs/runs.md
@@ -13,7 +13,7 @@ When you start an Actor, it creates a run. The run is a single execution of your
You can start an Actor in multiple ways:
-1. Manually from the [Apify Console](https://my.apify.com/actors) UI.
+1. Manually from the [Apify Console](https://console.apify.com/actors) UI.
2. Via [Apify API](https://docs.apify.com/api/v2#/reference/actors/run-collection/run-actor).
3. Using [Scheduler](../../../schedules.md) provided by the Apify platform.
4. By one of the available [integrations](../../../integrations/index.mdx).
diff --git a/sources/platform/actors/development/deployment/continuous_integration.md b/sources/platform/actors/development/deployment/continuous_integration.md
index 7213c12ea..85bbe723c 100644
--- a/sources/platform/actors/development/deployment/continuous_integration.md
+++ b/sources/platform/actors/development/deployment/continuous_integration.md
@@ -16,14 +16,16 @@ import TabItem from '@theme/TabItem';
Automating your Actor development process can save time and reduce errors, especially for projects with multiple Actors or frequent updates. Instead of manually pushing code, building Actors, and running tests, you can automate these steps to run whenever you push code to your repository.
-This guide focuses on using GitHub Actions for continuous integration, but [we also have a guide for Bitbucket](https://help.apify.com/en/articles/1861038-setting-up-continuous-integration-for-apify-actors-on-bitbucket).
+You can automate Actor builds and tests using your Git repository's automated workflows like [GitHub Actions](https://github.com/features/actions) or [Bitbucket Pipelines](https://www.atlassian.com/software/bitbucket/features/pipelines).
+
+This article focuses on GitHub, but [we also have a guide for Bitbucket](https://help.apify.com/en/articles/6988586-setting-up-continuous-integration-for-apify-actors-on-bitbucket).
## Set up automated builds and tests
To set up automated builds and tests for your Actors you need to:
1. Create a GitHub repository for your Actor code.
-1. Get your Apify API token from the [Apify Console](https://console.apify.com/account#/integrations)
+1. Get your Apify API token from the [Apify Console](https://console.apify.com/settings/integrations)

diff --git a/sources/platform/actors/development/programming_interface/metamorph.md b/sources/platform/actors/development/programming_interface/metamorph.md
index e58de3464..245287cfb 100644
--- a/sources/platform/actors/development/programming_interface/metamorph.md
+++ b/sources/platform/actors/development/programming_interface/metamorph.md
@@ -47,11 +47,10 @@ Let's walk through an example of using metamorph to create a hotel review scrape
1. Create an Actor that accepts a hotel URL as input.
-1. Use the [apify/web-scraper](https://www.apify.com/apify/web-scraper) Actor to scrape reviews.
+1. Use the [apify/web-scraper](https://apify.com/apify/web-scraper) Actor to scrape reviews.
1. Use the metamorph operation to transform into a run of apify/web-scraper.
-
<Tabs groupId="main">
<TabItem value="JavaScript" label="JavaScript">
diff --git a/sources/platform/actors/publishing/index.mdx b/sources/platform/actors/publishing/index.mdx
index bc7a37b99..5c128d4d8 100644
--- a/sources/platform/actors/publishing/index.mdx
+++ b/sources/platform/actors/publishing/index.mdx
@@ -40,4 +40,4 @@ Ensure periodic testing. You can either do it yourself or [set up automatic test
To come up with ideas for new Actors, you can use your own experience with friends, colleagues, and customers. Alternatively, you can use SEO tools that might help you find the right search terms, websites related to web scraping, web automation, or web integrations. See the [SEO article](../../academy/get-most-of-actors/seo-and-promotion) for more details. Finally, you may take a look at our [Actor ideas page](https://apify.com/ideas) to find out which Actors are most in demand by the Apify community.
-To better understand the context and practical usage of public Actors, [check out our blog](https://blog.apify.com/). Get familiar with how we think and write about Actors, e.g. [Content Checker](https://blog.apify.com/how-to-set-up-a-content-change-watchdog-for-any-website-in-5-minutes-460843b12271) (short), [Kickstarter scraper](https://blog.apify.com/kickstarter-search-actor-create-your-own-kickstarter-api-7672acdb8d77) (mid-size), and [Google Sheets Actor](https://blog.apify.com/import-data-easily-to-and-from-google-sheets-with-a-new-apify-actor-43536b719029) (long one).
