❗ This code really sucks. I'll rewrite it when I have free time. 这项目写的很烂,仅供参考,后续有时间会重构……


A free proxy server based on Tornado and Scrapy.
Build your own proxy pool!
Features:
- continuously crawling and providing free proxies
- asynchronous and high-perfermance
- automatically check proxies in cycle and ditch unavailable ones
- easy-to-use HTTP api
免费代理服务器,基于Tornado和Scrapy,在本地搭建自己的代理池
- 持续爬取新的免费代理,检测可用后存入本地数据库
- 完全异步,支持高并发
- 易用的HTTP API
- 周期性检测代理可用性,自动更新
This project has been tested on:
- Archlinux; Python-3.6.5
- Debian(WSL, Raspbian); Python-3.5.3
And it cannot directly run on Windows. Windows users may try using Docker or WSL to run this project.
Choose either one option as follows. After successful deployment, use the APIs to get proxies.
The easiest way to run this repo is using Docker. Install Docker and then run:
# download the image
docker pull karmenzind/fp-server:stable
# run the container
# don't forget to modify `-p` if you prefer another port
docker run -itd --name fpserver -p 12345:12345 karmenzind/fp-server:stable
# check the output inside the container
docker logs -f fpserverFor custom configuratiuon, see this section.
- Install Redis and
python>=3.5(I use Python-3.6.5). - Clone this repo.
- Install python packages by:
pip install -r requirements.txt- Read the config and modify it according to your need.
- Start the server:
python ./src/main.pytypical response:
{
"code": 0,
"msg": "ok",
