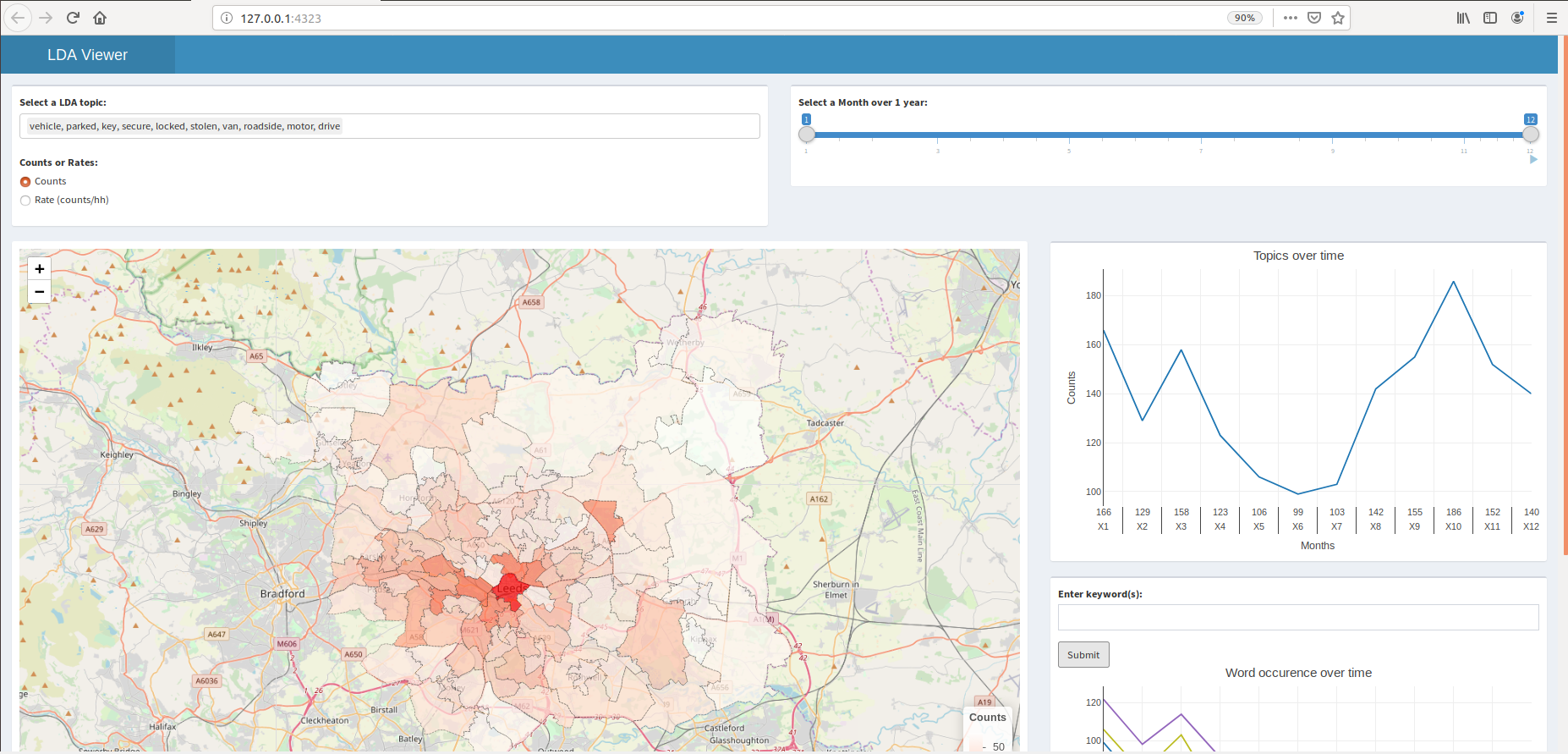
This is an application of topic modelling (that determines topic number) using topic coherence rendering topic data into a Shiny App. This package utilises the Gensim natural language processing library (specificly its wrapper for the Mallet java topic modelling library). The Mallet java library is included in this package for ease of use but full credit and details can be found here.
text_preprocessing - text preprocessing script topic_number_selex - topic number selection script (adjustable parameter controls the number of LDA repeats performed) LDA_dominant_topic_processing - Dominant topic labelling
Data format expected for this is:
| Identifier | CrimeType | OccType | Day | Mon | PartialPostCode | MODescription | CrimeNotes | HOClass | OffenceRec | DomViol |
|---|---|---|---|---|---|---|---|---|---|---|
| int | string category | string category | 3-letter day code | 3-letter month code | 4-5 level postcode | string keywords | string text | string code | string category | Y/N |
This package can be used by building a conda environment as specified by the environment.yml file.
conda env create -f environment.yml
source activate topicmodel1
Then running the setup.py file.
python setup.py install
This will install the package into the pip library within the new conda environment. From there you can run the package by using the master_run.py script.
python topic_model_to_Shiny_app/master_run.py
This will prompt calls for paths to datafiles and path for output file. The process may take some time to run with large datasets and will automatically load a Shiny app if R is installed (loaded required packages using packrat).