+To better understand the context and practical usage of public Actors, [check out our blog](https://blog.apify.com/). Get familiar with how we think and write about Actors, e.g. [Content Checker](https://blog.apify.com/set-up-alert-when-webpage-changes/) (short), [Kickstarter scraper](https://blog.apify.com/kickstarter-search-actor-create-your-own-kickstarter-api/) (mid-size), and [Google Sheets Actor](https://blog.apify.com/google-sheets-import-data/) (long one).
diff --git a/sources/platform/actors/running/store.md b/sources/platform/actors/running/store.md
index 2ed2751b0..232950ba7 100644
--- a/sources/platform/actors/running/store.md
+++ b/sources/platform/actors/running/store.md
@@ -47,7 +47,7 @@ Yes, when you are renting an Actor, you can run it using either our [API](/api/v
##### Do I pay platform costs for running rental Actors?
-Yes, you will pay normal [platform usage costs](https://apify.com/pricing/actors) on top of the monthly Actor rental fee. The platform costs work exactly the same way as for free public Actors or your private Actors. You should find estimates of the cost of usage in each individual rental Actor's README ([see an example](https://apify.com/drobnikj/crawler-google-places#how-much-will-it-cost)).
+Yes, you will pay normal [platform usage costs](https://apify.com/pricing) on top of the monthly Actor rental fee. The platform costs work exactly the same way as for free public Actors or your private Actors. You should find estimates of the cost of usage in each individual rental Actor's README ([see an example](https://apify.com/compass/crawler-google-places#how-much-will-it-cost)).
##### Do I need an Apify paid plan to use rental Actors?
diff --git a/sources/platform/actors/running/usage_and_resources.md b/sources/platform/actors/running/usage_and_resources.md
index acf78b756..84c1664ec 100644
--- a/sources/platform/actors/running/usage_and_resources.md
+++ b/sources/platform/actors/running/usage_and_resources.md
@@ -13,7 +13,7 @@ slug: /actors/running/usage-and-resources
## Resources
-[Actors](../index.mdx) run in [Docker containers](https://www.docker.com/resources/what-container), which have a [limited amount of resources](https://phoenixnap.com/kb/docker-memory-and-cpu-limit) (memory, CPU, disk size, etc). When starting, the Actor needs to be allocated a certain share of those resources, such as CPU capacity that is necessary for the Actor to run.
+[Actors](../index.mdx) run in [Docker containers](https://www.docker.com/resources/what-container/), which have a [limited amount of resources](https://phoenixnap.com/kb/docker-memory-and-cpu-limit) (memory, CPU, disk size, etc). When starting, the Actor needs to be allocated a certain share of those resources, such as CPU capacity that is necessary for the Actor to run.

@@ -80,7 +80,7 @@ Check out our article on [estimating consumption](https://help.apify.com/en/arti
Each use case has its own memory requirements. The larger and more complex your project, the more memory/CPU power it will require. Some examples which have minimum requirements are:
- Actors using [Puppeteer](https://pptr.dev/) or [Playwright](https://playwright.dev/) for real web browser rendering require at least `1024MB` of memory.
-- Large and complex sites like [Google Maps](https://apify.com/drobnikj/crawler-google-places) require at least `4096MB` for optimal speed and [concurrency](https://crawlee.dev/api/core/class/AutoscaledPool#minConcurrency).
+- Large and complex sites like [Google Maps](https://apify.com/compass/crawler-google-places) require at least `4096MB` for optimal speed and [concurrency](https://crawlee.dev/api/core/class/AutoscaledPool#minConcurrency).
- Projects involving large amount of data in memory.
### Maximum memory
@@ -121,13 +121,13 @@ This should be used for informational purposes only.
:::
-For detailed information, FAQ, and, pricing check out the [platform pricing page](https://apify.com/pricing/actors).
+For detailed information, FAQ, and, pricing check out the [platform pricing page](https://apify.com/pricing).
### What is a compute unit
A compute unit (CU) is the unit of measurement for the resources consumed by Actor runs and builds. You are charged for using Actors based on CU consumption.
