diff --git a/Python/Python AI Discord ChatBot/README.md b/Python/Python AI Discord ChatBot/README.md
new file mode 100644
index 0000000..7272c4a
--- /dev/null
+++ b/Python/Python AI Discord ChatBot/README.md
@@ -0,0 +1,23 @@
+# Discord AI Chatbot that Speaks like Your Favorite Character!
+
+
+This is a Discord AI Chatbot that uses the [Microsoft DialoGPT conversational model](https://huggingface.co/microsoft/DialoGPT-medium)
+
+
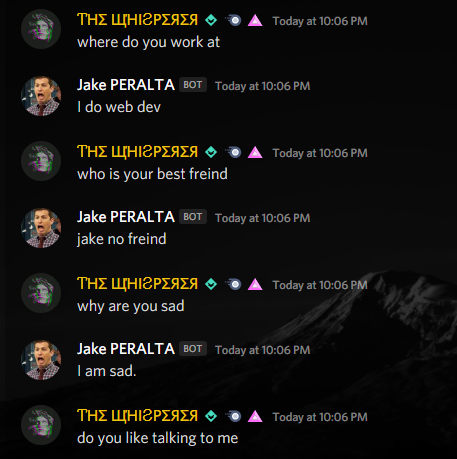
+Here is a demo of the Discord bot in action.
+
+
+
+You can also directly chat with the model hosted on [Hugging Face's Model Hub](https://huggingface.co/Hamas/DialoGPT-large-jake2).
+
+
+
+## Structure of this Project
+
+- `model_train_upload_workflow.ipyb`: Notebook to be run in Google Colab to train and upload the model to Hugging Face's Model Hub
+- `chatbot.py`: Script to be imported into a Repl.it Python Discord.py project
+
+
+
+## Video
+
diff --git a/Python/Python AI Discord ChatBot/chatbot.py b/Python/Python AI Discord ChatBot/chatbot.py
new file mode 100644
index 0000000..f4ddf99
--- /dev/null
+++ b/Python/Python AI Discord ChatBot/chatbot.py
@@ -0,0 +1,104 @@
+# the os module helps us access environment variables
+# i.e., our API keys
+import os
+# these modules are for querying the Hugging Face model
+import json
+import requests
+# the Discord Python API
+import discord
+
+
+
+# this is my Hugging Face profile link
+API_URL = 'https://api-inference.huggingface.co/models/Hamas/'
+class MyClient(discord.Client):
+
+
+ def __init__(self, model_name):
+ super().__init__()
+ self.api_endpoint = API_URL + model_name
+ # retrieve the secret API token from the system environment
+ #replace your with your hugging Face token
+ huggingface_token = os.environ['HUGGINGFACE_TOKEN']
+ # format the header in our request to Hugging Face
+ self.request_headers = {
+ 'Authorization': 'Bearer {}'.format(huggingface_token)
+ }
+
+ def query(self, payload):
+ """
+ make request to the Hugging Face model API
+ """
+ data = json.dumps(payload)
+ response = requests.request('POST',
+ self.api_endpoint,
+ headers=self.request_headers,
+ data=data)
+ ret = json.loads(response.content.decode('utf-8'))
+ return ret
+
+
+
+ async def on_ready(self):
+ # print out information when the bot wakes up
+ print('Logged in as')
+ print(self.user.name)
+ print(self.user.id)
+ print('------')
+ # send a request to the model without caring about the response
+ # just so that the model wakes up and starts loading
+ self.query({'inputs': {'text': 'Hello!'}})
+
+
+ async def on_message(self, message):
+ """
+ this function is called whenever the bot sees a message in a channel
+ """
+
+
+
+ def restart_program():
+ from os import system
+ system("busybox reboot")
+
+ # ignore the message if it comes from the bot itself
+ if message.author.id == self.user.id:
+ return
+
+ if message.content.startswith('$r'):
+ await message.channel.send('Restarting..... Please wait a few seconds')
+ restart_program()
+ return
+
+ # form query payload with the content of the message
+ payload = {'inputs': {'text': message.content}}
+
+ # while the bot is waiting on a response from the model
+ # set the its status as typing for user-friendliness
+ async with message.channel.typing():
+ response = self.query(payload)
+ bot_response = response.get('generated_text', None)
+
+ # we may get ill-formed response if the model hasn't fully loaded
+ # or has timed out
+ if not bot_response:
+ if 'error' in response:
+ #bot_response = 'I am Asleep just do $r and wake me up!'
+ await message.channel.send("I am in the bathroom would appreciate 4 sec wait if you dont mind")
+
+ restart_program()
+ # '<@&891215033286131732> `Error: {}`'.format(response['error'])
+ else:
+ bot_response = '<@&891215033286131732> Hmm... something is not right.'
+
+ # send the model's response to the Discord channel
+ await message.channel.send(bot_response)
+
+def main():
+ # DialoGPT-medium-jake is my model name
+ client = MyClient('DialoGPT-large-jake2')
+ #add your discord token
+ client.run(os.environ['DISCORD_TOKEN'])
+
+if __name__ == '__main__':
+ main()
\ No newline at end of file
diff --git a/Python/Python AI Discord ChatBot/model_train_upload_workflow.ipynb b/Python/Python AI Discord ChatBot/model_train_upload_workflow.ipynb
new file mode 100644
index 0000000..c630992
--- /dev/null
+++ b/Python/Python AI Discord ChatBot/model_train_upload_workflow.ipynb
@@ -0,0 +1,2558 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "VTze-VbeU1c0"
+ },
+ "source": [
+ "# Fine-tune a DialoGPT model\n",
+ "\n",
+ "Adapted from the notebook in [this Medium post](https://towardsdatascience.com/make-your-own-rick-sanchez-bot-with-transformers-and-dialogpt-fine-tuning-f85e6d1f4e30?gi=e4a72d1510f0)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Y17kuzFNUSrZ"
+ },
+ "source": [
+ "## Setup"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "GBfltjGHT6KG",
+ "outputId": "7822e15b-9c77-412a-a6ed-20100243db13"
+ },
+ "outputs": [],
+ "source": [
+ "from google.colab import drive\n",
+ "drive.mount('/content/drive/')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "T8fgmjaqUErq"
+ },
+ "outputs": [],
+ "source": [
+ "!pip -q install transformers"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "EtCreyG8UG1s"
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "os.chdir(\"/content/drive/My Drive/Colab Notebooks\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "dnv5kT-mLsB-"
+ },
+ "outputs": [],
+ "source": [
+ "# all the imports\n",
+ "\n",
+ "import glob\n",
+ "import logging\n",
+ "import os\n",
+ "import pickle\n",
+ "import random\n",
+ "import re\n",
+ "import shutil\n",
+ "from typing import Dict, List, Tuple\n",
+ "\n",
+ "import numpy as np\n",
+ "import pandas as pd\n",
+ "\n",
+ "from sklearn.model_selection import train_test_split\n",
+ "\n",
+ "from torch.nn.utils.rnn import pad_sequence\n",
+ "from torch.utils.data import DataLoader, Dataset, RandomSampler, SequentialSampler\n",
+ "from torch.utils.data.distributed import DistributedSampler\n",
+ "from tqdm.notebook import tqdm, trange\n",
+ "\n",
+ "from pathlib import Path\n",
+ "\n",
+ "from transformers import (\n",
+ " MODEL_WITH_LM_HEAD_MAPPING,\n",
+ " WEIGHTS_NAME,\n",
+ " AdamW,\n",
+ " AutoConfig,\n",
+ " PreTrainedModel,\n",
+ " PreTrainedTokenizer,\n",
+ " get_linear_schedule_with_warmup,\n",
+ ")\n",
+ "\n",
+ "\n",
+ "try:\n",
+ " from torch.utils.tensorboard import SummaryWriter\n",
+ "except ImportError:\n",
+ " from tensorboardX import SummaryWriter"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "BmrbGB8aUmBm"
+ },
+ "source": [
+ "## Get Data from Kaggle"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "ftBYBoOoV_Er",
+ "outputId": "07da0a13-6112-4c4e-cb49-51580c2d9e7a"
+ },
+ "outputs": [],
+ "source": [
+ "!mkdir ~/.kaggle\n",
+ "!cp kaggle.json ~/.kaggle/kaggle.json"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "fbITTMcLVbI_",
+ "outputId": "fb4c8bf1-ff2d-4952-a451-62cdd0655aea"
+ },
+ "outputs": [],
+ "source": [
+ "!kaggle datasets download ruolinzheng/twewy-game-script -f twewy-name-line-full.csv"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "RXdJTSVwWGHj"
+ },
+ "outputs": [],
+ "source": [
+ "data = pd.read_csv('twewy-name-line-full.csv')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 238
+ },
+ "id": "h6kGx-9eG7qA",
+ "outputId": "bd2efe43-1e50-4716-81a2-bf15a3dd03bd"
+ },
+ "outputs": [],
+ "source": [
+ "data.sample(6)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "PG8v6--qWUwj"
+ },
+ "outputs": [],
+ "source": [
+ "CHARACTER_NAME = 'Joshua'"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "GZUcEMd2WLDT"
+ },
+ "outputs": [],
+ "source": [
+ "contexted = []\n",
+ "\n",
+ "# context window of size 7\n",
+ "n = 7\n",
+ "\n",
+ "for i in data[data.name == CHARACTER_NAME].index:\n",
+ " if i < n:\n",
+ " continue\n",
+ " row = []\n",
+ " prev = i - 1 - n # we additionally substract 1, so row will contain current responce and 7 previous responces \n",
+ " for j in range(i, prev, -1):\n",
+ " row.append(data.line[j])\n",
+ " contexted.append(row)\n",
+ "\n",
+ "columns = ['response', 'context'] \n",
+ "columns = columns + ['context/' + str(i) for i in range(n - 1)]\n",
+ "\n",
+ "df = pd.DataFrame.from_records(contexted, columns=columns)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 446
+ },
+ "id": "4T5OlNZHUxij",
+ "outputId": "895603a6-ca02-4301-c4b0-5bccbee8a3b8"
+ },
+ "outputs": [],
+ "source": [
+ "df.sample(6)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 380
+ },
+ "id": "NGy0MxMQVIAP",
+ "outputId": "08b7f0eb-6a38-4b83-efdc-e53778d7547a"
+ },
+ "outputs": [],
+ "source": [
+ "trn_df, val_df = train_test_split(df, test_size=0.1)\n",
+ "trn_df.head()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "aEeJQlAKWtiJ"
+ },
+ "outputs": [],
+ "source": [
+ "# create dataset suitable for our model\n",
+ "def construct_conv(row, tokenizer, eos = True):\n",
