| stypora-root-url |
|---|
./ |
[TOC]
【由于本科期间学过C语言故跳过基础课程的部分课程,后续会补上笔记】
【有些文件名是中文或者你的文件路径里有中文可能会导致运行错误,这是取决于你的编译器(啊穗用的Mingw编译器是不支持中文的)】
变量存在的意义:方便我们管理内存空间
#include<iostream>
using namespace std;
int main()
{
int a;
a = 10;
cout <<"a="<<a<<endl;
system("pause");
return 0;
}
c++定义常量的方式
1、#define 宏常量:
#define 常量名 常量值
#define Day 7 文件上方定义,且不可修改,一旦修改就会报错
2、const 修饰的变量 :
const int month = 12 const修饰的变量也成为常量,不能被修改
作用:关键字是C++中预保留的词
C++关键字:
不要用关键字给变量或者常量起名称,否则会产生歧义;
上网查一下;
- 标识符不能是关键字
- 标识符只能由字母、数字、下划线组成
- 第一个字符必须为字母或下划线
- 标识符中字母区分大小写
advice:最后能做到见面知意
意义:给变量分配合适的内存空间
作用:表示整数类型数据
不同的整型表示方式如下:区别在于所占内存空间不同;
| 数据类型 | 占用空间 | 取值范围 |
|---|---|---|
| short | 2字节(2*8=16) | (-2^15~2^15-1) |
| int | 4字节 | (-2^31~2^31-1) |
| long | windows为4字节,linux为4字节(32位),8字节(64) | (-2^31~2^31-1) |
| long long | 8字节 | (-2^63~2^63-1) |
作用: 利用sizeof求数据类型的内存大小(单位字节)
short <int <=long <=long long
**作用:**表示小数
- 单精度float
- 双精度double
**区别:**有效数字范围不同
#include <iostream>
using namespace std;
int main()
{
float f1 = 3.1415926f;
double d1 = 3.1415926;
// 默认情况下 输出一个小数,会显示出6为有效数字
cout <<"f1="<<f1<<endl;
cout <<"d1="<<d1<<endl;
cout <<"size float "<<sizeof(float)<<endl; //4字节
cout <<"size double "<<sizeof(double)<<endl; // 8字节
cout << "Hello world!" << endl;
//科学计数法
float f2 = 3e2; //3*10^2
float f3 = 3e-2; //3*10^-2
cout<<f2<<endl;
cout<<f3<<endl;
return 0;
}语法: char ch = 'a';
注意1:单引号将字符括起来,不要用双引号;
注意2:单引号内只有一个字符,不是字符串;
- c和c++中的字符型变量只占用1个字节
- 字符型变量并不是把字符放在内存存储,而是将对于的ASCII码存储
**作用:**用于一些不能显示出来的ascll字符
两种风格
-
c 风格字符串:char 变量名[] = "字符串值"
-
C++ :string 变量名 = "字符串值"
加头文件,#include
-
相应的字符串函数,
- strlen(str) 返回字符串的长度
- strcpy(s1,s2)复制s2到s1
- strcmp(s1,s2) 如果s1和s2相同则返回0,如果s1小于s2则返回小于0,反之大于0
- strchr(s1,ch) 返回一个指针,指向字符串s1中字符ch第一次出现的位置
- strstr(s1,s2) 返回一个指针,指向字符串s1中s2第一次出现的位置
代表真或者假的值
bool类型占1个字节大小
关键字: cin
**语法:**cin>>变量
int a;
cin >>a;
cout <<a<<endl;| 运算符 | 术语 | 示例 | 结果 |
|---|---|---|---|
| % | 取模,取余 | 10%3 | 1 |
| ++ | 前置递增 | a=2;b=++a; | a=3;b=3; |
| ++ | 后置递增 | a=2;b=a++; | a=3;b=2; |
| -- | 前置递减,先自减再赋值给b | a=2;b=--a; | a=1;b=1; |
| -- | 后置递减,先赋值给b再自减 | a=2;b=a--; | a=1;b=2; |
不可以对0取模,两个小数不可以取模运算
| 运算符 | 术语 | 示例 | 结果 |
|---|---|---|---|
| ! | 非 | !a | 取反 |
| && | 与 | a&&b | 如果a和b都为真则a&&b为真,只要有一个为假则a&&b为假 |
| || | 或 | a||b | 如果a和b都为假则a||b为假,只要有一个为真则a||b为真 |
在c++中除了0都为真
三种程序运行结构:顺序结构,选择结构,循环结构
- 单行格式if语句
if(条件) {条件满足执行的语句} - 多行格式if语句
if(条件){条件满足执行的语句} else{条件不满足满足执行的语句}
- 多条件if语句
if(条件1){条件1满足执行的语句} else if(条件2){条件2满足满足执行的语句}...else{条件都不满足满足执行的语句}
作用: 实现简单的运算符判断
语法: 表达式1?表达式2:表达式3
如果表达式1的值为真,执行表达式2,并返回表达式2的结果;
如果表达式1的值为假,执行表达式3,并返回表达式3的结果;
和C语言一样
switch(变量)
{
case1:
代码块1
break //如果没有break 则会执行后续的code
case2:
代码块2
default:
代码块3
}if和switch区别
switch 缺点 :判断时候只能判断整型或者字符型,不可以是一个区间。
switch 优点:结构清晰,执行效率高。
case中没有break,程序会一直执行下去。
语法:while(条件){条件满足执行循环语句}
语法:do{循环语句} while(循环条件);
**Attention:**与while区别在于do...while会先执行一次循环语句,再判断循环条件。
语法:for(int i=0;i<10;i++){执行的循环代码}
**作用:**可以无条件跳转语句
语法:goto 标记;
**解释:**如果标记的名称存在,执行goto语句,会跳转到标记的位置
int main()
{
cout <<1<<endl;
cout <<2<<endl;
goto FLAG;
cout <<3<<endl;
cout <<4<<endl;
FLAG:
cout <<5<<endl;
return 0;
}一维数组3种定义方式:
int a[len];int a[3]={1,2,3};int a[]={1,2,3};
二维数组的4种定义方式:
int a[3][4];int a[3][4]={{1,2,3,4},{1,2,3,4}};int a[3][5]={1,2,3,4};int a[][2]={1,2,3,4};
- 返回值类型 int
- 函数名 add
- 参数类型 (int n1,int n2)
- 函数体语句 函数的代码块
- return 表达式 return res;
这个不用说了吧,把公式拿过来用而已;
值传递的时候,形参改变不会影响实参
4种:
- 参数和返回值排列组合
在使用函数之前告诉 我要用这个函数了。
声明可以有多次,定义只可以有一次
**作用:**让代码结构更加清晰
函数文件编写一般4个步骤:
- 创建.h文件
- 创建.cpp源文件
- 在头文件写函数的声明
- 在源文件写函数的源定义
同C语言【由于本科期间学过C语言故跳过此课程,后续会补上笔记】
同C语言【由于本科期间学过C语言故跳过此课程,后续会补上笔记】
#define,无参宏定义的一般形式为:#define 标识符 字符串(例:#define Max 10)。define函数定义一个常量。常量类似变量,不同之处在于:在设定以后,常量的值无法更改。常量值只能是字符串或者 数字。 #undef ,就是取消一个宏的定义,之后这个宏所定义的就无效;但是可以重新使用#define 进行定义。 1.在一个程序块中用完宏定义后,为防止后面标识符冲突需要取消其宏定义.