-For example, running an Actor with`1024MB` of allocated memory for 1 hour will consume 1 CU. The cost of this CU depends on your [subscription plan](https://apify.com/pricing/actors#how-does-the-platform-pricing-work).
+For example, running an Actor with`1024MB` of allocated memory for 1 hour will consume 1 CU. The cost of this CU depends on your subscription plan.
You can check each Actor run's exact CU usage in the run's details.
diff --git a/sources/platform/collaboration/access_rights.md b/sources/platform/collaboration/access_rights.md
index 10494d3bf..c794d5ed6 100644
--- a/sources/platform/collaboration/access_rights.md
+++ b/sources/platform/collaboration/access_rights.md
@@ -10,7 +10,7 @@ slug: /collaboration/access-rights
---
-You can easily and securely share your own resources - Actors, tasks, key-value stores, datasets, and request queues - with other users by using a [granular](https://www.google.com/search?client=firefox-b-d&q=define+granular+permissions) permissions system. This enables you, for example, to let your colleague run an [Actor](../actors/index.mdx) or view a [dataset](../storage/dataset.md) but not modify it.
+You can easily and securely share your own resources - Actors, tasks, key-value stores, datasets, and request queues - with other users by using a [granular](https://www.google.com/search?q=define+granular+permissions) permissions system. This enables you, for example, to let your colleague run an [Actor](../actors/index.mdx) or view a [dataset](../storage/dataset.md) but not modify it.
> To be able to grant access rights to another user, you must have a **username** set in [account settings](https://console.apify.com/account?tab=settings).
diff --git a/sources/platform/console/two-factor-authentication.md b/sources/platform/console/two-factor-authentication.md
index 7e412b5bd..aa70d6c94 100644
--- a/sources/platform/console/two-factor-authentication.md
+++ b/sources/platform/console/two-factor-authentication.md
@@ -24,7 +24,7 @@ If it's not enabled, click on the **Enable** button. You should see the two-fact

-In this view, you can use your favorite authenticator app to scan the QR code. We recommend using Google Authenticator ([Google Play Store](https://play.google.com/store/apps/details?id=com.google.android.apps.authenticator2&hl=en_US)/[Apple App Store](https://apps.apple.com/us/app/google-authenticator/id388497605)) or [Authy](https://authy.com/)([Google Play Store](https://play.google.com/store/apps/details?id=com.authy.authy)/[Apple App Store](https://itunes.apple.com/us/app/authy/id494168017) but any other authenticator app should work as well.
+In this view, you can use your favorite authenticator app to scan the QR code. We recommend using Google Authenticator ([Google Play Store](https://play.google.com/store/apps/details?id=com.google.android.apps.authenticator2&hl=en_US)/[Apple App Store](https://apps.apple.com/us/app/google-authenticator/id388497605)) or [Authy](https://authy.com/)([Google Play Store](https://play.google.com/store/apps/details?id=com.authy.authy)/[Apple App Store](https://apps.apple.com/us/app/twilio-authy/id494168017) but any other authenticator app should work as well.
You can also set up your app/browser extension manually without the QR code. To do that, click on the **Setup key** link below the QR code. This view with the key will pop up:
diff --git a/sources/platform/integrations/ai/flowise.md b/sources/platform/integrations/ai/flowise.md
index cbbfc5167..9c80b3ff9 100644
--- a/sources/platform/integrations/ai/flowise.md
+++ b/sources/platform/integrations/ai/flowise.md
@@ -50,7 +50,7 @@ Now you need to configure the crawler. You can find more information about the c

-In the configuration, provide your Apify API token, which you can find in your [Apify account](https://my.apify.com/account#/integrations).
+In the configuration, provide your Apify API token, which you can find in your [Apify account](https://console.apify.com/settings/integrations).

diff --git a/sources/platform/integrations/ai/langchain.md b/sources/platform/integrations/ai/langchain.md
index fc95947ec..90cd5131c 100644
--- a/sources/platform/integrations/ai/langchain.md
+++ b/sources/platform/integrations/ai/langchain.md
@@ -45,7 +45,7 @@ os.environ["APIFY_API_TOKEN"] = "Your Apify API token"
Run the Actor, wait for it to finish, and fetch its results from the Apify dataset into a LangChain document loader.