"data": {}
}- code: result of event (not http code), 0 for sucess
- msg: message for event
- data: detail for sucessful event
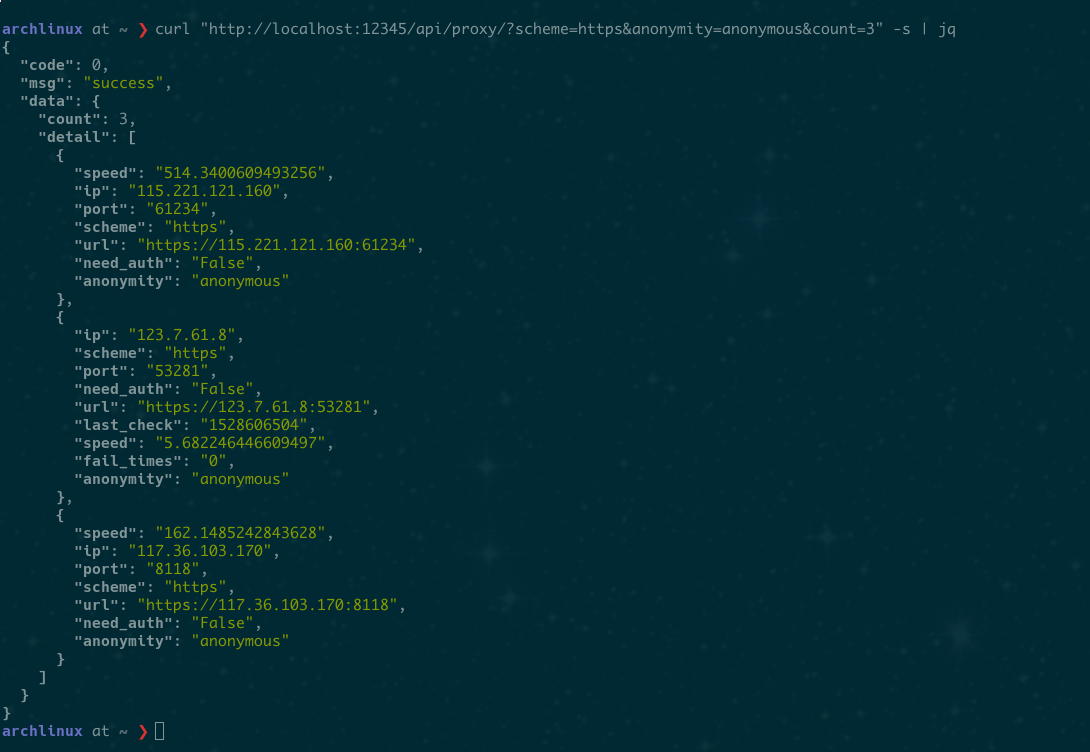
GET /api/proxy/
| params | Must/ Optional |
detail | default |
|---|---|---|---|
| count | O | the number of proxies you need | 1 |
| scheme | O | choices:HTTP HTTPS |
both* |
| anonymity | O | choices:transparent anonymous |
both |
| (TODO) sort_by_speed |
O | choices: 1: desending order 0: no order -1: ascending order |
0 |
- both: include all type, not grouped
example
- To acquire 10 proxies in HTTP scheme with anonymity:
The response:
GET /api/proxy/?count=10&scheme=HTTP&anonymity=anonymous{ "code": 0, "msg": "ok", "data": { "count": 9, "items": [ { "port": 2000, "ip": "xxx.xxx.xx.xxx", "scheme": "HTTP", "url": "http://xxx.xxx.xxx.xx:xxxx", "anonymity": "transparent" } ] } }
screenshot
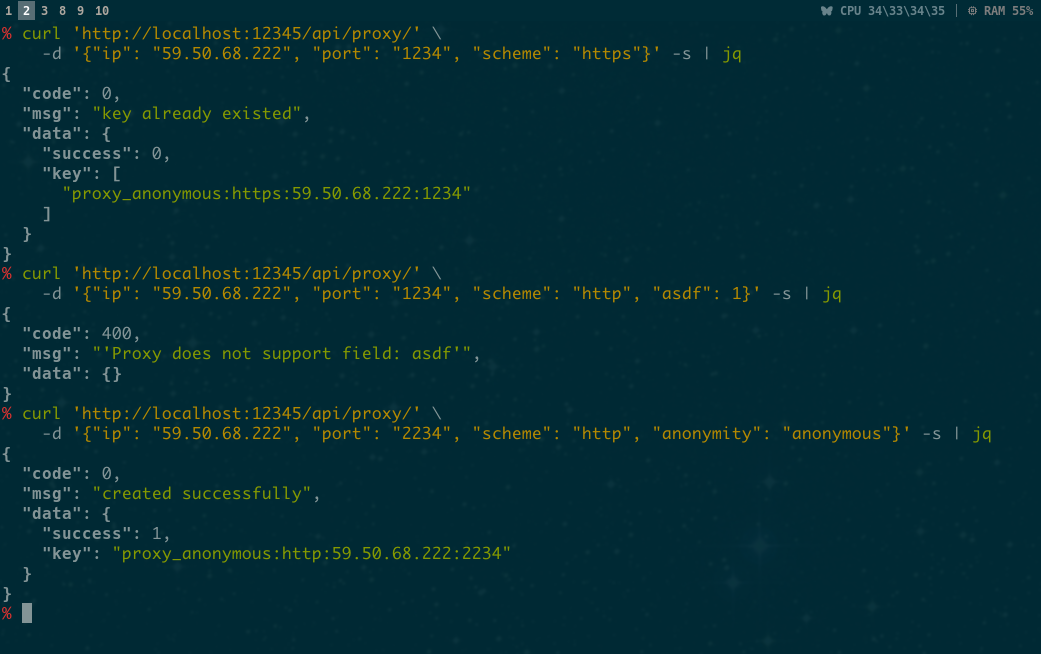
POST /api/proxy/
| params | Must/ Optional |
detail | default |
|---|---|---|---|
| ip | M | e.g. 111.111.111.111 | |
| port | M | e.g. 12345 | |
| scheme | M | choices:HTTP HTTPS |
|
| anonymity | O | choices:transparent anonymous |
transparent |
| need_auth | O | choices: 0 1 | |
| user | O | ||
| password | O | ||
| url | O | generated by given scheme+ip+port |
screenshot
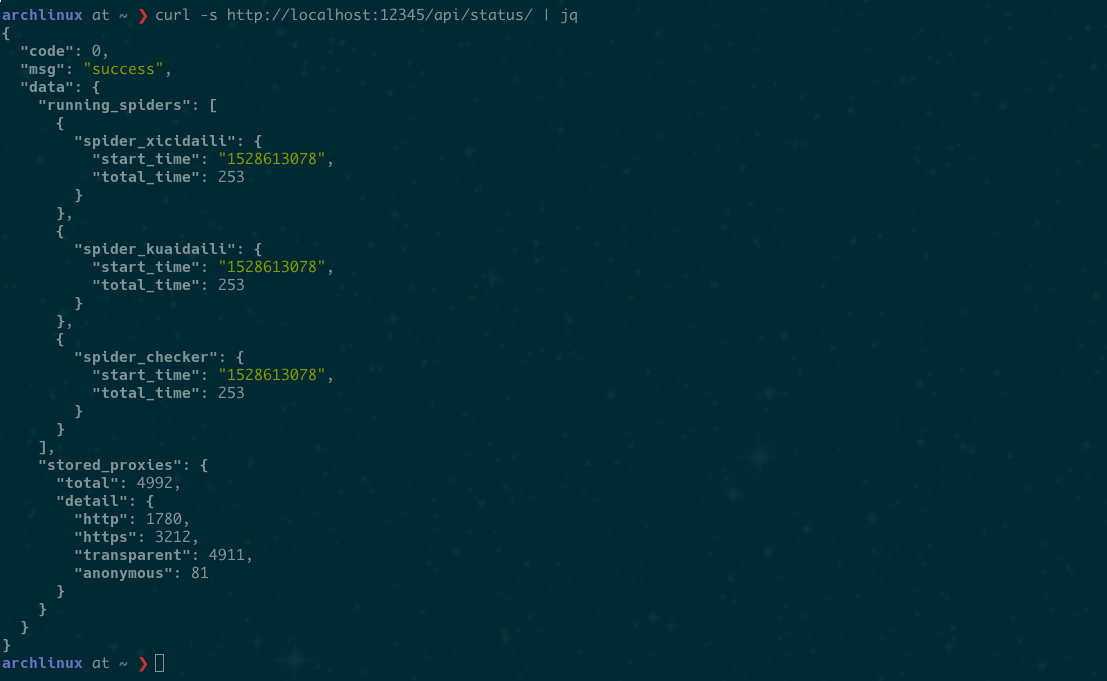
Check server status. Include:
- Running spiders
- Stored proxies
GET /api/status/
No params.