#undef就是取消一个宏的定义,之后这个宏所定义的就无效;
但是可以重新使用#define 进行定义。
c++执行,将内存划分为4各区域:
- 代码区: 存放函数体的二进制代码,由OS进行管理的
- **全局区:**存放全局变量和静态变量以及常量
- 栈区: 由编译器自动分配释放,存放函数的参数值、局部变量等
- 堆区: 由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收
**内存区的意义:**不同区域存放的数据有不同的生命周期;
代码区:
存放CPU执行的机器指令
代码区是共享的,共享的目的是对于频繁被执行的程序,只需要在内存中有一份代码即可
代码区是只读的,使其只读的原因是防止程序意外地修改了它的指令
全局区:
全局变量和静态变量存放在此
全局区还包含了常量区、字符串常量和其他常量(局部常量不在全局区,const int a=10; 不在全局区)
该区域的数据在程序结束后由操作系统释放
总结:
- C++ 在程序运行钱分为全局区和代码区
- 代码区特点是共享和只读
- 全局区中存放全局变量,静态变量,常量
- 常量区中存放const修饰的全局变量 和 字符串常量
栈区:
由编译器自动分配释放,存放函数的参数值、局部变量等
Pay Attention:不要返回局部变量的地址,栈区开辟的数据由编译器自动释放;
堆区:
由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收
在C++中主要利用new在堆区开辟内存
c++中new操作符在堆区开辟数据
堆区开辟的数据由程序员手动开辟手动释放释放利用操作符delete
语法:new 数据类型
利用new创建的数据,会返回该数据对应的类型的指针
//开辟堆区空间
//开辟数组空间
int *p = new int a[10];
//释放数组
delete[] a;
//开辟变量空间
int *q = new int a;
//释放变量
delete a;作用: 给变量起别名
语法: 数据类型 &别名 = 原名
- 引用必须初始化
- 不能写
int &b;
- 不能写
- 引用一旦初始化后不能改变
- 也就是说 刚开始 b是a的别名了,后来不可以把b变成c的别名
作用:函数传参时,可以利用引用的技术让形参修饰实参
优点:简化指针修改实参
- 不要返回局部变量的引用
- 如果函数的返回值是一个引用则函数的调用可以为左值
本质:引用的本质实现是一个指针常量
int&ref = a;//等价于下面这行代码
int* const ref = &a;// 指针常量 说明指向不可改,也就是说引用不可改
ref = 20;//内部发现ref是一个引用则自动转换为 *ref = 20;**作用:**常量引用主要用来修饰形参,防止误操作
使用场景:在函数形参列表中,可以加const修饰形参,防止形参改变实参
int &ref = 10;//引用本身是需要一个合法的空间,因此这一行是错误的,但是在前面加上一个const就可以了
const int &ref = 10;// 等价于 int t = 10;cosnt int &ref = t;函数列表的形参可以由默认值的
语法:返回值类型 函数名(参数=默认值){函数体}
Pay Attention:
- 如果某个位置已有了默认参数,那么从这个位置往后,从左到右都必须有默认值
- 如果函数的声明有默认参数,函数实现就不能有默认参数;声明和实现只能有一个有默认参数;
函数形参列表里可以有占位参数,用来占位,调用函数时必须填补该位置
语法:返回值类型 函数名(数据类型){函数体}
void func(int a,int)
{
//函数体
} //这个函数就必须要两个参数才可以调用作用:函数名相同,提高复用性
函数重载满足的条件:
-
在同一个作用域下
-
函数名称相同
-
函数参数类型不同,或者个数不同,或者顺序不同
void f2() { cout<<"f2用用"<<endl; } void f2(int a) { cout<<"f2用用!!!"<<endl; }
**Pay Attention:**函数的返回值不可作为函数重载的条件(int 类型和 void类型不能重载)
- 引用作为重载的条件
- 函数重载碰到默认参数(出现二义性)
面向对象三大特性:封装、继承、多态
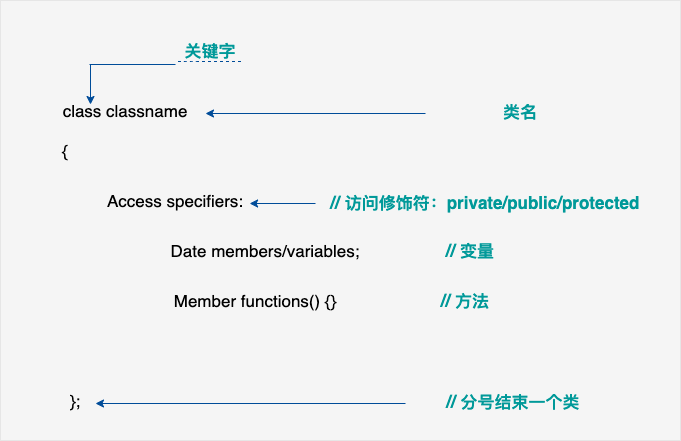
对象蓝图;
-
在类的定义里面有变量声明和函数声明,也可以在类里面定义函数;
-
类成员函数的定义在类的外面写格式(使用范围解析运算符::)如下:
-
函数类型 类名::函数名字(参数): { 函数体 }
需要注意的是,私有的成员和受保护的成员不能使用直接成员访问运算符 (.) 来直接访问
封装的意义:
- 将属性和行为作为整体
- 将属性和行为加以权限控制
语法:class name{内容};
- pubilic 公共权限 成员 类内可以访问,类外可以访问
- protected 保护权限 成员 类内可以访问, 类外不可以访问 儿子可以访问父亲中的保护内容
- private 私有权限 成员 类内可以访问,类外不可以访问 儿子不可以访问父亲中私有内容
- struct 默认权限为共有
- class 默认权限为私有
优点:
- 将所有成员设置为私有们可以自己控制读写权限
- 对于写权限,我们可以检测数据的有效性
- 类似恢复出厂设置
- 清理数据
对于初始化和清理是两个非常重要的安全问题
-
一个对象或者变量没有初始状态,对其使用后果是未知
-
同样的使用完一个对象或变量,没有及时清理,也会造成一定的安全问题
解决以上问题:构造函数和析构函数
这两个函数是编译器自动调用,完成对象初始化和清理工作;对象的初始化和清理工作是编译器强制我们要做的事情,因此如果我们不提供构造和析构,编译器会提供编译器提供的构造函数和析构函数是空实现。
- 构造函数:主要作用于创建对象时为对象的成员属性赋值,构造函数由编译器自动调用,无须手动调用。
- 析构函数:主要作用于对象销毁前系统自动调用,执行清理工作(一般在程序结束时调用)。
构造函数语法:类名(){函数体}
- 构造函数,没有返回值也不写void
- 函数名称和类名相同
- 构造函数可以有参数,因此发生重载
- 程序在调用对象时候会自动调用构造函数,无需手动调用,而且只会调用一次
析构函数语法:~类名(){函数体}
- 析构函数,没有返回值也不写void
- 函数名称与类名相同,前面加上~
- 析构函数不可以有参数,因此不发生重载
- 程序对象销毁前会自动调用析构,无需手动调用,而且只会调用一次
两种分类方式:
按参数分:有参构造和无参构造
按类型分:普通构造和拷贝构造
class Person
{
public:
Person()
{
cout<<"构造函数调用"<<endl;
}
// 有参构造
Person(int a)
{
cout<<"构造函数调用"<<endl;
}
//拷贝构造函数
Person(const Person &p)
{ //将传入的对象的属性 拷贝到我身上
age = p.age;
}
}
调用:
- 括号法
- 显式法
- 隐式转化法
Person p1;
//括号法
Person p(10); // 有参构造
Person p(p1); // 拷贝构造
//显式法
Person p2 = Peseson(10);//有参构造(类似于Java);
Person p2 = Peseson(p1);//拷贝构造;
// 匿名对象 特点:当前执行结束,立刻释放对象
Person(10);
Person(p1);//不要利用拷贝构造函数 初始化匿名对象
//隐式转化法
Person p3 = 10;//相当于写了 Person p3 = Peseson(10)
Person p3 = p1;//拷贝构造Pay Attention:
- 调用默认构造函数(
Person p;)时候,不要加(),因为编译器会认为他是一个函数声明,不会认为在创作对象; - 不要利用拷贝构造函数 初始化匿名对象
拷贝构造函数调用的三种情况:
- 使用一个已经创建完毕的对象来初始化一个新对象
- 值传递的方式给函数参数传值;(意思就是 把类的对象作为参数传递给函数时 会自动调用拷贝构造函数)
- 以值方式返回局部对象;(意思就是 把类的对象作为函数的返回值 会自动调用拷贝构造函数)
默认情况,C++编译器至少给一个类添加3个函数
- 默认构造函数
- 默认析构函数
- 默认拷贝构造函数**,对属性值进行值拷贝**
构造函数调用规则:
- 如果用户定义有参构造函数,c++不在提供默认无参构造,但是会提供默认拷贝构造
- 如果用户定义了拷贝构造函数,c++不会提供其他构造函数
浅拷贝:简单的赋值拷贝操作,对于拷贝构造函数编译器默认实现的是浅拷贝
问题:
浅拷贝会造成堆区的内存重复释放
解决:
利用深拷贝解决
**深拷贝:**在堆区重新申请内存空间,进行操作
语法:构造函数():属性1(v1),属性2(v2)....{}
//初始化列表初始化属性
Person(int a,int b ,int c):A(a),B(b),C(c)
{
}C++类中的成员是另一个类的成员,称为 对象成员
class A
{
public:
A()
{
cout<<"A的构造函数"<<endl;
}
~A()
{
cout<<"A的析构函数"<<endl;
}
};
class B
{
public:
A a;
B()
{
cout<<"B的构造函数"<<endl;
}
~B()
{
cout<<"B的析构函数"<<endl;
}
};
B 类中有对象A作为成员,A为对象成员
创建B对象时,A与B的构造和析构顺序怎样的?
先执行A 的构造函数 再执行B的构造函数,然后执行B的析构函数 再执行A析构函数;
静态成员就是在成员变量或者函数前面加上关键字static,成为静态成员
分类:
-
静态成员变量
- 所有对象共享同一份数据
- 在编译阶段分配内存
- 类内声明,类外初始化
-
静态成员函数
- 所有对象共享同一个函数
- 静态成员函数只能访问静态成员变量
- 可以通过对象访问也可以通过类名访问
- 也是有权限的(public & private)
只有非静态成员变量才属于类的对象上
空对象大小为 1字节,C++编译器会给每个空对象分配一个字节空间,是为了区分空对象占内存的位置
- 静态成员变量 不属于类对象上
- 静态成员函数 不属于类对象上
- 非静态成员函数 不属于类的对象上
如何区分那个对象是调用自己的?
用this指针!this指针指向被调用的成员函数所属的对象!