-Note that if you already have some results in an Apify dataset, you can load them directly using `ApifyDatasetLoader`, as shown in [this notebook](https://github.com/hwchase17/langchain/blob/fe1eb8ca5f57fcd7c566adfc01fa1266349b72f3/docs/modules/indexes/document_loaders/examples/apify_dataset.ipynb). In that notebook, you'll also find the explanation of the `dataset_mapping_function`, which is used to map fields from the Apify dataset records to LangChain `Document` fields.
+Note that if you already have some results in an Apify dataset, you can load them directly using `ApifyDatasetLoader`, as shown in [this notebook](https://github.com/langchain-ai/langchain/blob/fe1eb8ca5f57fcd7c566adfc01fa1266349b72f3/docs/modules/indexes/document_loaders/examples/apify_dataset.ipynb). In that notebook, you'll also find the explanation of the `dataset_mapping_function`, which is used to map fields from the Apify dataset records to LangChain `Document` fields.
```python
apify = ApifyWrapper()
diff --git a/sources/platform/integrations/ai/pinecone.md b/sources/platform/integrations/ai/pinecone.md
index 5f3542bb3..49ab00666 100644
--- a/sources/platform/integrations/ai/pinecone.md
+++ b/sources/platform/integrations/ai/pinecone.md
@@ -12,7 +12,7 @@ toc_max_heading_level: 4
---
-[Pinecone](https://pinecone.io) is a managed vector database that allows users to store and query dense vectors for AI applications such as recommendation systems, semantic search, and retrieval augmented generation (RAG).
+[Pinecone](https://www.pinecone.io) is a managed vector database that allows users to store and query dense vectors for AI applications such as recommendation systems, semantic search, and retrieval augmented generation (RAG).
The Apify integration for Pinecone enables you to export results from Apify Actors and Dataset items into a specific Pinecone vector index.
diff --git a/sources/platform/integrations/index.mdx b/sources/platform/integrations/index.mdx
index 987b384cd..4b8b04d49 100644
--- a/sources/platform/integrations/index.mdx
+++ b/sources/platform/integrations/index.mdx
@@ -139,7 +139,7 @@ The Apify platform integrates with popular ETL and data pipeline services, enabl
/>
<Card
title="Airbyte"
- to="https://docs.airbyte.io/integrations/sources/apify-dataset"
+ to="https://docs.airbyte.com/integrations/sources/apify-dataset"
imageUrl="/img/platform/integrations/airbyte.svg"
smallImage
/>
diff --git a/sources/platform/integrations/integrate_with_apify.md b/sources/platform/integrations/integrate_with_apify.md
index b1d417108..a250b75fa 100644
--- a/sources/platform/integrations/integrate_with_apify.md
+++ b/sources/platform/integrations/integrate_with_apify.md
@@ -18,7 +18,7 @@ and many more that you can see at [integrations](./index.mdx).
To integrate your service with Apify, you have two options. You can either:
-- build an [Apify Actor](https://apify.com/docs/actor) that will be used as integration within the [Apify Console](https://console.apify.com)
+- build an [Apify Actor](https://docs.apify.com/platform/actors) that will be used as integration within the [Apify Console](https://console.apify.com)
- build an external integration, such as [Zapier](./workflows-and-notifications/zapier.md).

diff --git a/sources/platform/integrations/workflows-and-notifications/make.md b/sources/platform/integrations/workflows-and-notifications/make.md
index 5b99a4ef2..a57aedcd9 100644
--- a/sources/platform/integrations/workflows-and-notifications/make.md
+++ b/sources/platform/integrations/workflows-and-notifications/make.md
@@ -10,7 +10,7 @@ slug: /integrations/make
---
-[Make](https://make.com/) *(formerly Integromat)* allows you to create scenarios where you can integrate various services (modules) to automate and centralize jobs. Apify has its own module you can use to run Apify Actors, get notified about run statuses, and receive Actor results directly in your Make scenario.
+[Make](https://www.make.com/) *(formerly Integromat)* allows you to create scenarios where you can integrate various services (modules) to automate and centralize jobs. Apify has its own module you can use to run Apify Actors, get notified about run statuses, and receive Actor results directly in your Make scenario.