screenshot
I choose YAML language for configuration file. The defination and default value for supported items are:
# server's http port
HTTP_PORT: 12345
# redirect output to console other than log file
CONSOLE_OUTPUT: 1
# Log
# dir and filename requires `CONSOLE_OUTPUT: 0`
LOG:
level: 'debug'
dir: './logs'
filename: 'fp-server.log'
# redis database
REDIS:
host: '127.0.0.1'
port: 6379
db: 0
password:
# stop crawling new proxies
# after stored this many proxies
PROXY_STORE_NUM: 500
# Check availability in cycle
# It's for each single proxy, not the checker
PROXY_STORE_CHECK_SEC: 3600- If you use Docker:
- Create a directory such as
/x/config_dirand put yourconfig.ymlin it. Then modify the docker-run command like this:docker run -itd --name fpserver -p 12345:12345 -v "/x/config_dir":"/fps-config" karmenzind/fp-server:stable - External
config.ymldoesn't need to contain all config items. For example, it can be:And other items will be default values.PROXY_STORE_NUM: 100 LOG: level: 'info' PROXY_STORE_CHECK_SEC: 7200 - If you need to set a log file, don't modify
LOG-dirinconfig.yml. Instead create a directory for log file such as/x/log_dirand change the docker-run command like:docker run -itd --name fpserver -p 12345:12345 -v "/x/config_dir":"/fps_config" -v "/x/log_dir":"/fp_server/logs" karmenzind/fp-server:stable - There's no need to modify the exposed port of the container. If you prefer publishing it to another port(say, 9999) on the host, change the
-pparameter in docker-run command to-p 9999:12345 - If you need to access the Redis from host, add a new publishing parameter like
-p 6379:6379to docker-run command.
- Create a directory such as
- If you manually deploy the project:
- Modify the internal config file:
src/config/common.py
- Modify the internal config file:
Growing……
If you knew good free-proxy websites, please tell me and I will add them to this project.
Supporting:
- 西刺代理
- 快代理
- 云代理
- 66免费代理
- 无忧代理
- 3464
- coderbusy
- ip181
- iphai
- a2u
- coolproxy
- 万能代理
- 小幻代理 (figuring)
- 89免费代理(figuring)
-
baizhongsou(stop providing free proxies)
-
How about the availability and quality of the proxies?
Before storing new proxy, fp-server will check its availability, anonymity and speed based on your local network. So, feel free to use the crawled proxies.
-
How many
PROXY_STORE_NUMshould I set? Is there any limitation?You should set it depends on your real requirement. If your project is a normal spider, then 300-500 will be fair enough. I haven't set any limitation for now. After stored 10000 available proxies, I stopped testing. The upper limit is relevant to source websites. I will add more websites if more people use this project.
-
How to use it in my project?
See the next section.
These code can be directly copied to your project. Remember to modify the configuration and settings at first.
I will write more snippets at leisure. Or you can tell me what example you want.
Here is a middleware for Scrapy to fetch and apply proxy for each request. Copy it to your middlewares.py and add the name to DOWNLOADER_MIDDLEWARES in your settings.py.
If you want to keep a cookie pool for your proxies(an independent cookiejar for each IP), this middleware may help you.
I need your feedback to make it better.
Please create an issue for any problems or advice.
Known bugs:
- Block while using Tornado-4.5.3
- Afer check, the redis key might change
- Use ZSET
- Add supervisor
- Divide log module
- More detailed api
- Web frontend via bootstrap
- Add user-agent pool
- the checker's scheduler:
- Periodically calculating the average speed of checking request, then reassign the checker based on this average and the quantity of stored proxies.
- Provide region information.
- use redis's HSET for calculation