this指针是隐含每一个非静态成员函数内的一种指针
this指针不需要定义,直接使用即可
this指针的用途(解决什么问题):
- 当形参和成员变量同名时,可用this指针来区分(解决变量或者函数名称冲突)
- 在类的非静态成员函数中返回对象本身,可使用return *this
空指针可以调用成员函数,注意看有没有this指针
class Person
{
void f1()
{
cout<<"aa";
}
void f2()
{
cout<<age<<endl;
}
int age;
};
int main()
{
Person *p = NULL;
p->f1();//可执行 空指针调用函数
p->f2();//报错,因为这个函数里面要调用age变量 ,即this->age;而p是一个null,没有age
}常函数:
- 成员函数后加const后我们称这个函数为常函数
- void f1() const{函数体}
- 实际上时修饰this指向,让this指向的值也不可以修改 变成const Person * const this;
- 常函数内不可以修改成员属性
- 成员属性声明时加关键字mutable后,在常函数中依然可以修改
常对象:
- 声明对象前加const称为常对象
- 常对象只能调用常函数
客厅(public),卧室(private)
但是私有属性,也想让一些特殊的类或者函数进行访问,就要用到友元技术;
友元的目的:
让一个函数或者类访问另一个类的私有成员;
友元的关键字:friend
友元的三种实现:
- 全局函数做友元
- 类做友元
- 成员函数做友元
在要被访问的类里面 加上全局函数的声明,friend void f1();
在要被访问的类里面 加上类的声明,friend class 类名;
也就是被加上友元的类里面的所以函数都可以访问 那个类
在要被访问的类里面 加上类的成员函数声明,friend 类名::成员函数();
只有被加上友元的成员函数可以访问那个类,其他的函数不可访问。
概念:对已有的运算符重载进行定义,赋予其另一种功能,以适应不同的数据类型
对于内置的数据类型,编译器知道如何运算;
如:int
通过自己写成员函数,实现两个对象相加属性后返回新的对象
//通过成员函数重载+号
class Person{
Person operator+ (Person &p)
{
Person t;
t.a = this->a + p.a;
return t;
}
public:
int a;
}
// Person p3 = p1.operator+(p2); 等价于 Person p3= p1 + p2;
//通过全局函数重载+号
Person operator+ (Person &p,Person &q)
{
Person t;
t.a = q->a + p.a;
return t;
}
// Person p3 = operator+(p1,p2); 等价于 Person p3= p1 + p2;运算符重载也可以发生函数重载;
Pay Attention:
- 对于内置的数据类型的表达式的运算符是不可以改变的 如 int + int
- 不要滥用运算重载符
作用: 可以输出自定义的类型
<<
class Person
{
public:
//成员函数 左移运算符 p.operator<<(cout); 简化:p<<cout;
//所以一般不用成员函数重载<<运算符,因为无法实现 cout<<p;
// void operator<<(Person& p)
// {
//
// }
int m_a;
int m_b;
};
//全局函数重载
ostream& operator<< (ostream &cout,Person &p)//本质 operator<<(cout,p) 简化cout <<p;
{
cout<<"m_a="<<p.m_a<<" m_b="<<p.m_b;
return cout;
}
void test()
{
Person p;
p.m_a = 10;
p.m_b = 20;
cout<<p<<endl; //endl 又会报错,因为没有那个链式调用 所以 把重载运算符函数改为 有返回值的函数
}
int main()
{
test();
cout << "Hello zht!" << endl;
return 0;
}
作用:通过重载递增运算符,实现自己的整型数据
class MyInterger
{
friend ostream& operator<< (ostream&out,MyInterger myint);
friend MyInterger& operator++(MyInterger& myint);
public:
MyInterger()
{
m_Num = 133;
}
//成员函数 重载前置++运算符
// MyInterger& operator++()
// {
// ++m_Num;
//
// return *this;
// }
//重载后置++运算符
//int 代表占位参数 用于区分前置和后置递增
MyInterger operator++(int)
{
MyInterger t = *this;
m_Num++;
return t;
}
private:
int m_Num;
};
// 全局函数 重载 <<运算符
ostream& operator<< (ostream&out,MyInterger myint)
{
out<<myint.m_Num;
return out;
}
//全局函数 重载前置++运算符
MyInterger& operator++(MyInterger &myint)
{
++myint.m_Num;
return myint;
}
//测试 前置++
void test1()
{
MyInterger myint;
//本质
//cout<<"sdf"<<myint.operator++().operator++()<<endl;
cout<<++myint<<endl; //简化
cout<<++(++myint)<<endl;
cout<<myint<<endl;
}
//测试 后置++
void test02()
{
MyInterger i;
//i.m_Num = 100;
cout<<i++<<endl;
cout<<i<<endl;
}
int main()
{
// test1();
test02();
cout << "Hello zht!" << endl;
return 0;
}总结:前置++返回引用,后置++返回 值
默认情况,C++编译器至少给一个类添加4个函数
- 默认构造函数
- 默认析构函数
- 默认拷贝构造函数,对属性值进行值拷贝
- 赋值运算符 operator= 对属性进行值拷贝
如果类中有属性指向堆区,做赋值操作时会出现深浅拷贝问题
/赋值运算符重载
class Cat
{
public:
Cat(int age)
{
m_age = new int(age);
}
~Cat()
{
if(m_age !=NULL)
{
delete m_age;
}
}
//重载运算符
Cat& operator=(Cat &c)
{
//应该先判断C是否有属性在堆区,如果有则释放感觉 再深拷贝
if(m_age !=NULL)
{
delete m_age;
m_age= NULL;
}
//深拷贝
m_age = new int(*c.m_age);
return *this;
}
int *m_age;
};
void test3()
{
Cat c(12);
Cat c1(32);
Cat c2(23);
c2 = c1= c;//赋值操作 浅拷贝 堆区内存重复释放 程序崩溃! 用深拷贝解决此问题
cout<<"age:"<<*c.m_age<<endl;
cout<<"age:"<<*c1.m_age<<endl;
cout<<"age:"<<*c2.m_age<<endl;
}**作用:**重载关系运算符,可以让两个自定义类型对象进行对比
- 函数调用符() 重载
- 由于重载后使用的方式非常像函数的调用,因此称为仿函数
- 仿函数没有固定的写法,非常灵活
class MyPrint
{
public:
//重载函数调用运算符
void operator()(string txt)
{
cout<<txt<<endl;
}
};
void test4()
{
MyPrint pr;
pr("hellow ");//由于使用起来很像函数调用,因此称为仿函数,
//匿名函数对象
MyPrint()("helloworld");
}继承是面向对象三大特性之一
class Son:public Father
{
};好处:减少重复的代码
三种
- 公共继承
- 保护继承
- 私有继承
【未完待续】
c++文件操作需要包含头文件<fstream>
文件类型分两种:
- 文本文件 -文件以文本的ASCLL码形式存储在计算机中
- 二进制文件 -文件以文本的二进制形式存储在计算机中
操作文件的三大类:
- ofstream:写操作
- ifstream:读操作
- fstream:读写操作
步骤如下:
- 包含头文件
#include<fstream> - 创建流对象
ofstream ofs; - 打开文件
ofs.open("文件路径",打开方式); - 写数据
ofs<<"写入数据"; - 关闭文件
ofs.close();
文件打开方式:
| 打开方式 | 解释 |
|---|---|
| ios::in | 为读文件而打开文件 |
| ios::out | 为写文件打开文件 |
| ios::ate | 初始位置:文件末尾 |
| ios::app | 追加方式写文件 |
| ios::trunc | 如果文件已存在 则 先删除 在创建 |
| ios::binary | 二进制方式 |
注意:文件打开方式可以配合使用,利用你|操作符
如:ios::binary | ios::out
步骤如下:
- 包含头文件
#include<fstream> - 创建流对象
ifstream ifs; - 打开文件
ifs.open("文件路径",打开方式); - 写数据
ifs<<"写入数据"; - 关闭文件
ifs.close();
//读取方式: 逐词读取, 读词之间用空格区分
void readFile1(string path)
{
fstream f;
f.open(path);
string s;
while(f>>s) // 把文件内容写入字符串s中
{
cout<<s<<endl;
}
f.close();
}
//读取方式: 逐行读取, 将行读入字符数组, 行之间用回车换行区分
void readFile2(string path)
{
fstream f;
f.open(path);
const int LINE_LENGTH = 100;
char str[LINE_LENGTH];
string s;
while(f.getline(s, LINE_LENGTH)) // 把文件内容写入字符数组s中
{
cout<<s<<endl;
}
f.close();
}
//读取方式: 逐行读取, 将行读入字符串, 行之间用回车换行区分
void readFile3(string path)
{
fstream f;
f.open(path);
string s;
while(getline(f,s)) // 把文件内容写入字符串s中
{
cout<<s<<endl;
}
f.close();
}打开方式指定为 ios::binary
步骤同上
同上
以二进制的方式读取数据
ifs.read((char*) &p,siezeof(p));
泛型编程
模板就是建立通用的摸具,大大提高复用性
- C++一种编程思想称为泛型编程,注意利用技术就是模板
- c++提高两种模板机制:函数模板和类模板
函数模板作用:
建立一个通用函数,其函数返回值类型和形参类型可以不具体制定,用一个虚拟的类型来代表
语法
template<typename T> // typename 可以替换class
函数声明或定义解释
template 声明创建模板
typename 表明其后面的符号是一种数据类型,可以用class代替
T 通用的数据类型,名称可以替换通常为大写字母
// 两个整型交换的函数
void swapInt(int &a,int &b)
{
int t =a;
a =b;
b = t;
}
// 两个double交换的函数
void swapDouble(double &a,double &b)
{
double t =a;
a =b;
b = t;
}
//定义函数模板
template<typename T>
void f(T &a,T &b)
{
T c;
c =a;
a= b;
b=c;
}
///调用函数模板
void test1()
{
int a = 10;
int b = 20;
// swapInt(a,b);
// 利用函数模板来交换
// 两种方式使用函数模板
// 1、自动类型推导
//mySwap(a,b);
// 2、显示指定类型
mySwap<int>(a,b);
cout<<"a="<<a<<",b="<<b<<endl;
double c= 1.1;
double d = 2.2;
swapDouble(c,d);
cout<<"c="<<c<<",d="<<d<<endl;
}注意事项:
- 自动类型推导,必须推出一致的数据类型才可以使用
- 模板必须要确定出T的数据类型,才可以使用
- 利用模板封装一个排序函数,对不同类型数组进行排序
- 从大到小,选择排序
- 分别利用char数组和int数组测试
// 1.2.3 函数模板案例
/*
利用模板封装一个排序函数,对不同类型数组进行排序
从大到小,选择排序
分别利用char数组和int数组测试
*/
// 交换
// template<class T>
// void mySwap(T &a,T &b)
// {
// T t =a;
// a = b;
// b = t;
// }
//打印函数
template<typename T>
void pritnArray(T a[],int len)
{
for (int i = 0; i < len; i++)
{
cout<<a[i]<<" ";
}
cout<<endl;
}
// 排序算法
template<typename T>
void mySort(T arr[],int len)
{
for (int i = 0; i < len; i++)
{
int max = i;//认定最大值的下标
for (int j = i+1; j < len; j++)
{
if (arr[max] < arr[j])
{
// 认定的最大值 比 遍历出的数值要小,说明j下边的元素才是真正的最大值
max = j;
}
}
if (max !=i)
{
//交换max 和j 的元素
mySwap(arr[max],arr[i]);
}
}
}
void test2()
{
//测试char数组
char chs[] = "sfdgdgs";
int num = sizeof(chs)/ sizeof(char);
mySort(chs,num);
pritnArray(chs,num);
//测试int数组
int a[] = {1,4,67,8};
num = sizeof(a)/sizeof(int);
mySort(a,num);
pritnArray(a,num);
}- 普通函数调用时可以发生自动类型转换(隐式类型转换)
- 函数模板调用时,如果利用自动类型推导,不会发生隐式类型转换
- 如果利用显示指定类型方式,可以发生隐式类型转换
// 函数模板
template<typename T>
T myAdd1(T a,T b)
{
return a+b;
}
void test3()
{
int a =10;
int b = 20;
char c ='c';//ASCLL: a -> 97
cout<<myAdd(a,c)<<endl;
// 1、自动类型推导
//cout<<myAdd1(a,c)<<endl; //a,c 类型不同 会报错,因为不能做隐式类型转换
// 2、显示指定类型
cout<<myAdd1<int>(a,c)<<endl;
}调用规则:
- 如果函数模板和普通函数都可以实现,优先调用普通函数
- 可以通过空模板参数列表来强制调用函数模板
- 函数模板也可以发生重载
- 如果函数模板可以产生更好的匹配,优先调用函数模板
// 1.2.5 普通函数和函数模板的规则
void myPrint(int a,int b)
{
cout<<"调用普通函数"<<endl;
}
template<class T>
void myPrint(T a,T b)
{
cout<<"调用模板函数"<<endl;
}
template<class T>
void myPrint(T a,T b,T c)
{
cout<<"调用重载的模板函数"<<endl;
}
void test4()
{
int a =1;
int b =2;
// 如果函数模板和普通函数都可以实现,优先调用普通函数
myPrint(a,b);
// 空模板参数列表,强制调用模板函数
myPrint<>(a,b);
// 重载模板函数
myPrint<>(a,b,11);
//函数模板可以产生更好的匹配,优先调用函数模板
myPrint(a,b,23);
myPrint("a","c");
}
总结:
少写普通函数和函数模板同名的把,在开发中没意义,这里就是想着学习一下这个规则式怎么样的,得了解呀,因为既然有函数模板就是为了少写普通函数。
局限性:
- 模板的通用性并不是万能的
就比如啊,你两个数组赋值,两个自定义数据类型比较大小,就不能正常进行是不是。而这些问题我们在前面的学到的运算符重载就可以解决。
//1.2.6 模板的局限性
// 特定的数据类型 需要具体方式特殊实现
class Person
{
public:
string m_name;
int m_age;
Person(string name,int age)
{
this->m_name = name;
this->m_age = age;
}
};
template<class T>
bool myComp(T &a, T &b)
{
if(a==b)
{
return true;
}
else
{
return false;
}
}
// 利用具体化的Person 的版本实现
template<> bool myComp(Person &a, Person &b)
{
if(a.m_name==b.m_name && a.m_age == b.m_age)
{
return true;
}
else
{
return false;
}
}
void test5()
{
int a =1;
int b =11;
Person p1("xcs",18);
Person p2("csy",19);
bool res = myComp(p1,p2);
if (res)
{
cout<<"p1==p2"<<endl;
}
else
{
cout<<"p1 != p2"<<endl;
}
}总结:
- 用具体化的模板去解决自定义类型的通用化
- 咱们学这个模板不是说要去自己写模板,是去使用STL提供的模板
👊知道模板是啥,然后会用这个模板就可以啦!