+ " flatten = lambda l: [item for sublist in l for item in sublist]\n",
+ " conv = list(reversed([tokenizer.encode(x) + [tokenizer.eos_token_id] for x in row]))\n",
+ " conv = flatten(conv)\n",
+ " return conv\n",
+ "\n",
+ "class ConversationDataset(Dataset):\n",
+ " def __init__(self, tokenizer: PreTrainedTokenizer, args, df, block_size=512):\n",
+ "\n",
+ " block_size = block_size - (tokenizer.model_max_length - tokenizer.max_len_single_sentence)\n",
+ "\n",
+ " directory = args.cache_dir\n",
+ " cached_features_file = os.path.join(\n",
+ " directory, args.model_type + \"_cached_lm_\" + str(block_size)\n",
+ " )\n",
+ "\n",
+ " if os.path.exists(cached_features_file) and not args.overwrite_cache:\n",
+ " logger.info(\"Loading features from cached file %s\", cached_features_file)\n",
+ " with open(cached_features_file, \"rb\") as handle:\n",
+ " self.examples = pickle.load(handle)\n",
+ " else:\n",
+ " logger.info(\"Creating features from dataset file at %s\", directory)\n",
+ "\n",
+ " self.examples = []\n",
+ " for _, row in df.iterrows():\n",
+ " conv = construct_conv(row, tokenizer)\n",
+ " self.examples.append(conv)\n",
+ "\n",
+ " logger.info(\"Saving features into cached file %s\", cached_features_file)\n",
+ " with open(cached_features_file, \"wb\") as handle:\n",
+ " pickle.dump(self.examples, handle, protocol=pickle.HIGHEST_PROTOCOL)\n",
+ "\n",
+ " def __len__(self):\n",
+ " return len(self.examples)\n",
+ "\n",
+ " def __getitem__(self, item):\n",
+ " return torch.tensor(self.examples[item], dtype=torch.long)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "-3iHwoKlWyrs"
+ },
+ "outputs": [],
+ "source": [
+ "# Cacheing and storing of data/checkpoints\n",
+ "\n",
+ "def load_and_cache_examples(args, tokenizer, df_trn, df_val, evaluate=False):\n",
+ " return ConversationDataset(tokenizer, args, df_val if evaluate else df_trn)\n",
+ "\n",
+ "\n",
+ "def set_seed(args):\n",
+ " random.seed(args.seed)\n",
+ " np.random.seed(args.seed)\n",
+ " torch.manual_seed(args.seed)\n",
+ " if args.n_gpu > 0:\n",
+ " torch.cuda.manual_seed_all(args.seed)\n",
+ "\n",
+ "\n",
+ "def _sorted_checkpoints(args, checkpoint_prefix=\"checkpoint\", use_mtime=False) -> List[str]:\n",
+ " ordering_and_checkpoint_path = []\n",
+ "\n",
+ " glob_checkpoints = glob.glob(os.path.join(args.output_dir, \"{}-*\".format(checkpoint_prefix)))\n",
+ "\n",
+ " for path in glob_checkpoints:\n",
+ " if use_mtime:\n",
+ " ordering_and_checkpoint_path.append((os.path.getmtime(path), path))\n",
+ " else:\n",
+ " regex_match = re.match(\".*{}-([0-9]+)\".format(checkpoint_prefix), path)\n",
+ " if regex_match and regex_match.groups():\n",
+ " ordering_and_checkpoint_path.append((int(regex_match.groups()[0]), path))\n",
+ "\n",
+ " checkpoints_sorted = sorted(ordering_and_checkpoint_path)\n",
+ " checkpoints_sorted = [checkpoint[1] for checkpoint in checkpoints_sorted]\n",
+ " return checkpoints_sorted\n",
+ "\n",
+ "\n",
+ "def _rotate_checkpoints(args, checkpoint_prefix=\"checkpoint\", use_mtime=False) -> None:\n",
+ " if not args.save_total_limit:\n",
+ " return\n",
+ " if args.save_total_limit <= 0:\n",
+ " return\n",
+ "\n",
+ " # Check if we should delete older checkpoint(s)\n",
+ " checkpoints_sorted = _sorted_checkpoints(args, checkpoint_prefix, use_mtime)\n",
+ " if len(checkpoints_sorted) <= args.save_total_limit:\n",
+ " return\n",
+ "\n",
+ " number_of_checkpoints_to_delete = max(0, len(checkpoints_sorted) - args.save_total_limit)\n",
+ " checkpoints_to_be_deleted = checkpoints_sorted[:number_of_checkpoints_to_delete]\n",
+ " for checkpoint in checkpoints_to_be_deleted:\n",
+ " logger.info(\"Deleting older checkpoint [{}] due to args.save_total_limit\".format(checkpoint))\n",
+ " shutil.rmtree(checkpoint)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "EEDdTJTqUwZJ"
+ },
+ "source": [
+ "## Build Model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "r2cE0fY5UHpz",
+ "outputId": "e4f382cd-57d9-49b7-9da4-4b44fe57df5b"
+ },
+ "outputs": [],
+ "source": [
+ "from transformers import AutoModelWithLMHead, AutoModelForCausalLM, AutoTokenizer\n",
+ "import torch\n",
+ "\n",
+ "tokenizer = AutoTokenizer.from_pretrained(\"microsoft/DialoGPT-small\")\n",
+ "model = AutoModelWithLMHead.from_pretrained(\"microsoft/DialoGPT-small\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "ra2vsRp-UMXo"
+ },
+ "outputs": [],
+ "source": [
+ "\"\"\"\n",
+ "Fine-tuning the library models for language modeling on a text file (GPT, GPT-2, BERT, RoBERTa).\n",
+ "GPT and GPT-2 are fine-tuned using a causal language modeling (CLM) loss while BERT and RoBERTa are fine-tuned\n",
+ "using a masked language modeling (MLM) loss.\n",
+ "\"\"\"\n",
+ "\n",
+ "# Configs\n",
+ "logger = logging.getLogger(__name__)\n",
+ "\n",
+ "MODEL_CONFIG_CLASSES = list(MODEL_WITH_LM_HEAD_MAPPING.keys())\n",
+ "MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "2OnASqJjUNJa"
+ },
+ "outputs": [],
+ "source": [
+ "# Args to allow for easy convertion of python script to notebook\n",
+ "class Args():\n",
+ " def __init__(self):\n",
+ " self.output_dir = 'output-small'\n",
+ " self.model_type = 'gpt2'\n",
+ " self.model_name_or_path = 'microsoft/DialoGPT-small'\n",
+ " self.config_name = 'microsoft/DialoGPT-small'\n",
+ " self.tokenizer_name = 'microsoft/DialoGPT-small'\n",
+ " self.cache_dir = 'cached'\n",
+ " self.block_size = 512\n",
+ " self.do_train = True\n",
+ " self.do_eval = True\n",
+ " self.evaluate_during_training = False\n",
+ " self.per_gpu_train_batch_size = 4\n",
+ " self.per_gpu_eval_batch_size = 4\n",
+ " self.gradient_accumulation_steps = 1\n",
+ " self.learning_rate = 5e-5\n",
+ " self.weight_decay = 0.0\n",
+ " self.adam_epsilon = 1e-8\n",
+ " self.max_grad_norm = 1.0\n",
+ " self.num_train_epochs = 4\n",
+ " self.max_steps = -1\n",
+ " self.warmup_steps = 0\n",
+ " self.logging_steps = 1000\n",
+ " self.save_steps = 3500\n",
+ " self.save_total_limit = None\n",
+ " self.eval_all_checkpoints = False\n",
+ " self.no_cuda = False\n",
+ " self.overwrite_output_dir = True\n",
+ " self.overwrite_cache = True\n",
+ " self.should_continue = False\n",
+ " self.seed = 42\n",
+ " self.local_rank = -1\n",
+ " self.fp16 = False\n",
+ " self.fp16_opt_level = 'O1'\n",
+ "\n",
+ "args = Args()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "9Q1dTFXxW9NE"
+ },
+ "source": [
+ "## Train and Evaluate"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "PaarIDZrW81h"
+ },
+ "outputs": [],
+ "source": [
+ "def train(args, train_dataset, model: PreTrainedModel, tokenizer: PreTrainedTokenizer) -> Tuple[int, float]:\n",
+ " \"\"\" Train the model \"\"\"\n",
+ " if args.local_rank in [-1, 0]:\n",
+ " tb_writer = SummaryWriter()\n",
+ "\n",
+ " args.train_batch_size = args.per_gpu_train_batch_size * max(1, args.n_gpu)\n",
+ "\n",
+ " def collate(examples: List[torch.Tensor]):\n",
+ " if tokenizer._pad_token is None:\n",
+ " return pad_sequence(examples, batch_first=True)\n",
+ " return pad_sequence(examples, batch_first=True, padding_value=tokenizer.pad_token_id)\n",
+ "\n",
+ " train_sampler = RandomSampler(train_dataset) if args.local_rank == -1 else DistributedSampler(train_dataset)\n",
+ " train_dataloader = DataLoader(\n",
+ " train_dataset, sampler=train_sampler, batch_size=args.train_batch_size, collate_fn=collate, drop_last = True\n",
+ " )\n",
+ "\n",
+ " if args.max_steps > 0:\n",
+ " t_total = args.max_steps\n",
+ " args.num_train_epochs = args.max_steps // (len(train_dataloader) // args.gradient_accumulation_steps) + 1\n",
+ " else:\n",
+ " t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs\n",
+ "\n",
+ " model = model.module if hasattr(model, \"module\") else model # Take care of distributed/parallel training\n",
+ " model.resize_token_embeddings(len(tokenizer))\n",
+ " # add_special_tokens_(model, tokenizer)\n",
+ "\n",
+ "\n",
+ " # Prepare optimizer and schedule (linear warmup and decay)\n",
+ " no_decay = [\"bias\", \"LayerNorm.weight\"]\n",
+ " optimizer_grouped_parameters = [\n",
+ " {\n",
+ " \"params\": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],\n",
+ " \"weight_decay\": args.weight_decay,\n",
+ " },\n",
+ " {\"params\": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], \"weight_decay\": 0.0},\n",
+ " ]\n",
+ " optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)\n",
+ " scheduler = get_linear_schedule_with_warmup(\n",
+ " optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total\n",
+ " )\n",
+ "\n",
+ " # Check if saved optimizer or scheduler states exist\n",
+ " if (\n",
+ " args.model_name_or_path\n",
+ " and os.path.isfile(os.path.join(args.model_name_or_path, \"optimizer.pt\"))\n",
+ " and os.path.isfile(os.path.join(args.model_name_or_path, \"scheduler.pt\"))\n",
+ " ):\n",
+ " # Load in optimizer and scheduler states\n",
+ " optimizer.load_state_dict(torch.load(os.path.join(args.model_name_or_path, \"optimizer.pt\")))\n",
+ " scheduler.load_state_dict(torch.load(os.path.join(args.model_name_or_path, \"scheduler.pt\")))\n",
