简体中文 | English
Arcface-Paddle是基于PaddlePaddle实现的,开源深度人脸检测、识别工具。Arcface-Paddle目前提供了三个预训练模型,包括用于人脸检测的 BlazeFace、用于人脸识别的 ArcFace 和 MobileFace。
- 本部分内容为人脸识别部分。
- 人脸检测相关内容可以参考:基于BlazeFace的人脸检测。
- 基于PaddleInference的Whl包预测部署内容可以参考:Whl包预测部署。
Note: 在此非常感谢 GuoQuanhao 基于PaddlePaddle复现了 Arcface的基线模型。
请参照 Installation 配置实验所需环境。
cd arcface_paddle/
使用下面的命令下载并解压 MS1M 数据集。
# 下载数据集
wget https://paddle-model-ecology.bj.bcebos.com/data/insight-face/MS1M_bin.tar
# 解压数据集
tar -xf MS1M_bin.tar注意:
# 安装 homebrew
ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)";
# 安装wget
brew install wget解压完成之后,文件夹目录结构如下。
Arcface-Paddle/MSiM_bin
|_ images
| |_ 00000000.bin
| |_ ...
| |_ 05822652.bin
|_ label.txt
|_ agedb_30.bin
|_ cfp_ff.bin
|_ cfp_fp.bin
|_ lfw.bin
-
标签文件格式:
# delimiter: "\t" # the following the content of label.txt images/00000000.bin 0 ...
如果需要使用自定义数据集,请按照上述格式进行整理,并替换配置文件中的数据集目录。
注意:
- 这里为了更加方便
Dataloader读取数据,将原始的train.rec文件转化为很多bin文件,每个bin文件都唯一对应一张原始图像。如果您采集得到的文件均为原始的图像文件,那么可以参考3.3节中的内容完成原始图像文件到bin文件的转换。 - 如果你的训练数据为原始的图像文件列表格式,那么在训练的时候,只需要将
is_bin修改为False即可,下面的训练脚本中也会有具体的使用说明。
如果希望将原始的图像文件转换为本文用于训练的bin文件,那么可以使用下面的命令进行转换。
python3.7 tools/convert_image_bin.py --image_path="your/input/image/path" --bin_path="your/output/bin/path" --mode="image2bin"如果希望将bin文件转化为原始的图像文件,那么可以使用下面的命令进行转换。
python3.7 tools/convert_image_bin.py --image_path="your/input/bin/path" --bin_path="your/output/image/path" --mode="bin2image"准备好配置文件后,可以通过以下方式开始训练过程。
# 如果你的训练数据为bin文件格式的图像文件,可以使用下面的命令进行训练
python3.7 train.py \
--network 'MobileFaceNet_128' \
--lr=0.1 \
--batch_size 512 \
--weight_decay 2e-4 \
--embedding_size 128 \
--logdir="log" \
--output "emore_arcface" \
--resume 0
# 如果你的训练数据为原始图像文件,可以将`is_bin`指定为False,进行训练
python3.7 train.py \
--network 'MobileFaceNet_128' \
--lr=0.1 \
--batch_size 512 \
--weight_decay 2e-4 \
--embedding_size 128 \
--logdir="log" \
--output "emore_arcface" \
--resume 0 \
--is_bin False上述命令中,需要传入如下参数:
network: 模型名称, 默认值为MobileFaceNet_128;lr: 初始学习率, 默认值为0.1;batch_size: Batch size 的大小, 默认值为512;weight_decay: 正则化策略, 默认值为2e-4;embedding_size: 人脸 embedding 的长度, 默认值为128;logdir: VDL 输出 log 的存储路径, 默认值为"log";output: 训练过程中的模型文件存储路径, 默认值为"emore_arcface";resume: 是否恢复分类层的模型权重。1表示使用之前好的权重文件进行初始化,0代表重新初始化。 如果想要恢复分类层的模型权重, 需要保证output目录下包含:rank:0_softmax_weight_mom.pkl和rank:0_softmax_weight.pkl两个文件。is_bin: 训练数据是否为bin文件格式,默认为True。
-
训练过程中的输出 log 示例如下:
... Speed 500.89 samples/sec Loss 55.5692 Epoch: 0 Global Step: 200 Required: 104 hours, lr_backbone_value: 0.000000, lr_pfc_value: 0.000000 ... [lfw][2000]XNorm: 9.890562 [lfw][2000]Accuracy-Flip: 0.59017+-0.02031 [lfw][2000]Accuracy-Highest: 0.59017 [cfp_fp][2000]XNorm: 12.920007 [cfp_fp][2000]Accuracy-Flip: 0.53329+-0.01262 [cfp_fp][2000]Accuracy-Highest: 0.53329 [agedb_30][2000]XNorm: 12.188049 [agedb_30][2000]Accuracy-Flip: 0.51967+-0.02316 [agedb_30][2000]Accuracy-Highest: 0.51967 ...