类模板作用:
- 建立一个通用类,类中的成员 数据类型可以不具体制定,用一个虚拟的类型来代表。
语法:
// 1.3 类模板
template<class NameType,class AgeType>
class Person
{
public:
NameType m_Name;
AgeType m_Age;
Person(NameType name,AgeType age)
{
this->m_Age = age;
this->m_Name = name;
}
void show()
{
cout<<"name:"<<this->m_Name<<" age:"<<this->m_Age<<endl;
}
};解释:
- template 声明创建模板
- class/typename 表面后面的符号是一种数据类型(虚拟)
- AgeType/NameType 通用的数据类型,名称可以替换就当作一个参数变量,通常为大写字母
void test1()
{
Person<string,int> p1("xcs",18);// 使用类模板并给定参数类型
p1.show();
}类模板和函数模板的区别主要有两点:
- 类模板没有自动类型推导的使用方式
- 类模板在模板参数列表中可以有默认参数
// 1.3.2 类模板与函数模板区别
// 用上面 定义的 Person类模板
//1. 类模板没有自动类型推导的使用方式
void test2()
{
// Person p("xcs",22); //直接这么写会报错,无法用自动类型推导
Person<string,int> p1("xcs",18);// 正确,只能是显示指定类型
p1.show();
}
//2. 类模板在模板参数列表中可以有默认参数,定义模板类的时候 直接就给出了,如下
# template<class NameType,class AgeType = int>
void test2()
{
Person<string> p1("xcs",18);// 因为在定义的时候指定了默认参数
//template<class NameType,class AgeType = int>
p1.show();
} 类模板中成员函数和普通类中的成员函数创建时机是有区别的:
- 普通类中的成员函数是一开始就创建的
- 类模板中的成员函数在调用时才创建
// 1.3.3 类模板中成员函数创建时机
// - 普通类中的成员函数是一开始就创建的
// - 类模板中的成员函数在调用时才创建
class P1
{
public:
void show1()
{
cout<<"show P1"<<endl;
}
};
class P2
{
public:
void show2()
{
cout<<"show P2"<<endl;
}
};
template<class T>
class myClass
{
public:
T obj;
// 类模板中的成员函数,并不是一开始创建的,而是在模板调用时再生成
void f1()
{
obj.show1();
}
void f2()
{
obj.show2();
}
};// 当我不知道obj是啥类型的时候但是 obj.show编译时没错的,也就是说 类模板的成员函数 没有被调用这个 f1,f2 是没有被生成的所以是不会报错的,只有在调用f1,f2的时候才知道obj是个啥
void test4()
{
// cout<<"test3"<<endl;
myClass<P1> m;
m.f1();// 调用f1不会报错,识别obj 为P1
//m.f2();// 上面已经指定obj为类型P1 而P1 里面是没有show2()函数的 所以是会报错的 但是 你不调用f2 是不会报编译错误的
// 对比着看 就能知道 类模板的成员函数是什么时候创建的,这里有点绕,实在绕不懂的时候可以先认定结论然后带着结论去对比code理解看
}
总结:类模板成员函数不是在一开始就创建的,而是在调用的时候就创建的
学习目标:
- 类模板实例化出的对象,向函数传参的方式
一共有三种传入方式:
- 指定传入的类型 直接显示对象的数据类型
- 参数模板化 将对象的参数变为模板进行传递
- 整个类模板化 将这个对象类型模板化进行传递
// 1.3.4 类模板对象做函数参数
template<class T1,class T2>
class A
{
public:
T1 m_Name;
T2 m_Age;
A(T1 name,T2 age)
{
this->m_Age = age;
this->m_Name = name;
}
void show()
{
cout<<"name:"<<this->m_Name<<" age:"<<this->m_Age<<endl;
}
};
// 1. 指定传入的类型 直接显示对象的数据类型
// 使用相对广泛
void printA( A<string,int> a)
{
a.show();
}
void test5()
{
A<string,int> p("xcs",22);
printA(p);
}
// 2. 参数模板化 将对象的参数变为模板进行传递
template<class T1,class T2>
void printA2( A<T1,T2> &a)
{
a.show();
cout<<"T1 type:"<<typeid(T1).name()<<endl;// 查看这个类型的名字
cout<<"T2 type:"<<typeid(T2).name()<<endl;
}
void test6()
{
A<string,int> p("xcs",22);
printA2(p);
}
// 3. 整个类模板化 将这个对象类型模板化进行传递
template<class T>
void printA3( T &a)
{
a.show();
cout<<"T type:"<<typeid(T).name()<<endl;
}
void test7()
{
A<string,int> p("xcs",22);
printA3(p);
}总结:
- 通过类模板创建对象,可以有三种方式向函数中进行传参
- 使用比较多的是第一种:指定传入类型(个人感觉2,3中太复杂都是用函数模板配合着类模板去使用,第2中最呆瓜不建议使用,不过还是特殊情况特殊使用)
当类模板碰到继承时,需要注意:
- 当子类继承的父类是一个类模板时,子类在声明的时候要指定出父类模板中T的类型
- 如果不指定,编译器无法给子类分配内存
- 如果想灵活指定出父类中T的类型,子类也需要变为类模板
// 1.3.5 类模板与继承
// 看类模板是如何被继承的?