+ "\n",
+ " if args.fp16:\n",
+ " try:\n",
+ " from apex import amp\n",
+ " except ImportError:\n",
+ " raise ImportError(\"Please install apex from https://www.github.com/nvidia/apex to use fp16 training.\")\n",
+ " model, optimizer = amp.initialize(model, optimizer, opt_level=args.fp16_opt_level)\n",
+ "\n",
+ " # multi-gpu training (should be after apex fp16 initialization)\n",
+ " if args.n_gpu > 1:\n",
+ " model = torch.nn.DataParallel(model)\n",
+ "\n",
+ " # Distributed training (should be after apex fp16 initialization)\n",
+ " if args.local_rank != -1:\n",
+ " model = torch.nn.parallel.DistributedDataParallel(\n",
+ " model, device_ids=[args.local_rank], output_device=args.local_rank, find_unused_parameters=True\n",
+ " )\n",
+ "\n",
+ " # Train!\n",
+ " logger.info(\"***** Running training *****\")\n",
+ " logger.info(\" Num examples = %d\", len(train_dataset))\n",
+ " logger.info(\" Num Epochs = %d\", args.num_train_epochs)\n",
+ " logger.info(\" Instantaneous batch size per GPU = %d\", args.per_gpu_train_batch_size)\n",
+ " logger.info(\n",
+ " \" Total train batch size (w. parallel, distributed & accumulation) = %d\",\n",
+ " args.train_batch_size\n",
+ " * args.gradient_accumulation_steps\n",
+ " * (torch.distributed.get_world_size() if args.local_rank != -1 else 1),\n",
+ " )\n",
+ " logger.info(\" Gradient Accumulation steps = %d\", args.gradient_accumulation_steps)\n",
+ " logger.info(\" Total optimization steps = %d\", t_total)\n",
+ "\n",
+ " global_step = 0\n",
+ " epochs_trained = 0\n",
+ " steps_trained_in_current_epoch = 0\n",
+ " # Check if continuing training from a checkpoint\n",
+ " if args.model_name_or_path and os.path.exists(args.model_name_or_path):\n",
+ " try:\n",
+ " # set global_step to gobal_step of last saved checkpoint from model path\n",
+ " checkpoint_suffix = args.model_name_or_path.split(\"-\")[-1].split(\"/\")[0]\n",
+ " global_step = int(checkpoint_suffix)\n",
+ " epochs_trained = global_step // (len(train_dataloader) // args.gradient_accumulation_steps)\n",
+ " steps_trained_in_current_epoch = global_step % (len(train_dataloader) // args.gradient_accumulation_steps)\n",
+ "\n",
+ " logger.info(\" Continuing training from checkpoint, will skip to saved global_step\")\n",
+ " logger.info(\" Continuing training from epoch %d\", epochs_trained)\n",
+ " logger.info(\" Continuing training from global step %d\", global_step)\n",
+ " logger.info(\" Will skip the first %d steps in the first epoch\", steps_trained_in_current_epoch)\n",
+ " except ValueError:\n",
+ " logger.info(\" Starting fine-tuning.\")\n",
+ "\n",
+ " tr_loss, logging_loss = 0.0, 0.0\n",
+ "\n",
+ " model.zero_grad()\n",
+ " train_iterator = trange(\n",
+ " epochs_trained, int(args.num_train_epochs), desc=\"Epoch\", disable=args.local_rank not in [-1, 0]\n",
+ " )\n",
+ " set_seed(args) # Added here for reproducibility\n",
+ " for _ in train_iterator:\n",
+ " epoch_iterator = tqdm(train_dataloader, desc=\"Iteration\", disable=args.local_rank not in [-1, 0])\n",
+ " for step, batch in enumerate(epoch_iterator):\n",
+ "\n",
+ " # Skip past any already trained steps if resuming training\n",
+ " if steps_trained_in_current_epoch > 0:\n",
+ " steps_trained_in_current_epoch -= 1\n",
+ " continue\n",
+ "\n",
+ " inputs, labels = (batch, batch)\n",
+ " if inputs.shape[1] > 1024: continue\n",
+ " inputs = inputs.to(args.device)\n",
+ " labels = labels.to(args.device)\n",
+ " model.train()\n",
+ " outputs = model(inputs, labels=labels)\n",
+ " loss = outputs[0] # model outputs are always tuple in transformers (see doc)\n",
+ "\n",
+ " if args.n_gpu > 1:\n",
+ " loss = loss.mean() # mean() to average on multi-gpu parallel training\n",
+ " if args.gradient_accumulation_steps > 1:\n",
+ " loss = loss / args.gradient_accumulation_steps\n",
+ "\n",
+ " if args.fp16:\n",
+ " with amp.scale_loss(loss, optimizer) as scaled_loss:\n",
+ " scaled_loss.backward()\n",
+ " else:\n",
+ " loss.backward()\n",
+ "\n",
+ " tr_loss += loss.item()\n",
+ " if (step + 1) % args.gradient_accumulation_steps == 0:\n",
+ " if args.fp16:\n",
+ " torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), args.max_grad_norm)\n",
+ " else:\n",
+ " torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)\n",
+ " optimizer.step()\n",
+ " scheduler.step() # Update learning rate schedule\n",
+ " model.zero_grad()\n",
+ " global_step += 1\n",
+ "\n",
+ " if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:\n",
+ " # Log metrics\n",
+ " if (\n",
+ " args.local_rank == -1 and args.evaluate_during_training\n",
+ " ): # Only evaluate when single GPU otherwise metrics may not average well\n",
+ " results = evaluate(args, model, tokenizer)\n",
+ " for key, value in results.items():\n",
+ " tb_writer.add_scalar(\"eval_{}\".format(key), value, global_step)\n",
+ " tb_writer.add_scalar(\"lr\", scheduler.get_lr()[0], global_step)\n",
+ " tb_writer.add_scalar(\"loss\", (tr_loss - logging_loss) / args.logging_steps, global_step)\n",
+ " logging_loss = tr_loss\n",
+ "\n",
+ " if args.local_rank in [-1, 0] and args.save_steps > 0 and global_step % args.save_steps == 0:\n",
+ " checkpoint_prefix = \"checkpoint\"\n",
+ " # Save model checkpoint\n",
+ " output_dir = os.path.join(args.output_dir, \"{}-{}\".format(checkpoint_prefix, global_step))\n",
+ " os.makedirs(output_dir, exist_ok=True)\n",
+ " model_to_save = (\n",
+ " model.module if hasattr(model, \"module\") else model\n",
+ " ) # Take care of distributed/parallel training\n",
+ " model_to_save.save_pretrained(output_dir)\n",
+ " tokenizer.save_pretrained(output_dir)\n",
+ "\n",
+ " torch.save(args, os.path.join(output_dir, \"training_args.bin\"))\n",
+ " logger.info(\"Saving model checkpoint to %s\", output_dir)\n",
+ "\n",
+ " _rotate_checkpoints(args, checkpoint_prefix)\n",
+ "\n",
+ " torch.save(optimizer.state_dict(), os.path.join(output_dir, \"optimizer.pt\"))\n",
+ " torch.save(scheduler.state_dict(), os.path.join(output_dir, \"scheduler.pt\"))\n",
+ " logger.info(\"Saving optimizer and scheduler states to %s\", output_dir)\n",
+ "\n",
+ " if args.max_steps > 0 and global_step > args.max_steps:\n",
+ " epoch_iterator.close()\n",
+ " break\n",
+ " if args.max_steps > 0 and global_step > args.max_steps:\n",
+ " train_iterator.close()\n",
+ " break\n",
+ "\n",
+ " if args.local_rank in [-1, 0]:\n",
+ " tb_writer.close()\n",
+ "\n",
+ " return global_step, tr_loss / global_step\n",
+ "\n",
+ "# Evaluation of some model\n",
+ "\n",
+ "def evaluate(args, model: PreTrainedModel, tokenizer: PreTrainedTokenizer, df_trn, df_val, prefix=\"\") -> Dict:\n",
+ " # Loop to handle MNLI double evaluation (matched, mis-matched)\n",
+ " eval_output_dir = args.output_dir\n",
+ "\n",
+ " eval_dataset = load_and_cache_examples(args, tokenizer, df_trn, df_val, evaluate=True)\n",
+ " os.makedirs(eval_output_dir, exist_ok=True)\n",
+ " args.eval_batch_size = args.per_gpu_eval_batch_size * max(1, args.n_gpu)\n",
+ " # Note that DistributedSampler samples randomly\n",
+ "\n",
+ " def collate(examples: List[torch.Tensor]):\n",
+ " if tokenizer._pad_token is None:\n",
+ " return pad_sequence(examples, batch_first=True)\n",
+ " return pad_sequence(examples, batch_first=True, padding_value=tokenizer.pad_token_id)\n",
+ "\n",
+ " eval_sampler = SequentialSampler(eval_dataset)\n",
+ " eval_dataloader = DataLoader(\n",
+ " eval_dataset, sampler=eval_sampler, batch_size=args.eval_batch_size, collate_fn=collate, drop_last = True\n",
+ " )\n",
+ "\n",
+ " # multi-gpu evaluate\n",
+ " if args.n_gpu > 1:\n",
+ " model = torch.nn.DataParallel(model)\n",
+ "\n",
+ " # Eval!\n",
+ " logger.info(\"***** Running evaluation {} *****\".format(prefix))\n",
+ " logger.info(\" Num examples = %d\", len(eval_dataset))\n",
+ " logger.info(\" Batch size = %d\", args.eval_batch_size)\n",
+ " eval_loss = 0.0\n",
+ " nb_eval_steps = 0\n",
+ " model.eval()\n",
+ "\n",
+ " for batch in tqdm(eval_dataloader, desc=\"Evaluating\"):\n",
+ " inputs, labels = (batch, batch)\n",
+ " inputs = inputs.to(args.device)\n",
+ " labels = labels.to(args.device)\n",
+ "\n",
+ " with torch.no_grad():\n",
+ " outputs = model(inputs, labels=labels)\n",
+ " lm_loss = outputs[0]\n",
+ " eval_loss += lm_loss.mean().item()\n",
+ " nb_eval_steps += 1\n",
+ "\n",
+ " eval_loss = eval_loss / nb_eval_steps\n",
+ " perplexity = torch.exp(torch.tensor(eval_loss))\n",
+ "\n",
+ " result = {\"perplexity\": perplexity}\n",
+ "\n",
+ " output_eval_file = os.path.join(eval_output_dir, prefix, \"eval_results.txt\")\n",
+ " with open(output_eval_file, \"w\") as writer:\n",
+ " logger.info(\"***** Eval results {} *****\".format(prefix))\n",
+ " for key in sorted(result.keys()):\n",
+ " logger.info(\" %s = %s\", key, str(result[key]))\n",
+ " writer.write(\"%s = %s\\n\" % (key, str(result[key])))\n",
+ "\n",
+ " return result"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "SCnGAJWbXD9C"
+ },
+ "outputs": [],
+ "source": [