在训练过程中,可以通过 VisualDL 实时查看loss变化,更多信息请参考 VisualDL。
可以通过以下方式开始模型评估过程。
python3.7 valid.py
--network MobileFaceNet_128 \
--checkpoint emore_arcface \上述命令中,需要传入如下参数:
network: 模型名称, 默认值为MobileFaceNet_128;checkpoint: 保存模型权重的目录, 默认值为emore_arcface;
注意: 上面的命令将评估模型文件 ./emore_arcface/MobileFaceNet_128.pdparams .您也可以通过同时修改 network 和 checkpoint 来修改要评估的模型文件。
PaddlePaddle支持使用预测引擎进行预测推理,通过导出inference模型将模型固化:
python export_inference_model.py --network MobileFaceNet_128 --output ./inference_model/ --pretrained_model ./emore_arcface/MobileFaceNet_128.pdparams导出模型后,在 ./inference_model/ 目录下有:
./inference_model/
|_ inference.pdmodel
|_ inference.pdiparams
在MS1M训练集上进行模型训练,最终得到的模型指标在lfw、cfp_fp、agedb30三个数据集上的精度指标以及CPU、GPU的预测耗时如下。
| 模型结构 | lfw | cfp_fp | agedb30 | CPU 耗时 | GPU 耗时 | 模型下载地址 |
|---|---|---|---|---|---|---|
| MobileFaceNet-Paddle | 0.9945 | 0.9343 | 0.9613 | 4.3ms | 2.3ms | 下载地址 |
| MobileFaceNet-mxnet | 0.9950 | 0.8894 | 0.9591 | 7.3ms | 4.7ms | - |