// 这是一个base类模板
template<class T>
class Base
{
public:
T m;
Base()
{
cout<<"这是base的构造函数"<<endl;
}
};
// 定义个普通子类1
// 普通类继承 父类模板类 需指定父类的 模板参数类型
//class son1:public Base // 没有指定 父类的 模板参数的类型 会报错
class son1:public Base<int>
{
public:
string n;
};
// 定义个普通子类2
// 子类模板继承父类模板
template<class T1,class T2>
class son2:public Base<T1>
{
public:
T2 n;
son2()
{
cout<<"T1 type:"<<typeid(T1).name()<<endl;
cout<<"T2 type:"<<typeid(T2).name()<<endl;
}
};
void test8()
{
son1 s1; //实例化son1的时候会 调用 父类的 构造函数
son2<int,string>s2; // 实例化的时候要 显示指定 模板类(包括父类)的参数类型
}实例化子类时,模板参数的传递过程:

总结:
- 不管什么时候使用类去继承,都要体现出子类继承父类的时候要声明父类的模板参数类型T,因为如果不声明的话,编译器不知道如何去给子类分配内存(模板参数T所对应的变量的内存,如
T m不说明T为一个具体的类型无法计算内存)
必须要掌握成员函数类外实现
// 1.3.6 类模板成员函数类外实现
// 仿照上面写的类模板
template<class T1,class T2>
class Xcs
{
public:
T1 m_name;
T2 m_age;
Xcs(T1,T2);
void show();
};
// Xcs 类外实现 Xcs()构造函数
template<class T1,class T2>
Xcs<T1,T2>::Xcs(T1 name,T2 age)
{
this->m_age = age;
this->m_name = name;
}
template<class T1,class T2>
void Xcs<T1,T2>::show() // 加上模板参数
{
cout<<"name:"<<this->m_name<<" age:"<<this->m_age<<endl;
}
void test9()
{
Xcs<string,int> x("xcs",12);
x.show();
}类模板成员函数分成几个文件编写产生的问题及解决方式
问题:
- 类模板中成员函数创建时机是在调用阶段(前面1.3.3 说过的),导致文件编写时链接不到

解决:(这些都体现在源码里面)
- 直接包含.cpp源文件
- 将声明和实现写到同一个文件中,更该后缀名会.hpp,hpp是约定的名称不是强制
分文件编写:
- 创建一个头文件
Xcs.h,Xcs.cpp .cpp文件写类的成员函数,.h文件写类的声明- 然后通过头文件是
.h和.cpp产生联系(看图说话)
创建.h&.cpp:


Xcs.h:
#include <iostream>
#include <string>
using namespace std;
// 定义的模板类
template<class T1,class T2>
class Xcs
{
public:
T1 m_name;
T2 m_age;
Xcs(T1,T2);
void show();
};
//普通的Person 类
class Person
{
public:
string m_Name;
int m_Age;
Person(string name,int age);
void show();
};
Xcs.cpp:
#include <iostream>
#include <string>
#include "Xcs.h"
using namespace std;
// Xcs 类外实现 Xcs()构造函数
template<class T1,class T2>
Xcs<T1,T2>::Xcs(T1 name,T2 age)
{
this->m_age = age;
this->m_name = name;
}
template<class T1,class T2>
void Xcs<T1,T2>::show()// 加上模板参数
{
cout<<"name:"<<this->m_name<<" age:"<<this->m_age<<endl;
}
// Person类成员函数
Person::Person(string name,int age)
{
this->m_Age = age;
this->m_Name = name;
}
void Person::show()
{
cout<<"name:"<<this->m_Name<<" age:"<<this->m_Age<<endl;
}
3_class_Template.cpp:
#include <iostream>
#include <string>
#include "Xcs.h" // 导入你编写的类
using namespace std;
void test1()
{ // 分文件编写 模板类 Xcs
Xcs x("xcs",22); // 而直接这么调用是会报错的也就是上面提到的问题
x.show();
// 分文件编写 普通类Person
// Person p("xcs",1);
// p.show();
}
//
int main()
{
system("chcp 65001");
test1();
system("pause");
return 0;
}总结:
- 主流的解决方式是第二种,将类模板和成员函数写到一起,并将后缀名改为.hpp
类模板配合友元函数的类内和类类外实现
全局函数类内实现: 直接在类内声明友元即可;
全局函数类外实现: 需要提前让编译器知道全局函数的存在;
// 1.3.8 类模板与友元
//类模板配合友元函数的类内和类类外实现
// 通过全局函数打印Person 的信息
// 提前让编译器知道Person类的存在
template<class T1,class T2>
class Person;
// 类外实现 全局函数,不需要加 class的作用域
template<class T1,class T2>
void printPer2(Person<T1,T2> p)
{
cout<<"类外实现"<<endl;
cout<<"name:"<<p.m_Name<<" age:"<<p.m_Age<<endl;
}
template<class T1,class T2>
class Person
{
// 全局函数 类内实现 ,为什么说这是全局函数,也就是说这里传进来的参数p 不是自身 而是其他的一个实例化对象,并且访问这个p的 私有属性m_Name,m_Age 故使用友元的技术
friend void printPer(Person<T1,T2> p)
{ cout<<"类内实现"<<endl;
cout<<"name:"<<p.m_Name<<" age:"<<p.m_Age<<endl;
}
// 全局函数 类外实现
// 加空模板的参数列表 <>
// 如果全局函数是类外实现,需要让编译器提前知道这个函数的存在
friend void printPer2<>(Person<T1,T2> p);
public:
Person(T1 name,T2 age)
{
this->m_Age = age;
this->m_Name = name;
}
private:
T1 m_Name;
T2 m_Age;
};
//全局函数 类内实现 测试
void test1()
{
Person<string,int> p("xcs",22);
printPer(p);
}
//全局函数 类外实现 测试
void test2()
{
Person<string,int> p("xcsy",22);
printPer2(p);
}总结:
- 如果没有特殊的要求,建议全局函数类内实现,用法简单,编译器直接识别。
案例描述:
- 实现一个通用的数组类(类似于STL中的Vector)
要求:
- 可以对内置数据类型以及自定义数据类型的数据经行存储
- 将数组中的数据存储到堆区
- 提供对应的拷贝构造函数以及operator= 防止浅拷贝问题
- 提供尾插法和尾删法对数组中的而数据进行增加和删除
- 可以通过下标的方式访问数组的元素
- 可以获取数组中当前元素个数和数组的容量
MyArry.cpp
// 自己的通用数组类
template<class T>
class MyArray
{
public:
//有参构造 参数 容量
MyArray(int capacity)
{ cout<<"MyArry 的有参构造调用"<<endl;
this->m_Capacity = capacity;
this->m_Size = 0;
this->pAddress = new T[this->m_Capacity];
}
// 拷贝构造
MyArray(const MyArray& arry)
{ cout<<"MyArry 的拷贝构造调用"<<endl;
this->m_Capacity = arry.m_Capacity;
this->m_Size = arry.m_Size;
//this->pAddress = arry.pAddress; // 这是指针不能直接赋值 结束的时候会导致堆区的数据重复释放
// 深拷贝
this->pAddress = new T[arry.m_Capacity];
// 将arry中的数据都拷贝过来
for (int i = 0; i < this->m_Size; i++)
{
this->pAddress[i] = arry.pAddress[i];
}
}
// operator= 防止浅拷贝问题 为了可以有 a = b =c 操作,所以返回自身
MyArray& operator=(const MyArray& arry)
{ cout<<"MyArry 的=调用"<<endl;
// 首先判断原来堆区是否有数据 如果有则先释放
if(this->pAddress != NULL)
{
delete[] this->pAddress;
this->pAddress = NULL;
this->m_Capacity = 0;
this->m_Size = 0;
}
// 深拷贝
this->m_Size = arry.m_Size;
this->m_Capacity = arry.m_Capacity;
this->pAddress = new T[this->m_Capacity];
for (int i = 0; i < this->m_Size; i++)
{
this->pAddress[i] = arry.pAddress[i];
}
return *this;
}
// 尾插法
void push_back(const T & val)
{
// 判断容量是否等于大小
if (this->m_Capacity == this->m_Size)
{
return;
}
this->pAddress[this->m_Size] = val; // 数组末尾插入数据
this->m_Size++; // 更新数组大小
}
// 尾删法
void pop_back()
{
// 用户访问不到最后一个元素,即为尾删,逻辑删除
if (this->m_Size == 0)
{
return ;
}
this->m_Size--;
}
// 通过下标的方式访问元素 重载[]
// arry[0] arry[1] 还可以作为左值存在 即 arr[0] =100;
T& operator[](int index)
{
return this->pAddress[index]; // 这里没有考虑越界问题,可以自己加个判断
}
//重载cout<<
// 这里要用友元 这里相当于是全局函数 访问 另一个MyArry里面的私有属性 pAddress 故要用友元
friend ostream &operator<< (ostream& cout,const MyArray & arry)
{
for (int i = 0; i < arry.m_Size; i++)
{
cout<<arry.pAddress[i]<<" ";
}
return cout;
}
//返回数组的大小
int getSize()
{
return this->m_Size;
}
// 返回数组的容量
int getCapacity()
{
return this->m_Capacity;
}
// 析构
~MyArray()
{ cout<<"MyArry 的析构函数调用"<<endl;
if(this->pAddress !=NULL)
{
delete[] this->pAddress;
this->pAddress = NULL;
}
}
private:
T* pAddress; // 指针指向堆区开辟的真实数组
int m_Capacity; // 通用数组的容量
int m_Size; // 数组的大小
};c++内置数据类型测试定义的MyArry数组:
// 在MyArry中存入的是int类型(内置类型)的测试
void test1()
{
MyArray<int> arr1(5);
for (int i = 0; i < 5; i++)
{
//利用尾插法向数组中插入数据
arr1.push_back(i);
}
cout<<"arr1 的打印输出:"<<arr1<<endl; // 重载左移运算符<< 打印输出 MyArry
cout<<"arr1[0] 的打印输出:"<<arr1[0]<<endl;
cout<<"arr1 大小:"<<arr1.getSize()<<endl;
cout<<"arr1 容量:"<<arr1.getCapacity()<<endl;
MyArray<int> arr2(arr1);
cout<<"arr2 的打印输出:"<<arr2<<endl;
arr2.pop_back();