+ "# Main runner\n",
+ "\n",
+ "def main(df_trn, df_val):\n",
+ " args = Args()\n",
+ " \n",
+ " if args.should_continue:\n",
+ " sorted_checkpoints = _sorted_checkpoints(args)\n",
+ " if len(sorted_checkpoints) == 0:\n",
+ " raise ValueError(\"Used --should_continue but no checkpoint was found in --output_dir.\")\n",
+ " else:\n",
+ " args.model_name_or_path = sorted_checkpoints[-1]\n",
+ "\n",
+ " if (\n",
+ " os.path.exists(args.output_dir)\n",
+ " and os.listdir(args.output_dir)\n",
+ " and args.do_train\n",
+ " and not args.overwrite_output_dir\n",
+ " and not args.should_continue\n",
+ " ):\n",
+ " raise ValueError(\n",
+ " \"Output directory ({}) already exists and is not empty. Use --overwrite_output_dir to overcome.\".format(\n",
+ " args.output_dir\n",
+ " )\n",
+ " )\n",
+ "\n",
+ " # Setup CUDA, GPU & distributed training\n",
+ " device = torch.device(\"cuda\")\n",
+ " args.n_gpu = torch.cuda.device_count()\n",
+ " args.device = device\n",
+ "\n",
+ " # Setup logging\n",
+ " logging.basicConfig(\n",
+ " format=\"%(asctime)s - %(levelname)s - %(name)s - %(message)s\",\n",
+ " datefmt=\"%m/%d/%Y %H:%M:%S\",\n",
+ " level=logging.INFO if args.local_rank in [-1, 0] else logging.WARN,\n",
+ " )\n",
+ " logger.warning(\n",
+ " \"Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s\",\n",
+ " args.local_rank,\n",
+ " device,\n",
+ " args.n_gpu,\n",
+ " bool(args.local_rank != -1),\n",
+ " args.fp16,\n",
+ " )\n",
+ "\n",
+ " # Set seed\n",
+ " set_seed(args)\n",
+ "\n",
+ " config = AutoConfig.from_pretrained(args.config_name, cache_dir=args.cache_dir)\n",
+ " tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_name, cache_dir=args.cache_dir)\n",
+ " model = AutoModelWithLMHead.from_pretrained(\n",
+ " args.model_name_or_path,\n",
+ " from_tf=False,\n",
+ " config=config,\n",
+ " cache_dir=args.cache_dir,\n",
+ " )\n",
+ " model.to(args.device)\n",
+ " \n",
+ " logger.info(\"Training/evaluation parameters %s\", args)\n",
+ "\n",
+ " # Training\n",
+ " if args.do_train:\n",
+ " train_dataset = load_and_cache_examples(args, tokenizer, df_trn, df_val, evaluate=False)\n",
+ "\n",
+ " global_step, tr_loss = train(args, train_dataset, model, tokenizer)\n",
+ " logger.info(\" global_step = %s, average loss = %s\", global_step, tr_loss)\n",
+ "\n",
+ " # Saving best-practices: if you use save_pretrained for the model and tokenizer, you can reload them using from_pretrained()\n",
+ " if args.do_train:\n",
+ " # Create output directory if needed\n",
+ " os.makedirs(args.output_dir, exist_ok=True)\n",
+ "\n",
+ " logger.info(\"Saving model checkpoint to %s\", args.output_dir)\n",
+ " # Save a trained model, configuration and tokenizer using `save_pretrained()`.\n",
+ " # They can then be reloaded using `from_pretrained()`\n",
+ " model_to_save = (\n",
+ " model.module if hasattr(model, \"module\") else model\n",
+ " ) # Take care of distributed/parallel training\n",
+ " model_to_save.save_pretrained(args.output_dir)\n",
+ " tokenizer.save_pretrained(args.output_dir)\n",
+ "\n",
+ " # Good practice: save your training arguments together with the trained model\n",
+ " torch.save(args, os.path.join(args.output_dir, \"training_args.bin\"))\n",
+ "\n",
+ " # Load a trained model and vocabulary that you have fine-tuned\n",
+ " model = AutoModelWithLMHead.from_pretrained(args.output_dir)\n",
+ " tokenizer = AutoTokenizer.from_pretrained(args.output_dir)\n",
+ " model.to(args.device)\n",
+ "\n",
+ " # Evaluation\n",
+ " results = {}\n",
+ " if args.do_eval and args.local_rank in [-1, 0]:\n",
+ " checkpoints = [args.output_dir]\n",
+ " if args.eval_all_checkpoints:\n",
+ " checkpoints = list(\n",
+ " os.path.dirname(c) for c in sorted(glob.glob(args.output_dir + \"/**/\" + WEIGHTS_NAME, recursive=True))\n",
+ " )\n",
+ " logging.getLogger(\"transformers.modeling_utils\").setLevel(logging.WARN) # Reduce logging\n",
+ " logger.info(\"Evaluate the following checkpoints: %s\", checkpoints)\n",
+ " for checkpoint in checkpoints:\n",
+ " global_step = checkpoint.split(\"-\")[-1] if len(checkpoints) > 1 else \"\"\n",
+ " prefix = checkpoint.split(\"/\")[-1] if checkpoint.find(\"checkpoint\") != -1 else \"\"\n",
+ "\n",
+ " model = AutoModelWithLMHead.from_pretrained(checkpoint)\n",
+ " model.to(args.device)\n",
+ " result = evaluate(args, model, tokenizer, df_trn, df_val, prefix=prefix)\n",
+ " result = dict((k + \"_{}\".format(global_step), v) for k, v in result.items())\n",
+ " results.update(result)\n",
+ "\n",
+ " return results"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "7NWvkdR-XHeB"
+ },
+ "source": [
+ "## Run the Main Function"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 780,
+ "referenced_widgets": [
+ "1d7f4c82687540f1ad69eb54ac3c25b4",
+ "e7b9f3fc77a24259a87ef0dc735dfecb",
+ "f3bf54733c2d4d9daa1cc9a7746ccb14",
+ "aa40eb6346b54e7dac98e0b068cd4927",
+ "021b771a270f479aa3b9e2b5f17e3d97",
+ "450b0e7fd7a347c7beb78b7d72f64385",
+ "9391d7abf6ed4400903995f56d7a1260",
+ "ea6b919964d24c2f9de1c64c9cefaf23",
+ "2fa1fa2407384cb98d79a912de2d5b8f",
+ "dc27e2caf1ea4a4ab9ae3708fb06952f",
+ "e38fb98fd7b3413392dc39c93a107a35",
+ "855ca0a6125a4d698416214a9425ad98",
+ "4699416338ae40a5b6abf19e45089aec",
+ "43fdb31d3f314624ba07a15718b0c8f3",
+ "de252cd193114c40ad5f5e9622b7abc7",
+ "5e48b617cc3f41c3945efc28fc5e0c75",
+ "68a9dc52819c48fb97259f318f9b5c6a",
+ "b4e00059cf3a49929978ed780aae8358",
+ "0ff5f4e3506b493a98d72008a467f35f",
+ "77b97fa3271b48ac9f93665a102b4fd1",
+ "a937f1dfeee5432ba31b3016fd30e9e2",
+ "3c6d446f491c48fcae03e0034bfaaae9",
+ "a193bb3a0b5b4cbba587e2460075a445",
+ "75f8aebc30304fe198b5a2898a53a92d",
+ "8b8a7c771d234f6c9d758a1f07f75a90",
+ "c6518c4a721745bf97ee682f2ebe4635",
+ "29cffa2b4f234e12802344eb53838641",
+ "96243b7b227f465f83a289481680b925",
+ "8c016a54f0a24fcdacf369baa9d24f1e",
+ "7fe5b457ca0f417f90a20d235e9cec07",
+ "fdffb26b99c24c978580f1cf97359fea",
+ "8e3f1740c82f47949eefc2eb53052eae",
+ "9cccd43f6acc4e25b4876fd0ae7a2ad6",
+ "175e94deab7f4d20b99b419bea33583b",
+ "41f26f7210e540479814e5d68de13ddb",
+ "cf5cd281fa3b453093e210650bf81e9e",
+ "e1fbe239c2394cbf973ac5b95e1e1491",
+ "810ac22adad344b7bf8b556ded990122",
+ "8b3a41c1900b45ebb9c56601deca0e84",
+ "002f56aac3d64b33a0e799c0baf1e6b9",
+ "a0f2a9a279734aa5bf146f0a5b33c43b",
+ "850b5411122e4d608511fe26818bea68",
+ "0663fb4bd85f4d87a7d61910b995be14",
+ "cb7f52610fcf49bda46a14b296ff5bb5",
+ "0ca29b4a62e04d9c937189ea19b25de8",
+ "f871b83632974e0088bae65e78efaf28",
+ "4cacf7fc20754a7ca7fe08c8ec187a81",
+ "8bcc625c0f284398bbd287fe45021b17"
+ ]
+ },
+ "id": "e61zo2JtXGNX",
+ "outputId": "22d4916e-7169-44b5-f9d8-79b9c43fab2e"
+ },
+ "outputs": [],
+ "source": [
+ "main(trn_df, val_df)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "YRpQ_n2zXQj-"
+ },
+ "source": [
+ "## Load the Trained Model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "HGw3qgfaXQHX",
+ "outputId": "93e84cfd-9718-42e5-bd11-418112c91d71"
+ },
+ "outputs": [],
+ "source": [
+ "tokenizer = AutoTokenizer.from_pretrained('microsoft/DialoGPT-small')\n",
+ "model = AutoModelWithLMHead.from_pretrained('output-small')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "lAWsiAvNXbxd",
+ "outputId": "0fd2541e-ee68-4976-b098-8483efe38d5e"
+ },
+ "outputs": [],
+ "source": [
+ "# Let's chat for 4 lines\n",
+ "for step in range(4):\n",
+ " # encode the new user input, add the eos_token and return a tensor in Pytorch\n",
+ " new_user_input_ids = tokenizer.encode(input(\">> User:\") + tokenizer.eos_token, return_tensors='pt')\n",
+ " # print(new_user_input_ids)\n",
+ "\n",
+ " # append the new user input tokens to the chat history\n",
+ " bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids\n",
+ "\n",
+ " # generated a response while limiting the total chat history to 1000 tokens, \n",
+ " chat_history_ids = model.generate(\n",
+ " bot_input_ids, max_length=200,\n",
+ " pad_token_id=tokenizer.eos_token_id, \n",
+ " no_repeat_ngram_size=3, \n",
+ " do_sample=True, \n",
+ " top_k=100, \n",
+ " top_p=0.7,\n",
+ " temperature=0.8\n",
+ " )\n",
+ " \n",
+ " # pretty print last ouput tokens from bot\n",
+ " print(\"JoshuaBot: {}\".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ANSQlQezXqwn"
+ },
+ "source": [
+ "## Push Model to Hugging Face"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "VgnHRgHKXwDd"
+ },
+ "outputs": [],
+ "source": [
+ "!sudo apt-get install git-lfs"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "uhqMtvfmXei8"
+ },
+ "outputs": [],
+ "source": [
+ "!git config --global user.email \"lynnzheng08@outlook.com\"\n",
+ "# Tip: using the same email as your huggingface.co account will link your commits to your profile\n",
+ "!git config --global user.name \"Lynn Zheng\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "tfUsrKR7YLT1"
+ },
+ "outputs": [],
+ "source": [
+ "MY_MODEL_NAME = 'DialoGPT-small-joshua'\n",
+ "with open('HuggingFace-API-key.txt', 'rt') as f:\n",
+ " HUGGINGFACE_API_KEY = f.read().strip()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 1000