| ArcFace-Paddle | 0.9973 | 0.9743 | 0.9788 | - | - | 下载地址 |
- 注:这里
ArcFace-Paddle的backbone为iResNet50,模型相对较大,在CPU设备或者移动端设备上不推荐使用,因此没有给出具体的预测时间。
测试环境:
- CPU: Intel(R) Xeon(R) Gold 6184 CPU @ 2.40GHz
- GPU: a single NVIDIA Tesla V100
融合人脸检测过程,可以完成"检测+识别"的人脸识别过程。
首先下载索引库、待识别图像与字体文件。
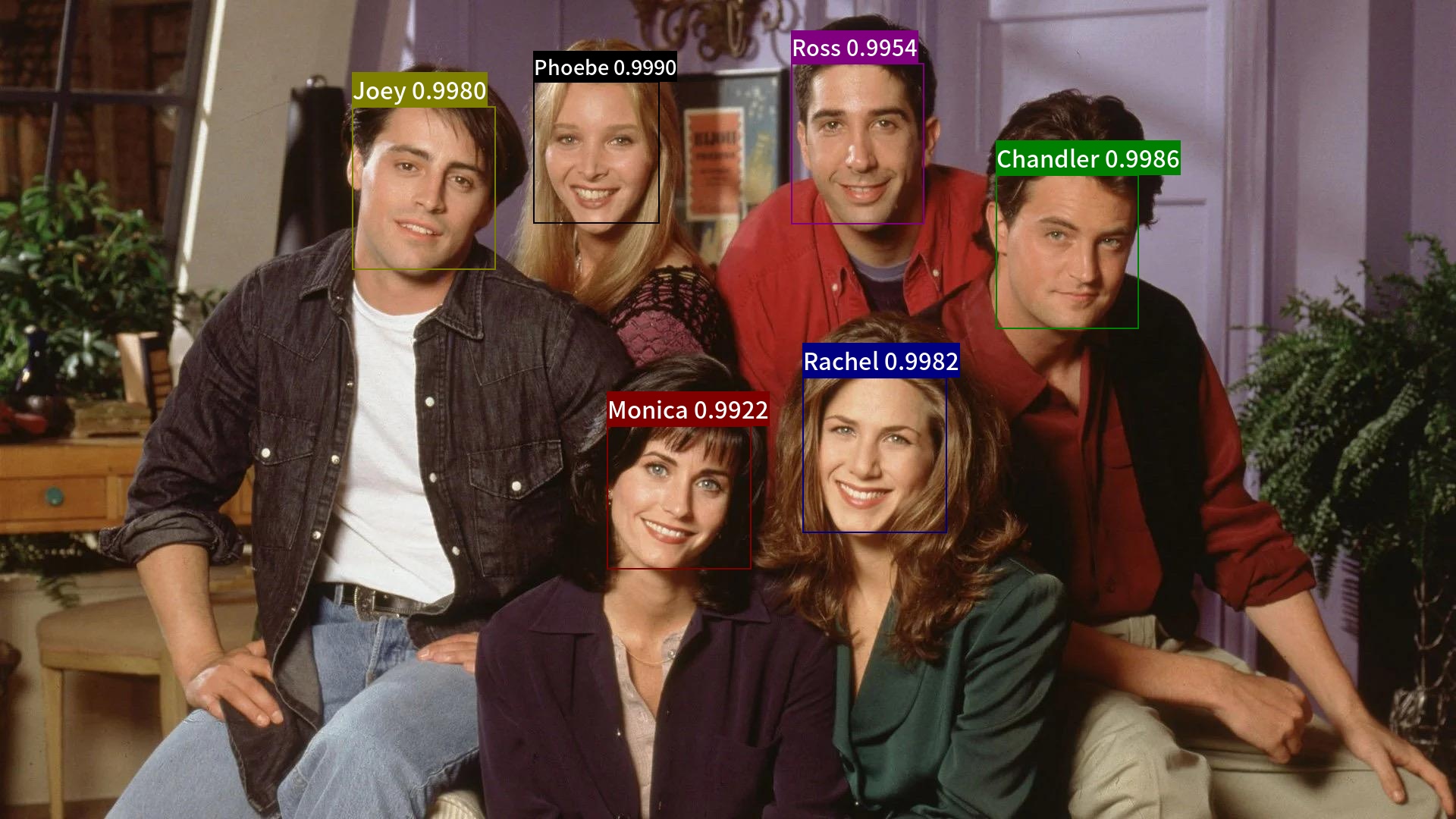
# 下载用于人脸识别的索引库,这里因为示例图像是老友记中的图像,所以使用老友记中角色的人脸图像构建的底库。
wget https://raw.githubusercontent.com/littletomatodonkey/insight-face-paddle/main/demo/friends/index.bin
# 下载用于人脸识别的示例图像
wget https://raw.githubusercontent.com/littletomatodonkey/insight-face-paddle/main/demo/friends/query/friends2.jpg
# 下载字体,用于可视化
wget https://raw.githubusercontent.com/littletomatodonkey/insight-face-paddle/main/SourceHanSansCN-Medium.otf示例图像如下所示。

检测+识别串联预测的示例脚本如下。
# 同时使用检测+识别
python3.7 test_recognition.py --det --rec --index=index.bin --input=friends2.jpg --output="./output"最终可视化结果保存在output目录下,可视化结果如下所示。
更多关于参数解释,索引库构建、whl包预测部署的内容可以参考:Whl包预测部署。