cout<<"arr2执行pop_back()"<<endl;
cout<<"arr2 容量:"<<arr2.getCapacity()<<endl;
cout<<"arr2 大小:"<<arr2.getSize()<<endl;
// MyArry<int> arr3(100);
// arr3 = arr1;
}自定义数据类型Person存入数组:
// 自定义数据类型测试
class Person
{
public:
string m_Name;
int m_Age;
Person(){}; // Pay Attention!!! 这个无参构造必须写,因为在下面声明MyArry<Person> arr(10);的时候,没有无参构造会报申请内存空间的错误
Person(string name,int age)
{
this->m_Age = age;
this->m_Name = name;
}
};
void printPersonArray(MyArray<Person> &arr)
{
for (int i = 0; i < arr.getSize(); i++)
{
cout<<"Name:"<<arr[i].m_Name<<" Age:"<<arr[i].m_Age<<endl;
}
}
void test2()
{
MyArray<Person> arr(10);
Person p1("xcs",22);
Person p2("xcsy",22);
Person p3("geek",22);
// 将数据插入数组
arr.push_back(p1);
arr.push_back(p2);
arr.push_back(p3);
// 打印person数组
printPersonArray(arr);
cout<<"arr_Person 大小:"<<arr.getSize()<<endl;
cout<<"arr_Person 容量:"<<arr.getCapacity()<<endl;
//cout<<"arr 的输出:"<<arr<<endl; // 这里不能用重载的<< 因为没有写 Person类的重载<<
}总结:
- 这个案例复习了蛮多东西的,首先模板,数组,类,运算符重载,友元等,将来可以自己写一个STL库
为了建立数据结构和算法的一套标准
- vector 底层数据结构为数组 ,支持快速随机访问
- list 底层数据结构为双向链表,支持快速增删
- deque 底层数据结构为一个中央控制器和多个缓冲区,详细见STL源码剖析P146,支持首尾(中间不能)快速增删,也支持随机访问
- stack 底层一般用23实现,封闭头部即可,不用vector的原因应该是容量大小有限制,扩容耗时
- queue 底层一般用23实现,封闭头部即可,不用vector的原因应该是容量大小有限制,扩容耗时
- 45是适配器,而不叫容器,因为是对容器的再封装
- priority_queue 的底层数据结构一般为vector为底层容器,堆heap为处理规则来管理底层容器实现
- set 底层数据结构为红黑树,有序,不重复
- multiset 底层数据结构为红黑树,有序,可重复
- map 底层数据结构为红黑树,有序,不重复
- multimap 底层数据结构为红黑树,有序,可重复
- hash_set 底层数据结构为hash表,无序,不重复
- hash_multiset 底层数据结构为hash表,无序,可重复
- hash_map 底层数据结构为hash表,无序,不重复
- .hash_multimap 底层数据结构为hash表,无序,可重复
- STL(Standard Template Library ,标准模板库)
- STL从广义上分为:容器(container) 算法(algorithm) 迭代器(iterator)
- 容器和算法之间通过迭代器进行无缝衔接
- STL几乎所有的代码都采用了模板类或者模板函数
六大组件:
- 容器:各种数据结构,如vector,list,deque,set,map等,用来存放数据;
- 算法:各种常用算法,如sort,find,copy,for_each等;
- 迭代器:扮演了容器与算法之间的胶合剂;
- 仿函数:行为类似函数,可作为算法的某种策略;
- 适配器(配接器):一种用来修饰容器或者仿函数或迭代器接口的东西;
- 空间配置器:负责空间的配置与管理;
置物之也。
STL容器就是把运用最广泛的数据结构实现出来
常用的数据结构: 数组,链表,树,栈,队列,集合,映射表等;
容器可分为序列式容器和关联式容器:
- 序列式容器:强调值的排序,序列式容器中的每个元素都有固定的位置;
- 关联式容器: 二叉树结构,各个元素之间没有严格的物理上的顺序关系;
问题之解法也。
有限的步骤,解决逻辑和数学上的问题,这一门学科我们叫做算法(Algorithm)
算法分为:质变算法和非质变算法
- 质变算法: 在运算过程中会更改区间内的元素的内容。如,拷贝,替换,删除等等;
- 非质变算法:在运算过程中不会更改区间内的元素的内容。如查找,计数,遍历,寻找极值等;
容器和算法之间的粘合剂。算法要通过迭代器才能访问容器中的元素
提高一种方法,使之能够依序寻访某个容器所含的各个元素,而又无需暴露该容器的内部表示方式。
每个容器都有自己的专属的迭代器。
迭代器使用非常类似于指针,初学阶段我们可以先理解迭代器为指针。
迭代器种类:
| 种类 | 功能 | 支持运算 |
|---|---|---|
| 输入迭代器 | 对数据的只读访问 | 只读,支持++,==,!= |
| 输出迭代器 | 对数据的只写访问 | 只写,支持++ |
| 前向迭代器 | 读写操作,并能向前推进迭代器 | 读写,支持++,==,!= |
| 双向迭代器 | 读写操作,并能向前向后操作 | 读写,支持++,-- |
| 随机访问迭代器 | 读写操作,可以跳跃式的访问任意数据,功能最强的迭代器 | 读写,支持++,--,[n],-n,<,<=,>,>= |
常用容器中的迭代器种类为双向迭代器和随机访问迭代器。
本质:
- string是C++风格的字符串,而string本质是一个类
string和char 的区别:*
- char* 是一个指针
- string是一个类,类内部封装了char*,管理这个字符串,是一个char*型的容器。
特点:
- string类内部封装了很多成员方法
- 如查找find,拷贝copy,删除delete,替换replace,插入insert
- string管理char* 所分配的内存,不用担心复制越界和取值越界等,由类内部进行负责
只要使用string文件前面要导入#include <string>
构造函数原型:
string();//默认构造string(const char * s);// 用char* 构造string(const string& str);// 拷贝构造string(int n, char c);// 使用n个字符c初始化构造
4.2 string构造函数.cpp:
// 4.1 string构造函数
void test1()
{
string s1; //默认构造
const char* str = "xcs is a good man";
string s2(str); // 用char* 构造
string s3(s2); // 拷贝构造
cout<<"s2:"<<s2<<endl;
cout<<"s3:"<<s3<<endl;
string s4(10,'a'); // 使用n个字符c初始化构造
cout<<"s4:"<<s4<<endl;
}总结:
- string的多种构造方式没有可比性,灵活使用即可
给string字符串进行赋值
赋值函数的原型:
string& operator=(const char* s);// char* 类型字符串 赋值给当前字符串string& operator=(const string& s);//把字符串s 赋值给当前字符串string& operator=(char c);//字符赋值给当前字符串string& assign(const char* s);//把字符串括号里面的参数char* 赋值给当前字符串string& assign(const char* s,int n);//把字符串括号里面的参数 前5个字符赋值给当前字符串string& assign(const string& s);//把字符串括号里面的参数string 赋值给当前字符串string& assign(int n,char c);//n个字符c 赋值给当前字符串
4.3 string赋值操作.cpp:
// 4.3 string赋值操作
void test1()
{
string s1; //默认构造
s1 = "xcs is a good man"; // char* 类型字符串 赋值给当前字符串s1
cout<<"s1:"<<s1<<endl;
string s2;
s2 = s1; //把字符串s1 赋值给当前字符串s2
cout<<"s2:"<<s2<<endl;
string s3;
s3 = 'a'; //字符赋值给当前字符串
cout<<"s3:"<<s3<<endl;
string s4;
s4.assign("xcs is a good man!");
cout<<"s4:"<<s4<<endl; //把字符串括号里面的参数char* 赋值给当前字符串s4
string s5;
s5.assign("xcs is a good man",5); //把字符串括号里面的参数 前5个字符赋值给当前字符串s5
cout<<"s5:"<<s5<<endl;
string s6;
s6.assign(s5); //把字符串括号里面的参数string 赋值给当前字符串s6
cout<<"s6:"<<s6<<endl;
string s7;
s7.assign(5,'c'); //n个字符c 赋值给当前字符串s7
cout<<"s7:"<<s7<<endl;
}总结:
- 啊穗个人建议
operator=还是比较实用,建议使用的时候用这个赋值就好了,但是当看到别人的代码写到assign需要看的懂就行
实现在字符串末尾拼接字符串
函数原型:
string& operator+=(const char* str);//重载+=操作符string& operator+=(const char c);//重载+=操作符string& operator+=(const string& str);//重载+=操作符string& append(const char* s);// 将字符串s连接到当前字符串结尾string& append(const char* s,int n);// 将字符串s的前n个字符连接到当前字符串结尾string& append(const string& s);// 将字符串s连接到当前字符串结尾 同string& append(const string& str);string& append(const string& s,int pos,int n);// 将字符串s中从pos开始的n个字符连接到字符串末尾
4.4 string字符串拼接.cpp:
// 4.4 字符串拼接
void test1()
{
string s1 = "xcs ";
s1 += " is a good man"; //重载+=操作符
cout<<"s1:"<<s1<<endl;
s1 += "!"; //重载+=操作符
cout<<"s1:"<<s1<<endl;
string s2 = "@SAIC";
s1 += s2; //重载+=操作符
cout<<"s1:"<<s1<<endl;
string s3 = "xcs";
s3.append(" loves basketball"); // 将字符串s连接到当前字符串结尾
cout<<"s3:"<<s3<<endl;
s3.append(" love LOL",4); // 将字符串s的前n个字符连接到当前字符串结尾
cout<<"s3:"<<s3<<endl;
string s4 = "&xcsy";
s3.append(s4);
cout<<"s3:"<<s3<<endl; // 将字符串s连接到当前字符串结尾
string s5 = "hello@@";
s3.append(s5,2,4);// 将字符串s中从pos开始的n个字符连接到字符串末尾
cout<<"s3:"<<s3<<endl;
}总结:
- 字符串拼接的重载很多,至少会一种,有需要就查笔记就可以。
- 查找:查找指定字符串是否存在
- 替换:在指定的位置替换字符串
函数原型:
int find(const string& str,int pos=0) const;//查找str第一次出现位置,从pos开始查找int find(const char* s,int pos=0) const;//查找s第一次出现位置,从pos开始查找int find(const char* s,int pos,int n) const;//从pos开始查找s的前n个字符第一次出现的位置int find(const char c,int pos=0) const;//查找字符c第一次出现位置,从pos开始查找int rfind(const string& str,int pos=npos) const;//查找str最后一次出现位置,从pos开始查找int rfind((const char* s,int pos=npos) const;//查找s最后一次出现位置,从pos开始查找int rfind(const char* s,int pos,int n) const;//从pos开始查找s的前n个字符最后一次出现的位置int rfind(const char c,int pos=0) const;//查找字符c最后一次出现位置,从pos开始查找
以上查找函数未查到就返回-1
string& replace(int pos,int n,const string & str);//替换从pos开始的n个字符为字符串strstring& replace(int pos,int n,const char* s);//替换从pos开始的n个字符为字符串s
源字符串改变!