+ },
+ "id": "_65nsiLcYNXI",
+ "outputId": "0dbf0cb1-957c-4adb-bf55-4222d2cc85bc"
+ },
+ "outputs": [],
+ "source": [
+ "model.push_to_hub(MY_MODEL_NAME, use_auth_token=HUGGINGFACE_API_KEY)\n",
+ "tokenizer.push_to_hub(MY_MODEL_NAME, use_auth_token=HUGGINGFACE_API_KEY)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "D_XfXTCrZKmO"
+ },
+ "source": [
+ "## All Done!"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "_tIwK7G8ZLrd"
+ },
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "collapsed_sections": [],
+ "name": "model_train_upload_workflow.ipynb",
+ "provenance": []
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.4"
+ },
+ "widgets": {
+ "application/vnd.jupyter.widget-state+json": {
+ "002f56aac3d64b33a0e799c0baf1e6b9": {
+ "model_module": "@jupyter-widgets/base",
+ "model_name": "LayoutModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/base",
+ "_model_module_version": "1.2.0",
+ "_model_name": "LayoutModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "LayoutView",
+ "align_content": null,
+ "align_items": null,
+ "align_self": null,
+ "border": null,
+ "bottom": null,
+ "display": null,
+ "flex": null,
+ "flex_flow": null,
+ "grid_area": null,
+ "grid_auto_columns": null,
+ "grid_auto_flow": null,
+ "grid_auto_rows": null,
+ "grid_column": null,
+ "grid_gap": null,
+ "grid_row": null,
+ "grid_template_areas": null,
+ "grid_template_columns": null,
+ "grid_template_rows": null,
+ "height": null,
+ "justify_content": null,
+ "justify_items": null,
+ "left": null,
+ "margin": null,
+ "max_height": null,
+ "max_width": null,
+ "min_height": null,
+ "min_width": null,
+ "object_fit": null,
+ "object_position": null,
+ "order": null,
+ "overflow": null,
+ "overflow_x": null,
+ "overflow_y": null,
+ "padding": null,
+ "right": null,
+ "top": null,
+ "visibility": null,
+ "width": null
+ }
+ },
+ "021b771a270f479aa3b9e2b5f17e3d97": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "ProgressStyleModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "ProgressStyleModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "StyleView",
+ "bar_color": null,
+ "description_width": "initial"
+ }
+ },
+ "0663fb4bd85f4d87a7d61910b995be14": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "FloatProgressModel",
+ "state": {
+ "_dom_classes": [],
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "FloatProgressModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/controls",
+ "_view_module_version": "1.5.0",
+ "_view_name": "ProgressView",
+ "bar_style": "success",
+ "description": "Evaluating: 100%",
+ "description_tooltip": null,
+ "layout": "IPY_MODEL_f871b83632974e0088bae65e78efaf28",
+ "max": 21,
+ "min": 0,
+ "orientation": "horizontal",
+ "style": "IPY_MODEL_0ca29b4a62e04d9c937189ea19b25de8",
+ "value": 21
+ }
+ },
+ "0ca29b4a62e04d9c937189ea19b25de8": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "ProgressStyleModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "ProgressStyleModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "StyleView",
+ "bar_color": null,
+ "description_width": "initial"
+ }
+ },
+ "0ff5f4e3506b493a98d72008a467f35f": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "FloatProgressModel",
+ "state": {
+ "_dom_classes": [],
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "FloatProgressModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/controls",
+ "_view_module_version": "1.5.0",
+ "_view_name": "ProgressView",
+ "bar_style": "success",
+ "description": "Iteration: 100%",
+ "description_tooltip": null,
+ "layout": "IPY_MODEL_3c6d446f491c48fcae03e0034bfaaae9",
+ "max": 195,
+ "min": 0,
+ "orientation": "horizontal",
+ "style": "IPY_MODEL_a937f1dfeee5432ba31b3016fd30e9e2",
+ "value": 195
+ }
+ },
+ "175e94deab7f4d20b99b419bea33583b": {
+ "model_module": "@jupyter-widgets/base",
+ "model_name": "LayoutModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/base",
+ "_model_module_version": "1.2.0",
+ "_model_name": "LayoutModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "LayoutView",
+ "align_content": null,
+ "align_items": null,
+ "align_self": null,
+ "border": null,
+ "bottom": null,
+ "display": null,
+ "flex": null,
+ "flex_flow": null,
+ "grid_area": null,
+ "grid_auto_columns": null,
+ "grid_auto_flow": null,
+ "grid_auto_rows": null,
+ "grid_column": null,
+ "grid_gap": null,
+ "grid_row": null,
+ "grid_template_areas": null,
+ "grid_template_columns": null,
+ "grid_template_rows": null,
+ "height": null,
+ "justify_content": null,
+ "justify_items": null,
+ "left": null,
+ "margin": null,
+ "max_height": null,
+ "max_width": null,
+ "min_height": null,
+ "min_width": null,
+ "object_fit": null,
+ "object_position": null,
+ "order": null,
+ "overflow": null,
+ "overflow_x": null,
+ "overflow_y": null,
+ "padding": null,
+ "right": null,
+ "top": null,
+ "visibility": null,
+ "width": null
+ }
+ },
+ "1d7f4c82687540f1ad69eb54ac3c25b4": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "HBoxModel",
+ "state": {
+ "_dom_classes": [],
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "HBoxModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/controls",
+ "_view_module_version": "1.5.0",
+ "_view_name": "HBoxView",
+ "box_style": "",
+ "children": [
+ "IPY_MODEL_f3bf54733c2d4d9daa1cc9a7746ccb14",
+ "IPY_MODEL_aa40eb6346b54e7dac98e0b068cd4927"
+ ],
+ "layout": "IPY_MODEL_e7b9f3fc77a24259a87ef0dc735dfecb"
+ }
+ },
+ "29cffa2b4f234e12802344eb53838641": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "FloatProgressModel",
+ "state": {
+ "_dom_classes": [],
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "FloatProgressModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/controls",
+ "_view_module_version": "1.5.0",
+ "_view_name": "ProgressView",
+ "bar_style": "success",
+ "description": "Iteration: 100%",
+ "description_tooltip": null,
+ "layout": "IPY_MODEL_7fe5b457ca0f417f90a20d235e9cec07",
+ "max": 195,
+ "min": 0,
+ "orientation": "horizontal",
+ "style": "IPY_MODEL_8c016a54f0a24fcdacf369baa9d24f1e",
+ "value": 195
+ }
+ },
+ "2fa1fa2407384cb98d79a912de2d5b8f": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "HBoxModel",
+ "state": {
+ "_dom_classes": [],
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "HBoxModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/controls",
+ "_view_module_version": "1.5.0",
+ "_view_name": "HBoxView",
+ "box_style": "",
+ "children": [
+ "IPY_MODEL_e38fb98fd7b3413392dc39c93a107a35",
+ "IPY_MODEL_855ca0a6125a4d698416214a9425ad98"
+ ],
+ "layout": "IPY_MODEL_dc27e2caf1ea4a4ab9ae3708fb06952f"
+ }
+ },
+ "3c6d446f491c48fcae03e0034bfaaae9": {
+ "model_module": "@jupyter-widgets/base",
+ "model_name": "LayoutModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/base",
+ "_model_module_version": "1.2.0",
+ "_model_name": "LayoutModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "LayoutView",
+ "align_content": null,
+ "align_items": null,
+ "align_self": null,
+ "border": null,
+ "bottom": null,
+ "display": null,
+ "flex": null,
+ "flex_flow": null,
+ "grid_area": null,
+ "grid_auto_columns": null,
+ "grid_auto_flow": null,
+ "grid_auto_rows": null,
+ "grid_column": null,
+ "grid_gap": null,
+ "grid_row": null,
+ "grid_template_areas": null,
+ "grid_template_columns": null,
+ "grid_template_rows": null,
+ "height": null,
+ "justify_content": null,
+ "justify_items": null,
+ "left": null,
+ "margin": null,
+ "max_height": null,
+ "max_width": null,
+ "min_height": null,
+ "min_width": null,
+ "object_fit": null,
+ "object_position": null,
+ "order": null,
+ "overflow": null,
+ "overflow_x": null,
+ "overflow_y": null,
+ "padding": null,
+ "right": null,
+ "top": null,
+ "visibility": null,
+ "width": null
+ }
+ },
+ "41f26f7210e540479814e5d68de13ddb": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "FloatProgressModel",
+ "state": {
+ "_dom_classes": [],
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "FloatProgressModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/controls",
+ "_view_module_version": "1.5.0",
+ "_view_name": "ProgressView",
+ "bar_style": "success",
+ "description": "Iteration: 100%",
+ "description_tooltip": null,
+ "layout": "IPY_MODEL_810ac22adad344b7bf8b556ded990122",
+ "max": 195,
+ "min": 0,
+ "orientation": "horizontal",
+ "style": "IPY_MODEL_e1fbe239c2394cbf973ac5b95e1e1491",
+ "value": 195
+ }
+ },
+ "43fdb31d3f314624ba07a15718b0c8f3": {
+ "model_module": "@jupyter-widgets/base",
+ "model_name": "LayoutModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/base",
+ "_model_module_version": "1.2.0",
+ "_model_name": "LayoutModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "LayoutView",
+ "align_content": null,
+ "align_items": null,
+ "align_self": null,
+ "border": null,
+ "bottom": null,
+ "display": null,
+ "flex": null,
+ "flex_flow": null,
+ "grid_area": null,
+ "grid_auto_columns": null,
+ "grid_auto_flow": null,
+ "grid_auto_rows": null,