## Connect Apify to Make
diff --git a/sources/platform/schedules.md b/sources/platform/schedules.md
index 57051a0e1..e0b92ca3c 100644
--- a/sources/platform/schedules.md
+++ b/sources/platform/schedules.md
@@ -120,7 +120,7 @@ The schedule setup tool uses [cron expressions](https://en.wikipedia.org/wiki/Cr
The **Next runs** section shows when the next run will be, if you click on **Show more** button it will expand and show you the next five runs. You can use this live feedback to experiment until you find the correct configuration.
-You can find more information and examples of cron expressions on [crontab.guru](http://crontab.guru/). For additional and non-standard characters, see [this](https://en.wikipedia.org/wiki/Cron#CRON_expression) Wikipedia article.
+You can find more information and examples of cron expressions on [crontab.guru](https://crontab.guru/). For additional and non-standard characters, see [this](https://en.wikipedia.org/wiki/Cron#CRON_expression) Wikipedia article.
### Notifications
diff --git a/sources/platform/storage/dataset.md b/sources/platform/storage/dataset.md
index 53c255f76..ef4fa942a 100644
--- a/sources/platform/storage/dataset.md
+++ b/sources/platform/storage/dataset.md
@@ -147,7 +147,7 @@ You can then use that variable to [access the dataset's items and manage it](/ap
> When using the [`.list_items()`](/api/client/python/reference/class/DatasetClient#list_items) method, if you fill both `omit` and `field` parameters with the same value, then `omit` parameter will take precedence and the field is excluded from the results.
-Check out the [Python API client documentation](/api/client/python/reference/class/DatasetClient) for [help with setup](/api/client/python/docs/quick-start) and more details.
+Check out the [Python API client documentation](/api/client/python/reference/class/DatasetClient) for [help with setup](/api/client/python/docs) and more details.
### Apify SDKs
diff --git a/sources/platform/storage/key_value_store.md b/sources/platform/storage/key_value_store.md
index 073296bfc..cb0a829be 100644
--- a/sources/platform/storage/key_value_store.md
+++ b/sources/platform/storage/key_value_store.md
@@ -124,7 +124,7 @@ my_key_val_store_client = apify_client.key_value_store('jane-doe/my-key-val-stor
You can then use that variable to [access the key-value store's items and manage it](/api/client/python/reference/class/KeyValueStoreClient).
-Check out the [Python API client documentation](/api/client/python/reference/class/KeyValueStoreClient) for [help with setup](/api/client/python/docs/quick-start) and more details.
+Check out the [Python API client documentation](/api/client/python/reference/class/KeyValueStoreClient) for [help with setup](/api/client/python/docs) and more details.
### Apify SDKs
diff --git a/sources/platform/storage/request_queue.md b/sources/platform/storage/request_queue.md
index b99c3cf73..d8e275b03 100644
--- a/sources/platform/storage/request_queue.md
+++ b/sources/platform/storage/request_queue.md
@@ -135,7 +135,7 @@ my_queue_client = apify_client.request_queue('jane-doe/my-request-queue')
You can then use that variable to [access the request queue's items and manage it](/api/client/python/reference/class/RequestQueueClient).
-Check out the [Python API client documentation](/api/client/python/reference/class/RequestQueueClient) for [help with setup](/api/client/python/docs/quick-start) and more details.
+Check out the [Python API client documentation](/api/client/python/reference/class/RequestQueueClient) for [help with setup](/api/client/python/docs) and more details.
### Apify SDKs
diff --git a/src/pages/api/index.tsx b/src/pages/api/index.tsx
index 257cfcbff..39cbff112 100644
--- a/src/pages/api/index.tsx
+++ b/src/pages/api/index.tsx
@@ -222,7 +222,7 @@ const { items } = await client.dataset(defaultDatasetId).listItems();
The official library to interact with Apify API from a Python applications.
<GitButton href="https://github.com/apify/apify-client-python" data-size="large" data-show-count="true">Star</GitButton>
<div className="DescriptionLinks">
- <Button color="success" hideExternalIcon to='https://docs.apify.com/api/client/python/docs/quick-start'>Get started</Button>
+ <Button color="success" hideExternalIcon to='https://docs.apify.com/api/client/python/docs'>Get started</Button>
<ActionLink hideExternalIcon to='https://docs.apify.com/api/client/python/reference'>Python client reference</ActionLink>
</div>
</div>}