4.5 string查找和替换.cpp-查找:
// 4.5 string查找和替换
//1、查找
void test1()
{
string s1 = "abcdefgde";
int pos;
// pos = s1.find("de");
pos = s1.find("df");
if(pos == -1)
{
cout<<"not find"<<endl;
}
else
{
cout<<"pos:"<<pos<<endl; // 返回的是参数字符串的第一个字符第一次出现所在的索引 未查到就返回-1
}
pos = s1.rfind("de"); // 从右往左查的第一个 所出现的位置索引
cout<<"pos:"<<pos<<endl;
}
4.5 string查找和替换.cpp-替换:
// 2、替换
void test2()
{
string s1 = "xcs is a good man";
s1.replace(0,3,"asdff"); // 从0号位置起的3个字符 替换为后面这个参数字符串所有,不管后面这个字符串有多长
cout<<"s1:"<<s1<<endl;
}
void test3()
{ /*
s.replace(pos, n, s1) //用s1替换s中从pos开始(包括0)的n个字符的子串
*/
string s1 = "xcs is a good man";
cout<<"s1:"<<s1<<endl;
s1.replace(1,3,"xcsy");
cout<<"s1_replace:"<<s1<<endl;
}总结:
- find查找是从左往后,rfind从右往左
- find找到字符串后返回查找的第一个字符位置,找不到则返回-1
- replace在替换时,要指定从哪个位置起,多少个字符,替换成什么样的字符串
字符串之间的比较。
比较方式:
- 字符串比较是按字符的ASCII码进行对比
- = 返回 0
- > 返回 1
- < 返回 -1
函数原型:
int compare(const string& s) const;//与字符串s比较int compare(const char* s) const;//与字符串s比较
4.6 string字符串比较.cpp:
// 4.6 string字符串比较
/* 字符串比较是按字符的ASCII码进行对比
= 返回 0
> 返回 1
< 返回 -1 */
void test1()
{
string s1 = "xcs";
//string s2 = "xcs";
string s2 = "ycs";
// string s2 = "ucs";
if(s1.compare(s2) == 0)
{
cout<<s1<<" == "<<s2<<endl;
}
else if(s1.compare(s2) == -1)
{
cout<<s1<<" < "<<s2<<endl;
}
else if(s1.compare(s2) == 1)
{
cout<<s1<<" > "<<s2<<endl;
}
}总结:
- 字符串比较主要是为了看两个字符串相等,比较谁大谁小没有太大的意义
string中单个字符存取方式:
char& operator[](int n);//通过[] 方式取字符char& at(int n);//通过at() 方式取字符
4.7 string字符存取.cpp:
// 4.7 string字符存取
void test1()
{
string s1 = "xcs is a good man";
for (int i = 0; i < s1.size(); i++)
{
cout<<s1[i]<<" "; //通过[] 方式取字符
}
cout<<endl;
for (int i = 0; i < s1.size(); i++)
{
cout<<s1.at(i)<<" ";//通过at() 方式取字符
}
cout<<endl;
// 修改单个字符
s1[0] = 'Y';
s1.at(1) = 'Y';
cout<<"s1:"<<s1<<endl;
}总结:
- 个人建议用[] 方式访问单个字符,但是要了解at()的用法,如果出现要认识是啥意思
对string字符串进行插入和删除字符操作。
函数原型:
string& insert(int pos,const char*s);// 在指定位置插入字符串sstring& insert(int pos,const string& str);// 在指定位置符串strstring& insert(int pos,int n,char c);// 在指定位置插入n个字符cstring& erase(int pos,int n=npos);// 删除从pos开始的n个字符
4.8 string插入和删除.cpp:
// 4.8 string插入和删除
void test1()
{
string s1 = "xcs is a man";
s1.insert(9,"good "); //在索引9位置 插入 "good "
cout<<"s1:"<<s1<<endl;
// 删除
s1.erase(0,3);
cout<<"s1:"<<s1<<endl;
}总结:
- 不管插入还是删除都需要指定下标,且下标都是从0开始数的。
从字符串中获取想要的子串或者说截取字符串的一部分。
函数原型:
string substr(int pos = 0,int n ) const;//返回由pos开始的n个字符组成的字符串
4.9 string字串获取.cpp:
// 4.9 string字串获取
void test1()
{
string s1 = "xcs is a good man";
string s2;
s2 = s1.substr(9,4);//截取 "good" //返回由pos开始的n个字符组成的字符串
cout<<"s2:"<<s2<<endl;
string email = "[email protected]";
//从邮箱地址中获取 用户名信息
int pos = email.find("@");
string name;
name = email.substr(0,pos);
cout<<"name:"<<name<<endl;
}总结:
-
该函数功能为:返回从pos开始的n个字符组成的字符串,原字符串不被改变。可以类比python中的切片
-
如要截取的是某个字符后面的一部分,可以先用
string find(char c);获得某个字符的 index然后用substr去截取所需的字符串。
源字符串改变!
void test1()
{ /*
s.replace(pos, n, s1) //用s1替换s中从pos开始(包括0)的n个字符的子串
*/
string s1 = "xcs is a good man";
cout<<"s1:"<<s1<<endl;
s1.replace(1,3,"xcsy");
cout<<"s1_replace:"<<s1<<endl;
}//通过使用strtok()函数实现
std::vector<std::string> split(const std::string &str,const std::string &pattern)
{
//const char* convert to char*
char * strc = new char[strlen(str.c_str())+1];
strcpy(strc, str.c_str());
std::vector<std::string> resultVec;
char* tmpStr = strtok(strc, pattern.c_str());
while (tmpStr != NULL)
{
resultVec.push_back(std::string(tmpStr));
tmpStr = strtok(NULL, pattern.c_str());
}
delete[] strc;
return resultVec;
};
//用STL里面的 findstr和substr实现
std::vector<std::string> splitWithStl(const std::string &str,const std::string &pattern)
{
std::vector<std::string> resVec;
if ("" == str)
{
return resVec;
}
//方便截取最后一段数据
std::string strs = str + pattern;
size_t pos = strs.find(pattern);
size_t size = strs.size();
while (pos != std::string::npos)
{
std::string x = strs.substr(0,pos);
resVec.push_back(x);
strs = strs.substr(pos+1,size);
pos = strs.find(pattern);
}
return resVec;
}
用ato这个类
string s1 = "12.001";
float d = atof(s1.c_str());
int a = atoi(s1.c_str()); //要转换成 int,double,long,long 分别用atoi,atof,atol,atoll
//ato这个类接收的是const char* char所以string 要用c_str()转换成char*#include <sstream>
auto formatDobleValue(double val, int fixed) {
std::ostringstream oss;
oss << std::setprecision(fixed) << val;
return oss.str();
}
vector存放内置数据类型:
- 容器:
vector - 算法:
for_each - 迭代器:
vector\<int>:iterator
5 vector.cpp-vector容器存放内置数据类型:
#include <iostream>
#include <cmath>
#include <algorithm>
#include <vector>
using namespace std;
void myPrint(int v)
{
cout<<v<<endl;
}
// vector容器存放内置数据类型
void test1()
{
//创建vector容器,可以理解为一个数组
vector<int> v;
// 向容器中插入数据
v.push_back(10);
v.push_back(12);
v.push_back(13);
// 通过迭代器访问容器中的数据
//第一种遍历方式
vector<int>::iterator itBegin = v.begin(); //起始迭代器,指向容器中的第一个元素
vector<int>::iterator itEnd = v.end(); //结束迭代器,指向容器中的最后一个元素的下个位置
while (itBegin != itEnd)
{
cout<< *itBegin<<endl;
itBegin++;
}
// 第二种遍历方式
cout<<"// 第二种遍历方式"<<endl;
for (int i = 0; i < v.size(); i++)
{
cout<<v[i]<<endl;
}
//第3种遍历方式
cout<<"// 第3种遍历方式"<<endl;
for (vector<int>::iterator it = v.begin(); it != v.end(); it++)
{
cout<< *it<<endl;
}
//第4种遍历方式,利用STL的遍历算法
cout<<"// 第4种遍历方式"<<endl;
for_each(v.begin(),v.end(),myPrint); //利用回调的技术 就是遍历v.begin() 到 v.end() 之间的每个元素去执行myPrint函数
}5 vector.cpp-vector-容器存放自定义的数据类型:
// 自定义数据类型 Person 类
class Person
{
public:
string m_Name;
int m_Age;
Person(string name,int age);
void show();
};
// 类的成员函数实现
Person::Person(string name,int age)
{
this->m_Age = age;
this->m_Name = name;
}
void printPerson(Person p)
{
cout<<"name:"<<p.m_Name<<" age:"<<p.m_Age<<endl;
}
// 存放自定义数据类型
void test2()
{
Person p1("xcs",22);
Person p2("tom",32);
Person p3("jerry",18);
vector<Person> v;
// 向容器中添加数据
v.push_back(p1);
v.push_back(p2);
v.push_back(p3);
// 遍历数据
for_each(v.begin(),v.end(),printPerson);
}5 vector.cpp-vector容器嵌套容器:
主要就是理清里面的嵌套逻辑
// vector容器嵌套容器
void test3()
{
vector<vector<int>> v;
//创建小容器
vector<int> v1;
vector<int> v2;
vector<int> v3;
// 小容器添加数据
v1.push_back(2);
v1.push_back(3);
v2.push_back(20);
v2.push_back(30);
v3.push_back(200);
v3.push_back(300);
//小容器添加到大容器中去
v.push_back(v1);
v.push_back(v2);
v.push_back(v3);
// 通过大容器,把所有的数据遍历一遍
for (vector<vector<int>>::iterator it = v.begin();it!=v.end();it++)
{
for (vector<int>::iterator vit = (*it).begin();vit!=(*it).end();vit++)
{
cout<<*vit<<" ";
}
cout<<endl;
}
}总结:
- 主要了解vector的一个创建,插入数据、遍历的过程并结合STL的个别算法
- vector中是可排序的类型如int,double,float等
// vector 排序
void test2()
{ vector<int> a;
a.push_back(10);
a.push_back(2);
a.push_back(30);
a.push_back(16);
a.push_back(14);
for (vector<int>::iterator it = a.begin(); it != a.end(); it++){
cout << *it << endl;
}
cout<<"===排序后==="<<endl;
sort(a.begin(), a.end());
for (vector<int>::iterator it = a.begin(); it != a.end(); it++){
cout << *it << endl;
}
}- vector中是自定义类型的排序
// vector中是自定义类型的排序
//自定义排序
struct student{
char name[10];
int score;
};
bool comp(const student &a, const student &b){
return a.score < b.score;
}
void test3()
{
vector<student> vectorStudents;
int n = 5;
while (n--){
student oneStudent;
string name;
int score;
cin >> name >> score;
strcpy(oneStudent.name, name.c_str());
oneStudent.score = score;
vectorStudents.push_back(oneStudent);