+ "grid_column": null,
+ "grid_gap": null,
+ "grid_row": null,
+ "grid_template_areas": null,
+ "grid_template_columns": null,
+ "grid_template_rows": null,
+ "height": null,
+ "justify_content": null,
+ "justify_items": null,
+ "left": null,
+ "margin": null,
+ "max_height": null,
+ "max_width": null,
+ "min_height": null,
+ "min_width": null,
+ "object_fit": null,
+ "object_position": null,
+ "order": null,
+ "overflow": null,
+ "overflow_x": null,
+ "overflow_y": null,
+ "padding": null,
+ "right": null,
+ "top": null,
+ "visibility": null,
+ "width": null
+ }
+ },
+ "450b0e7fd7a347c7beb78b7d72f64385": {
+ "model_module": "@jupyter-widgets/base",
+ "model_name": "LayoutModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/base",
+ "_model_module_version": "1.2.0",
+ "_model_name": "LayoutModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "LayoutView",
+ "align_content": null,
+ "align_items": null,
+ "align_self": null,
+ "border": null,
+ "bottom": null,
+ "display": null,
+ "flex": null,
+ "flex_flow": null,
+ "grid_area": null,
+ "grid_auto_columns": null,
+ "grid_auto_flow": null,
+ "grid_auto_rows": null,
+ "grid_column": null,
+ "grid_gap": null,
+ "grid_row": null,
+ "grid_template_areas": null,
+ "grid_template_columns": null,
+ "grid_template_rows": null,
+ "height": null,
+ "justify_content": null,
+ "justify_items": null,
+ "left": null,
+ "margin": null,
+ "max_height": null,
+ "max_width": null,
+ "min_height": null,
+ "min_width": null,
+ "object_fit": null,
+ "object_position": null,
+ "order": null,
+ "overflow": null,
+ "overflow_x": null,
+ "overflow_y": null,
+ "padding": null,
+ "right": null,
+ "top": null,
+ "visibility": null,
+ "width": null
+ }
+ },
+ "4699416338ae40a5b6abf19e45089aec": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "ProgressStyleModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "ProgressStyleModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "StyleView",
+ "bar_color": null,
+ "description_width": "initial"
+ }
+ },
+ "4cacf7fc20754a7ca7fe08c8ec187a81": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "DescriptionStyleModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "DescriptionStyleModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "StyleView",
+ "description_width": ""
+ }
+ },
+ "5e48b617cc3f41c3945efc28fc5e0c75": {
+ "model_module": "@jupyter-widgets/base",
+ "model_name": "LayoutModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/base",
+ "_model_module_version": "1.2.0",
+ "_model_name": "LayoutModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "LayoutView",
+ "align_content": null,
+ "align_items": null,
+ "align_self": null,
+ "border": null,
+ "bottom": null,
+ "display": null,
+ "flex": null,
+ "flex_flow": null,
+ "grid_area": null,
+ "grid_auto_columns": null,
+ "grid_auto_flow": null,
+ "grid_auto_rows": null,
+ "grid_column": null,
+ "grid_gap": null,
+ "grid_row": null,
+ "grid_template_areas": null,
+ "grid_template_columns": null,
+ "grid_template_rows": null,
+ "height": null,
+ "justify_content": null,
+ "justify_items": null,
+ "left": null,
+ "margin": null,
+ "max_height": null,
+ "max_width": null,
+ "min_height": null,
+ "min_width": null,
+ "object_fit": null,
+ "object_position": null,
+ "order": null,
+ "overflow": null,
+ "overflow_x": null,
+ "overflow_y": null,
+ "padding": null,
+ "right": null,
+ "top": null,
+ "visibility": null,
+ "width": null
+ }
+ },
+ "68a9dc52819c48fb97259f318f9b5c6a": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "HBoxModel",
+ "state": {
+ "_dom_classes": [],
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "HBoxModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/controls",
+ "_view_module_version": "1.5.0",
+ "_view_name": "HBoxView",
+ "box_style": "",
+ "children": [
+ "IPY_MODEL_0ff5f4e3506b493a98d72008a467f35f",
+ "IPY_MODEL_77b97fa3271b48ac9f93665a102b4fd1"
+ ],
+ "layout": "IPY_MODEL_b4e00059cf3a49929978ed780aae8358"
+ }
+ },
+ "75f8aebc30304fe198b5a2898a53a92d": {
+ "model_module": "@jupyter-widgets/base",
+ "model_name": "LayoutModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/base",
+ "_model_module_version": "1.2.0",
+ "_model_name": "LayoutModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "LayoutView",
+ "align_content": null,
+ "align_items": null,
+ "align_self": null,
+ "border": null,
+ "bottom": null,
+ "display": null,
+ "flex": null,
+ "flex_flow": null,
+ "grid_area": null,
+ "grid_auto_columns": null,
+ "grid_auto_flow": null,
+ "grid_auto_rows": null,
+ "grid_column": null,
+ "grid_gap": null,
+ "grid_row": null,
+ "grid_template_areas": null,
+ "grid_template_columns": null,
+ "grid_template_rows": null,
+ "height": null,
+ "justify_content": null,
+ "justify_items": null,
+ "left": null,
+ "margin": null,
+ "max_height": null,
+ "max_width": null,
+ "min_height": null,
+ "min_width": null,
+ "object_fit": null,
+ "object_position": null,
+ "order": null,
+ "overflow": null,
+ "overflow_x": null,
+ "overflow_y": null,
+ "padding": null,
+ "right": null,
+ "top": null,
+ "visibility": null,
+ "width": null
+ }
+ },
+ "77b97fa3271b48ac9f93665a102b4fd1": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "HTMLModel",
+ "state": {
+ "_dom_classes": [],
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "HTMLModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/controls",
+ "_view_module_version": "1.5.0",
+ "_view_name": "HTMLView",
+ "description": "",
+ "description_tooltip": null,
+ "layout": "IPY_MODEL_75f8aebc30304fe198b5a2898a53a92d",
+ "placeholder": "",
+ "style": "IPY_MODEL_a193bb3a0b5b4cbba587e2460075a445",
+ "value": " 195/195 [00:35<00:00, 5.45it/s]"
+ }
+ },
+ "7fe5b457ca0f417f90a20d235e9cec07": {
+ "model_module": "@jupyter-widgets/base",
+ "model_name": "LayoutModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/base",
+ "_model_module_version": "1.2.0",
+ "_model_name": "LayoutModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "LayoutView",
+ "align_content": null,
+ "align_items": null,
+ "align_self": null,
+ "border": null,
+ "bottom": null,
+ "display": null,
+ "flex": null,
+ "flex_flow": null,
+ "grid_area": null,
+ "grid_auto_columns": null,
+ "grid_auto_flow": null,
+ "grid_auto_rows": null,
+ "grid_column": null,
+ "grid_gap": null,
+ "grid_row": null,
+ "grid_template_areas": null,
+ "grid_template_columns": null,
+ "grid_template_rows": null,
+ "height": null,
+ "justify_content": null,
+ "justify_items": null,
+ "left": null,
+ "margin": null,
+ "max_height": null,
+ "max_width": null,
+ "min_height": null,
+ "min_width": null,
+ "object_fit": null,
+ "object_position": null,
+ "order": null,
+ "overflow": null,
+ "overflow_x": null,
+ "overflow_y": null,
+ "padding": null,
+ "right": null,
+ "top": null,
+ "visibility": null,
+ "width": null
+ }
+ },
+ "810ac22adad344b7bf8b556ded990122": {
+ "model_module": "@jupyter-widgets/base",
+ "model_name": "LayoutModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/base",
+ "_model_module_version": "1.2.0",
+ "_model_name": "LayoutModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "LayoutView",
+ "align_content": null,
+ "align_items": null,
+ "align_self": null,
+ "border": null,
+ "bottom": null,
+ "display": null,
+ "flex": null,
+ "flex_flow": null,
+ "grid_area": null,
+ "grid_auto_columns": null,
+ "grid_auto_flow": null,
+ "grid_auto_rows": null,
+ "grid_column": null,
+ "grid_gap": null,
+ "grid_row": null,
+ "grid_template_areas": null,
+ "grid_template_columns": null,
+ "grid_template_rows": null,
+ "height": null,
+ "justify_content": null,
+ "justify_items": null,
+ "left": null,
+ "margin": null,
+ "max_height": null,
+ "max_width": null,
+ "min_height": null,
+ "min_width": null,
+ "object_fit": null,
+ "object_position": null,
+ "order": null,
+ "overflow": null,
+ "overflow_x": null,
+ "overflow_y": null,
+ "padding": null,
+ "right": null,
+ "top": null,
+ "visibility": null,
+ "width": null
+ }
+ },
+ "850b5411122e4d608511fe26818bea68": {
+ "model_module": "@jupyter-widgets/base",
+ "model_name": "LayoutModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/base",
+ "_model_module_version": "1.2.0",
+ "_model_name": "LayoutModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "LayoutView",
+ "align_content": null,
+ "align_items": null,
+ "align_self": null,
+ "border": null,
+ "bottom": null,
+ "display": null,
+ "flex": null,
+ "flex_flow": null,
+ "grid_area": null,
+ "grid_auto_columns": null,
+ "grid_auto_flow": null,
+ "grid_auto_rows": null,
+ "grid_column": null,
+ "grid_gap": null,
+ "grid_row": null,
+ "grid_template_areas": null,
+ "grid_template_columns": null,
+ "grid_template_rows": null,
+ "height": null,
+ "justify_content": null,
+ "justify_items": null,
+ "left": null,
+ "margin": null,
+ "max_height": null,
+ "max_width": null,
+ "min_height": null,
+ "min_width": null,
+ "object_fit": null,
+ "object_position": null,
+ "order": null,
+ "overflow": null,
+ "overflow_x": null,
+ "overflow_y": null,
+ "padding": null,
+ "right": null,
+ "top": null,
+ "visibility": null,
+ "width": null
+ }
+ },
+ "855ca0a6125a4d698416214a9425ad98": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "HTMLModel",
+ "state": {
+ "_dom_classes": [],
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "HTMLModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/controls",
+ "_view_module_version": "1.5.0",
+ "_view_name": "HTMLView",
+ "description": "",
+ "description_tooltip": null,
+ "layout": "IPY_MODEL_5e48b617cc3f41c3945efc28fc5e0c75",
+ "placeholder": "",
+ "style": "IPY_MODEL_de252cd193114c40ad5f5e9622b7abc7",
+ "value": " 195/195 [00:44<00:00, 4.39it/s]"
+ }
+ },
+ "8b3a41c1900b45ebb9c56601deca0e84": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "DescriptionStyleModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "DescriptionStyleModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "StyleView",
+ "description_width": ""
+ }
+ },
+ "8b8a7c771d234f6c9d758a1f07f75a90": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "HBoxModel",
+ "state": {
+ "_dom_classes": [],
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "HBoxModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/controls",
+ "_view_module_version": "1.5.0",
+ "_view_name": "HBoxView",
+ "box_style": "",
+ "children": [
+ "IPY_MODEL_29cffa2b4f234e12802344eb53838641",
+ "IPY_MODEL_96243b7b227f465f83a289481680b925"
+ ],
+ "layout": "IPY_MODEL_c6518c4a721745bf97ee682f2ebe4635"
+ }
+ },
+ "8bcc625c0f284398bbd287fe45021b17": {
+ "model_module": "@jupyter-widgets/base",
+ "model_name": "LayoutModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/base",
+ "_model_module_version": "1.2.0",
+ "_model_name": "LayoutModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "LayoutView",
+ "align_content": null,
+ "align_items": null,
+ "align_self": null,
+ "border": null,
+ "bottom": null,
+ "display": null,
+ "flex": null,
+ "flex_flow": null,
+ "grid_area": null,
+ "grid_auto_columns": null,
+ "grid_auto_flow": null,
+ "grid_auto_rows": null,
+ "grid_column": null,
+ "grid_gap": null,
+ "grid_row": null,
+ "grid_template_areas": null,
+ "grid_template_columns": null,
+ "grid_template_rows": null,
+ "height": null,
+ "justify_content": null,
+ "justify_items": null,
+ "left": null,
+ "margin": null,
+ "max_height": null,
+ "max_width": null,
+ "min_height": null,
+ "min_width": null,
+ "object_fit": null,
+ "object_position": null,
+ "order": null,
+ "overflow": null,
+ "overflow_x": null,
+ "overflow_y": null,
+ "padding": null,
+ "right": null,
+ "top": null,
+ "visibility": null,
+ "width": null
+ }
+ },
+ "8c016a54f0a24fcdacf369baa9d24f1e": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "ProgressStyleModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "ProgressStyleModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "StyleView",
+ "bar_color": null,
+ "description_width": "initial"
+ }
+ },
+ "8e3f1740c82f47949eefc2eb53052eae": {
+ "model_module": "@jupyter-widgets/base",
+ "model_name": "LayoutModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/base",
+ "_model_module_version": "1.2.0",
+ "_model_name": "LayoutModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "LayoutView",
+ "align_content": null,
+ "align_items": null,
+ "align_self": null,
+ "border": null,
+ "bottom": null,
+ "display": null,
+ "flex": null,
+ "flex_flow": null,
+ "grid_area": null,
+ "grid_auto_columns": null,
+ "grid_auto_flow": null,
+ "grid_auto_rows": null,
+ "grid_column": null,
+ "grid_gap": null,
+ "grid_row": null,
+ "grid_template_areas": null,
+ "grid_template_columns": null,
+ "grid_template_rows": null,
+ "height": null,
+ "justify_content": null,
+ "justify_items": null,
+ "left": null,
+ "margin": null,
+ "max_height": null,
+ "max_width": null,
+ "min_height": null,
+ "min_width": null,
+ "object_fit": null,
+ "object_position": null,
+ "order": null,
+ "overflow": null,
+ "overflow_x": null,
+ "overflow_y": null,
+ "padding": null,
+ "right": null,
+ "top": null,
+ "visibility": null,
+ "width": null
+ }
+ },
+ "9391d7abf6ed4400903995f56d7a1260": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "DescriptionStyleModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "DescriptionStyleModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "StyleView",
+ "description_width": ""
+ }
+ },
+ "96243b7b227f465f83a289481680b925": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "HTMLModel",
+ "state": {
+ "_dom_classes": [],
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "HTMLModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/controls",
+ "_view_module_version": "1.5.0",
+ "_view_name": "HTMLView",
+ "description": "",
+ "description_tooltip": null,
+ "layout": "IPY_MODEL_8e3f1740c82f47949eefc2eb53052eae",
+ "placeholder": "",
+ "style": "IPY_MODEL_fdffb26b99c24c978580f1cf97359fea",
+ "value": " 195/195 [01:17<00:00, 2.53it/s]"
+ }
+ },
+ "9cccd43f6acc4e25b4876fd0ae7a2ad6": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "HBoxModel",
+ "state": {
+ "_dom_classes": [],
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "HBoxModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/controls",
+ "_view_module_version": "1.5.0",
+ "_view_name": "HBoxView",
+ "box_style": "",
+ "children": [
+ "IPY_MODEL_41f26f7210e540479814e5d68de13ddb",
+ "IPY_MODEL_cf5cd281fa3b453093e210650bf81e9e"
+ ],
+ "layout": "IPY_MODEL_175e94deab7f4d20b99b419bea33583b"
+ }
+ },
+ "a0f2a9a279734aa5bf146f0a5b33c43b": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "HBoxModel",
+ "state": {
+ "_dom_classes": [],
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "HBoxModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/controls",
+ "_view_module_version": "1.5.0",
+ "_view_name": "HBoxView",
+ "box_style": "",
+ "children": [
+ "IPY_MODEL_0663fb4bd85f4d87a7d61910b995be14",
+ "IPY_MODEL_cb7f52610fcf49bda46a14b296ff5bb5"
+ ],
+ "layout": "IPY_MODEL_850b5411122e4d608511fe26818bea68"
+ }
+ },
+ "a193bb3a0b5b4cbba587e2460075a445": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "DescriptionStyleModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "DescriptionStyleModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "StyleView",
+ "description_width": ""
+ }
+ },
+ "a937f1dfeee5432ba31b3016fd30e9e2": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "ProgressStyleModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "ProgressStyleModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "StyleView",
+ "bar_color": null,
+ "description_width": "initial"
+ }
+ },
+ "aa40eb6346b54e7dac98e0b068cd4927": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "HTMLModel",
+ "state": {
+ "_dom_classes": [],
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "HTMLModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/controls",
+ "_view_module_version": "1.5.0",
+ "_view_name": "HTMLView",
+ "description": "",
+ "description_tooltip": null,
+ "layout": "IPY_MODEL_ea6b919964d24c2f9de1c64c9cefaf23",
+ "placeholder": "",
+ "style": "IPY_MODEL_9391d7abf6ed4400903995f56d7a1260",
+ "value": " 4/4 [02:23<00:00, 36.00s/it]"
+ }
+ },
+ "b4e00059cf3a49929978ed780aae8358": {
+ "model_module": "@jupyter-widgets/base",
+ "model_name": "LayoutModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/base",
+ "_model_module_version": "1.2.0",
+ "_model_name": "LayoutModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "LayoutView",
+ "align_content": null,
+ "align_items": null,
+ "align_self": null,
+ "border": null,
+ "bottom": null,
+ "display": null,
+ "flex": null,
+ "flex_flow": null,
+ "grid_area": null,
+ "grid_auto_columns": null,
+ "grid_auto_flow": null,
+ "grid_auto_rows": null,
+ "grid_column": null,
+ "grid_gap": null,
+ "grid_row": null,
+ "grid_template_areas": null,
+ "grid_template_columns": null,
+ "grid_template_rows": null,
+ "height": null,
+ "justify_content": null,
+ "justify_items": null,
+ "left": null,
+ "margin": null,
+ "max_height": null,
+ "max_width": null,
+ "min_height": null,
+ "min_width": null,
+ "object_fit": null,
+ "object_position": null,
+ "order": null,
+ "overflow": null,
+ "overflow_x": null,
+ "overflow_y": null,
+ "padding": null,
+ "right": null,
+ "top": null,
+ "visibility": null,
+ "width": null
+ }
+ },
+ "c6518c4a721745bf97ee682f2ebe4635": {
+ "model_module": "@jupyter-widgets/base",
+ "model_name": "LayoutModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/base",
+ "_model_module_version": "1.2.0",
+ "_model_name": "LayoutModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "LayoutView",
+ "align_content": null,
+ "align_items": null,
+ "align_self": null,
+ "border": null,
+ "bottom": null,
+ "display": null,
+ "flex": null,
+ "flex_flow": null,
+ "grid_area": null,
+ "grid_auto_columns": null,
+ "grid_auto_flow": null,
+ "grid_auto_rows": null,
+ "grid_column": null,
+ "grid_gap": null,
+ "grid_row": null,
+ "grid_template_areas": null,