}
cout << "==========排序前================" << endl;
for (vector<student>::iterator it = vectorStudents.begin(); it != vectorStudents.end(); it++){
cout << "name: " << it->name << " score: " << it->score << endl;
}
sort(vectorStudents.begin(),vectorStudents.end(),comp);
cout << "===========排序后================" << endl;
for (vector<student>::iterator it = vectorStudents.begin(); it != vectorStudents.end(); it++){
cout << "name: " << it->name << " score: " << it->score << endl;
}
}//vector删除元素
void test5()
{
vector<int> a;
a.push_back(10);
a.push_back(2);
a.push_back(30);
a.push_back(16);
a.push_back(14);
for (vector<int>::iterator it = a.begin(); it != a.end(); it++){
cout << *it << endl;
}
cout<<"==="<<endl;
/* 1、remove并不是删除,仅仅是移除,要加上erase才能完成删除。
2、remove并不是删除指定位置的元素,而移除所有指定的元素。
3、用algorithm代替成员函数不是一个好的选择 */
remove(a.begin(),a.end(),30);
/*2.和find 函数结合删除*/ //erase 删除元素
vector<int>::iterator index = find(a.begin(),a.end(),30);
if(index != a.end())
{
a.erase(index);
}
/* 3.遍历vector删除*/
// for (vector<int>::iterator it = a.begin(); it != a.end(); it++){
// if(*it == 30)
// {
// it = a.erase(it);
// }
// }
for (vector<int>::iterator it = a.begin(); it != a.end(); it++){
cout << *it << endl;
}
}
三种方式:
- inser方式
- merge方式
- 挨个遍历去做
// 合并vector
void test7()
{
vector<int > a;
vector<int > b;
vector<int > c;
a.push_back(1);
b.push_back(2);
c.push_back(3);
//insert 方式
// c.insert(c.end(),a.begin(),a.end());
// c.insert(c.end(),b.begin(),b.end());
// merge 方式
sort(a.begin(),a.end());
sort(b.begin(),b.end());
c.resize(a.size()+b.size());
merge(a.begin(),a.end(),b.begin(),b.end(),c.begin());
//merge方式要注意三点:
/* 1、vec1,和vec2需要经过排序,merge只能合并排序后的集合,不然会报错。
2、vec3需要指定好大小,不然会报错。
3、merge的时候指定vec3的位置一定要从begin开始,如果指定了end,它会认为没有空间,当然,中间的位置我没有试,回头有空试一下。 */
outVec(c);
}vector<int> v:
//最大值:
int max = *max_element(v.begin(),v.end());
vector<int>::iterator max_it = max_element(v.begin(),v.end()); //则最大值为 *max_it 用这个可以用来求索引
//最小值:
int min = *min_element(v.begin(),v.end());int max_index = distance(a.begin(),max_element(a.begin(),a.end()));
int min_index = distance(a.begin(),min_element(a.begin(),a.end()));// 重载vector的<< 运算符 用于直接输出 vector<int>
ostream& operator<< (ostream& cout,vector<int>& a)
{
for(vector<int>::iterator it = a.begin();it != a.end();it++)
{
cout<<*it<<" ";
}
//cout<<"\n";
return cout;
}map和set是树形结构的关联式容器,使用平衡搜索树(红黑树)作为其底层结果,容器的元素是一个有序的序列。关联式容器是用来存储数据的,里面存储的是<key, value>结构的键值对,在数据检索时比序列式容器的效率更高。
键值对 键值对是用来表示具有一一对应关系的一种结构,该结构中一般包含两个成员变量key和value,key表示键值,value表示和key对应的信息。
map O(logN) 1.快速查找,通过key查找value。map支持下标访问符,即在[]中放入key,就可以找到与key对应的value。 2.附带作用,对key进行排序。在内部,map中的元素总是按照键值key进行比较排序的。
//map使用
void test12()
{ // map初始化
map<string ,string > m{
{"apple","苹果"},{"banana","香蕉"},{"orange","橘子"}
};
map<string ,string > m1;
//map中插入元素
//用pair的方式构造键值对
m1.insert(pair<string,string>("peach","桃子"));
//用make_pair的方式构造键值对
m1.insert(make_pair<string,string>("he","他"));
//用operator[] 插入元素
m1["she"] = "她";//类比python 的dict就是这个方式
//map 遍历
for(auto& e:m1)
{
cout<<e.first<<"--->"<<e.second<<endl;
}
//通过key访问value
cout<<m1["peach"]<<endl;
// map中的键值对key一定是唯一的,如果key存在将插入失败
auto ret = m1.insert(make_pair("peach", "桃子"));
if (ret.second)
cout << "<peach, 桃子>不在map中, 已经插入" << endl;
else
cout << "键值为peach的元素已经存在:" << ret.first->first << "--->" <<
ret.first->second << " 插入失败" << endl;
// 删除key为"apple"的元素
m.erase("apple");
}总结:
- map中的的元素是键值对。
- map中的key是唯一的,并且不能修改。
- 默认按照小于的方式对key进行比较。
- map中的元素如果用迭代器去遍历,可以得到一个有序的序列。
- map的底层为平衡搜索树(红黑树),查找效率比较高。
- 支持[]操作符,operator[]中实际进行插入查找。
// 数据的查找(包括判定这个关键字是否在map中出现)
void test(vector<string,string> m1)
{
/* 第一种:用count函数来判定关键字是否出现,其缺点是无法定位数据出现位置,由于map的特性,一对一的映射关系,就决定了count函数的返回值只有两个,要么是0,要么是1,出现的情况,当然是返回1了*/
cout<<m1.count("peach")<<endl;
cout<<m1.count("peache")<<endl;
/* 第二种:用find函数来定位数据出现位置,它返回的一个迭代器,当数据出现时,它返回数据所在位置的迭代器,如果map中没有要查找的数据,它返回的迭代器等于end函数返回的迭代器,程序说明 */
map<string,string>::iterator it,it1;
it = m1.find("peach");
it1 = m1.find("peache");
if (it1 !=m1.end())
{
cout<<"find!"<<endl;
}
else
{
cout<<"not find"<<endl;
}
}//map中插入元素
void test(vector<string,string> &m1)
{
//用pair的方式构造键值对
m1.insert(pair<string,string>("peach","桃子"));
//用make_pair的方式构造键值对
m1.insert(make_pair<string,string>("he","他"));
//用operator[] 插入元素
m1["she"] = "她";//类比python 的dict就是这个方式
} 清空map中的数据可以用clear()函数,判定map中是否有数据可以用empty()函数,它返回true则说明是空map
unordered_set可以把它想象成一个集合,它提供了几个函数让我们可以增删查: unordered_set::insert unordered_set::find 会返回一个迭代器,这个迭代器指向和参数哈希值匹配的元素,如果没有匹配的元素,会返回这个容器的结束迭代器 unordered_set::erase
unorederd_set::end 返回结束的迭代器
这个unorder暗示着,这两个头文件中类的底层实现----Hash。 也是因为如此,你才可以在声明这些unordered模版类的时候,传入一个自定义的哈希函数,准确的说是哈希函数子(hash function object)。
函数在台式机的 learningC++_vscode test.cpp 下的 int getFiles(string,vector);
在C++中输出要控制小数点的位数需要用到头文件iomanip中的setprecision(n)和setiosflags(ios::fixed)
其中setprecision(n) 设置浮点数的有效数字为n
setiosflags(ios::fixed) 设置浮点数以固定的小数位数显示
#include<iostream>
#include<iomanip>
using namespace std;
int main()
{
double a=3.14159265358;
cout<<a<<endl; //默认 输出为3.14159
//加入setprecision(n) 设置浮点数有效数字
cout<<setprecision(3)<<a<<endl; //将精度改为3(即有效数字三位) 输出3.14
cout<<setprecision(10)<<a<<endl; //将精度改为10 输出3.141592654
//加入setiosflags(ios::fixed) 设置浮点数以固定的小数位数显示
cout<<setiosflags(ios::fixed)<<setprecision(2)<<a<<endl;
//控制精度为小数位 setprecision(3)即保留小数点2位 输出3.14
cout<<a<<endl; //fixed和setprecision的作用还在,依然显示3.14
return 0;
}通过已知的(x,y)点来用最小二乘法拟合函数f(x)
// 最小二乘法
class LSquare
{
public:
double *a;
int n,ex;
LSquare(vector<double> x,vector<double> y,int n,int ex)
{ this->n = n;
this->ex = ex;
memset(a,0,sizeof(double)*ex);
L_Sq(x,y,a,n,ex);
}
double f(double x)
{
double res;
res = 0;
for (int i = 0; i < ex+1; i++)
{
res += pow(x,i)* a[i];
}
return res;
}
// 最小二乘法
// xy的次方和
double RelateMutiXY(vector<double> x,vector<double> y,int n,int ex)
{ double res;
res = 0.0;
for (int j = 0; j < n; j++)
{
res += pow(x[j],ex) * y[j];
}
return res;
}
// x 的次方和
double RelatePow(vector<double> x,int n,int ex)
{ double res;
res = 0.0;
for (int i = 0; i < n; i++)
{
res += pow(x[i],ex);
}
return res;
}
void CalEquation(double **AB,double a[],int ex)
{
for (int k = 0; k < ex+1; k++)
{
for (int i = 0; i < ex+1; i++)
{
if(i!=k)
{
double p=0;
if (AB[k][k]!=0)
{
p = AB[i][k]*1.0/ AB[k][k];
}
for (int j = k; j < ex+2; j++)
{
AB[i][j] -= AB[k][j] * p;
}
}
}
}
for (int i = 0; i < ex+1; i++)
{
a[i] = AB[i][ex+1]*1.0/AB[i][i];
}
}
void L_Sq(vector<double> x,vector<double> y,double a[],int n,int ex)
{ // 参数ex 表示 拟合的多项式的最高次幂
// double A[ex+1][ex+1];
// doubel B[ex+1][1];
//double AB[ex+1][ex+2]; // 这里参考增广矩阵
// 构造矩阵相乘 A*X = Y (这里A,X,Y是最后求导得到的 矩阵)
// 这里就是 A*a = B 求解a,a为系数矩阵
//构造矩阵A
double **AB;
AB = new double*[ex+1];
for(int i=0;i<ex+1;i++)
{ AB[i] = new double[ex+2];
for (int j = 0; j < ex+1; j++)
{ //cout<<RelatePow(x,n,i+j)<<endl;
AB[i][j] = RelatePow(x,n,i+j);
}
AB[i][ex+1] = RelateMutiXY(x,y,n,i);
}
AB[0][0] = n;
CalEquation(AB,a,ex); // 解A*X = Y (A|Y)--初等变换->(E|X)
}
};
void test13()
{
vector<double> x{0,0.25,0,5,0.75};
vector<double> y{1,1.283,1.649,2.212,2.178};
LSquare ls(x,y,5,2);
for (int i = 0; i < 3; i++)
{
cout<<ls.a[i]<<endl;
}
cout<<ls.f(0.25)<<endl;
}PyObject *pModule = PyImport_ImportModule("test") // 导入模块名会报错,我也不知道为啥