+ "grid_template_columns": null,
+ "grid_template_rows": null,
+ "height": null,
+ "justify_content": null,
+ "justify_items": null,
+ "left": null,
+ "margin": null,
+ "max_height": null,
+ "max_width": null,
+ "min_height": null,
+ "min_width": null,
+ "object_fit": null,
+ "object_position": null,
+ "order": null,
+ "overflow": null,
+ "overflow_x": null,
+ "overflow_y": null,
+ "padding": null,
+ "right": null,
+ "top": null,
+ "visibility": null,
+ "width": null
+ }
+ },
+ "cb7f52610fcf49bda46a14b296ff5bb5": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "HTMLModel",
+ "state": {
+ "_dom_classes": [],
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "HTMLModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/controls",
+ "_view_module_version": "1.5.0",
+ "_view_name": "HTMLView",
+ "description": "",
+ "description_tooltip": null,
+ "layout": "IPY_MODEL_8bcc625c0f284398bbd287fe45021b17",
+ "placeholder": "",
+ "style": "IPY_MODEL_4cacf7fc20754a7ca7fe08c8ec187a81",
+ "value": " 21/21 [00:01<00:00, 10.78it/s]"
+ }
+ },
+ "cf5cd281fa3b453093e210650bf81e9e": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "HTMLModel",
+ "state": {
+ "_dom_classes": [],
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "HTMLModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/controls",
+ "_view_module_version": "1.5.0",
+ "_view_name": "HTMLView",
+ "description": "",
+ "description_tooltip": null,
+ "layout": "IPY_MODEL_002f56aac3d64b33a0e799c0baf1e6b9",
+ "placeholder": "",
+ "style": "IPY_MODEL_8b3a41c1900b45ebb9c56601deca0e84",
+ "value": " 195/195 [00:40<00:00, 4.84it/s]"
+ }
+ },
+ "dc27e2caf1ea4a4ab9ae3708fb06952f": {
+ "model_module": "@jupyter-widgets/base",
+ "model_name": "LayoutModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/base",
+ "_model_module_version": "1.2.0",
+ "_model_name": "LayoutModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "LayoutView",
+ "align_content": null,
+ "align_items": null,
+ "align_self": null,
+ "border": null,
+ "bottom": null,
+ "display": null,
+ "flex": null,
+ "flex_flow": null,
+ "grid_area": null,
+ "grid_auto_columns": null,
+ "grid_auto_flow": null,
+ "grid_auto_rows": null,
+ "grid_column": null,
+ "grid_gap": null,
+ "grid_row": null,
+ "grid_template_areas": null,
+ "grid_template_columns": null,
+ "grid_template_rows": null,
+ "height": null,
+ "justify_content": null,
+ "justify_items": null,
+ "left": null,
+ "margin": null,
+ "max_height": null,
+ "max_width": null,
+ "min_height": null,
+ "min_width": null,
+ "object_fit": null,
+ "object_position": null,
+ "order": null,
+ "overflow": null,
+ "overflow_x": null,
+ "overflow_y": null,
+ "padding": null,
+ "right": null,
+ "top": null,
+ "visibility": null,
+ "width": null
+ }
+ },
+ "de252cd193114c40ad5f5e9622b7abc7": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "DescriptionStyleModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "DescriptionStyleModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "StyleView",
+ "description_width": ""
+ }
+ },
+ "e1fbe239c2394cbf973ac5b95e1e1491": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "ProgressStyleModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "ProgressStyleModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "StyleView",
+ "bar_color": null,
+ "description_width": "initial"
+ }
+ },
+ "e38fb98fd7b3413392dc39c93a107a35": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "FloatProgressModel",
+ "state": {
+ "_dom_classes": [],
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "FloatProgressModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/controls",
+ "_view_module_version": "1.5.0",
+ "_view_name": "ProgressView",
+ "bar_style": "success",
+ "description": "Iteration: 100%",
+ "description_tooltip": null,
+ "layout": "IPY_MODEL_43fdb31d3f314624ba07a15718b0c8f3",
+ "max": 195,
+ "min": 0,
+ "orientation": "horizontal",
+ "style": "IPY_MODEL_4699416338ae40a5b6abf19e45089aec",
+ "value": 195
+ }
+ },
+ "e7b9f3fc77a24259a87ef0dc735dfecb": {
+ "model_module": "@jupyter-widgets/base",
+ "model_name": "LayoutModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/base",
+ "_model_module_version": "1.2.0",
+ "_model_name": "LayoutModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "LayoutView",
+ "align_content": null,
+ "align_items": null,
+ "align_self": null,
+ "border": null,
+ "bottom": null,
+ "display": null,
+ "flex": null,
+ "flex_flow": null,
+ "grid_area": null,
+ "grid_auto_columns": null,
+ "grid_auto_flow": null,
+ "grid_auto_rows": null,
+ "grid_column": null,
+ "grid_gap": null,
+ "grid_row": null,
+ "grid_template_areas": null,
+ "grid_template_columns": null,
+ "grid_template_rows": null,
+ "height": null,
+ "justify_content": null,
+ "justify_items": null,
+ "left": null,
+ "margin": null,
+ "max_height": null,
+ "max_width": null,
+ "min_height": null,
+ "min_width": null,
+ "object_fit": null,
+ "object_position": null,
+ "order": null,
+ "overflow": null,
+ "overflow_x": null,
+ "overflow_y": null,
+ "padding": null,
+ "right": null,
+ "top": null,
+ "visibility": null,
+ "width": null
+ }
+ },
+ "ea6b919964d24c2f9de1c64c9cefaf23": {
+ "model_module": "@jupyter-widgets/base",
+ "model_name": "LayoutModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/base",
+ "_model_module_version": "1.2.0",
+ "_model_name": "LayoutModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "LayoutView",
+ "align_content": null,
+ "align_items": null,
+ "align_self": null,
+ "border": null,
+ "bottom": null,
+ "display": null,
+ "flex": null,
+ "flex_flow": null,
+ "grid_area": null,
+ "grid_auto_columns": null,
+ "grid_auto_flow": null,
+ "grid_auto_rows": null,
+ "grid_column": null,
+ "grid_gap": null,
+ "grid_row": null,
+ "grid_template_areas": null,
+ "grid_template_columns": null,
+ "grid_template_rows": null,
+ "height": null,
+ "justify_content": null,
+ "justify_items": null,
+ "left": null,
+ "margin": null,
+ "max_height": null,
+ "max_width": null,
+ "min_height": null,
+ "min_width": null,
+ "object_fit": null,
+ "object_position": null,
+ "order": null,
+ "overflow": null,
+ "overflow_x": null,
+ "overflow_y": null,
+ "padding": null,
+ "right": null,
+ "top": null,
+ "visibility": null,
+ "width": null
+ }
+ },
+ "f3bf54733c2d4d9daa1cc9a7746ccb14": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "FloatProgressModel",
+ "state": {
+ "_dom_classes": [],
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "FloatProgressModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/controls",
+ "_view_module_version": "1.5.0",
+ "_view_name": "ProgressView",
+ "bar_style": "success",
+ "description": "Epoch: 100%",
+ "description_tooltip": null,
+ "layout": "IPY_MODEL_450b0e7fd7a347c7beb78b7d72f64385",
+ "max": 4,
+ "min": 0,
+ "orientation": "horizontal",
+ "style": "IPY_MODEL_021b771a270f479aa3b9e2b5f17e3d97",
+ "value": 4
+ }
+ },
+ "f871b83632974e0088bae65e78efaf28": {
+ "model_module": "@jupyter-widgets/base",
+ "model_name": "LayoutModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/base",
+ "_model_module_version": "1.2.0",
+ "_model_name": "LayoutModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "LayoutView",
+ "align_content": null,
+ "align_items": null,
+ "align_self": null,
+ "border": null,
+ "bottom": null,
+ "display": null,
+ "flex": null,
+ "flex_flow": null,
+ "grid_area": null,
+ "grid_auto_columns": null,
+ "grid_auto_flow": null,
+ "grid_auto_rows": null,
+ "grid_column": null,
+ "grid_gap": null,
+ "grid_row": null,
+ "grid_template_areas": null,
+ "grid_template_columns": null,
+ "grid_template_rows": null,
+ "height": null,
+ "justify_content": null,
+ "justify_items": null,
+ "left": null,
+ "margin": null,
+ "max_height": null,
+ "max_width": null,
+ "min_height": null,
+ "min_width": null,
+ "object_fit": null,
+ "object_position": null,
+ "order": null,
+ "overflow": null,
+ "overflow_x": null,
+ "overflow_y": null,
+ "padding": null,
+ "right": null,
+ "top": null,
+ "visibility": null,
+ "width": null
+ }
+ },
+ "fdffb26b99c24c978580f1cf97359fea": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "DescriptionStyleModel",
+ "state": {
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "DescriptionStyleModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "StyleView",
+ "description_width": ""
+ }
+ }
+ }
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 1
+}
diff --git a/Python/Python AI Discord ChatBot/resources/1ezgif.com-gif-maker.gif b/Python/Python AI Discord ChatBot/resources/1ezgif.com-gif-maker.gif
new file mode 100644
index 0000000..50e4241
Binary files /dev/null and b/Python/Python AI Discord ChatBot/resources/1ezgif.com-gif-maker.gif differ
diff --git a/Python/Python AI Discord ChatBot/resources/2gif2.gif b/Python/Python AI Discord ChatBot/resources/2gif2.gif
new file mode 100644
index 0000000..bb4fd69
Binary files /dev/null and b/Python/Python AI Discord ChatBot/resources/2gif2.gif differ