原文出处:https://iming.work/detail/61cbfb7e316b076c47ddee0a.html
早些时间对这一知识点有一些归纳总结:用 Js 读写 binary data
binary 翻译过来就是“二进制”的意思。
在 js 中,binary string 是一种字符集,类似于 ascii、unicode 字符集,用来表示二进制数据的。
在 ascii 中,对于单字节字符,一个字节是 8 位,除去符号位最多 127 个字符。
在 binary string 中,没有符号位,所以能表示 255 个字符。
为什么要设计 binary 字符集呢?是用来在 js 中快速处理二进制数据,换句话说,在 XMLHttpRequest 中用来传递和接收二进制数据用的。
所以,在接口中处理文件时,只需要使用无符号 8 位 Uint8 的 typed array 方法即可满足,而不用担心 Range error。
譬如,字符 À 是超出 ascii 范围的,但可以使用 binary string 表示。
'A'.charCodeAt() // 65
'À'.charCodeAt() // 192在 node 中类似的是 Buffer,其它语言称之为 byte array,是可以在内存申请一块固定大小的区域用来读写数据,非常快。
由于在浏览器中不能直接读写文件,所以为了能方便操作二进制数据,提供了这一对象,但是该对象不能直接被操作,需要使用额外的 Api 来读写,因为为了抹平一些符号以及字节序的问题。
Api 有 2 种:DataView 和 TypedArray,DataView 可以理解为对 TypedArray 的封装,更简单易用一些。
譬如在与后端对接过程中,最常见的是处理有 2 种
-
后端返回二进制文件即 Blob 对象
// 直接使用 FileReader 读取 Blob 对象 const reader = new FileReader() // 导出为 DataURL,赋值给 a 标签就可以实现下载 reader.readAsDataURL(blob)
-
后端返回 Buffer 数据——一个 binary 字符集的数组
// 如果返回 buffer data 的格式 // 需要转化为 js 中的 ArrayBuffer const buffer = new ArrayBuffer(bufData.length) const view = new DataView(buffer) for (let i = 0; i < bufData.length; i++) { view.setUint8(i, bufData[i]) } // 再转为 blob 对象 const blob = new Blob([view])
Blob 本身就是 binary large object 表示大的二进制文件,本质也是可以使用 ArrayBuffer 进行操作,只不过太大,反而会增加运行内存使用,降低效率。
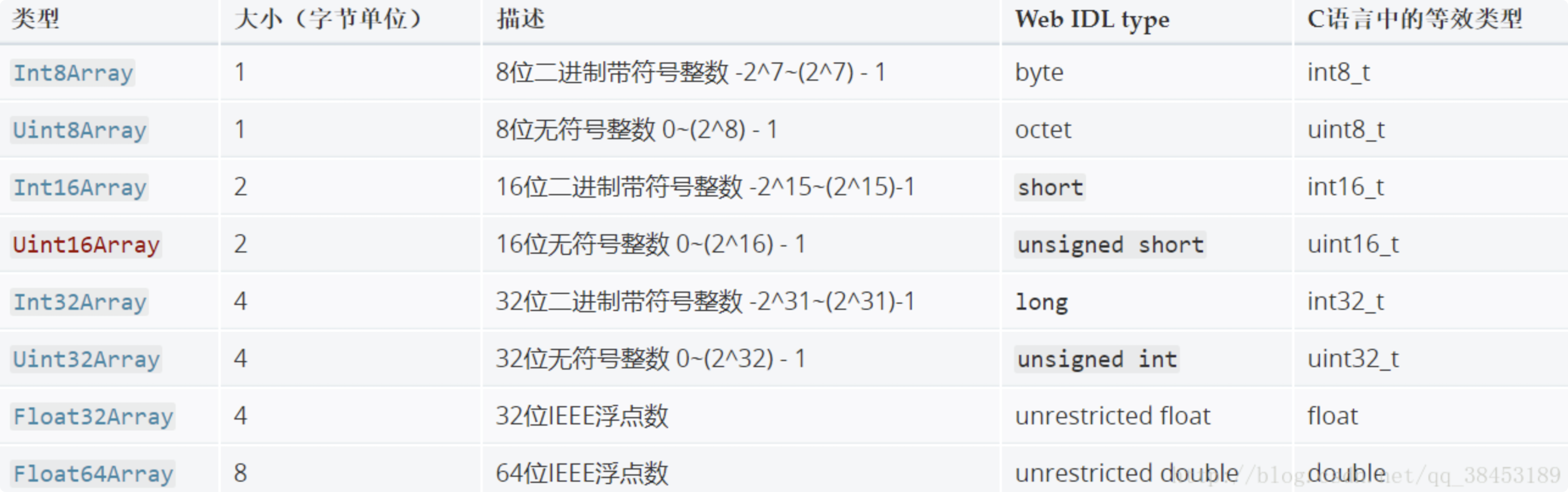
上面有提到 DataView 其实是对 TypedArray 关于字节偏移、字节编码的一层封装,TypedArray 本身不能直接被实例化,提供了 Int8Array 、Int16Array 、Int32Array 等构造函数用来处理不同字符集范围内的字符。
我们需要了解,ascii、binary、或者 base64 所使用的字符集,都是 unicode 的子集,那么问题来了,什么时候使用 Int8Array 、Uint8Array 什么时候使用 Int16Array 呢?我们可以简单的理解为:当操作的字符属于哪个范围就使用哪种方式。
譬如,可以使用 charCodeAt() 来获取 unicode 基本平面的码点值,当然也可以使用 unicode 获取码点的专用方法 codePointAt() ,在基本平面(0 - 65535) 码点范围内的字符得到的值是一样的。
可以根据码点值来判断当前字符属于哪个字符集,从而使用不同的字节编码方式。
那么有人会问了,可以使用 Int8Array 方式存储的字符是不是也可以使用 Int16Array 来存储?答案是:当然。
但是有个很显然的问题:存储的内存翻倍了,如下图所示
譬如一段字符:‘hello’ 长度为 5,在 ascii 范围内,为单字节字符,那么使用 5 个字节长度即可存储。
但是,如果使用 Int16Array 就需要 10 个字节长度了。
如果还不理解,为什么 Int16Array 需要 2 个字节,因为 1 个字节是 8 位,在 unicode 基本平面内的码点范围用 16 进制表示是 0000 - FFFF,如果用 2 进制表示就是 00000000 00000000 - 11111111 11111111 ,如果用字节来表示,就是 2 个字节了。
ArrayBuffer 与 ‘hello’ 字符的互相转换
-
获取 ‘hello’ 字符对应的码点:
[104, 101, 108, 108, 111] -
使用 2 个 ArrayBuffer 分别使用
Int8Array和Int16Array存储const pointArr = [104, 101, 108, 108, 111] // Int8Array const buf1 = new ArrayBuffer(5) const view1 = new DataView(buf1) for (let i = 0; i < pointArr.length; i++) { view1.setInt8(i, pointArr[i]) } // Int16Array const buf2 = new ArrayBuffer(5 * 2) const view2 = new DataView(buf2) for (let i = 0; i < pointArr.length; i++) { // byteOffset 字节偏移也需要相应的处理 view2.setInt16(i * 2, pointArr[i]) }
Int8Array存储结果如下图,符合预期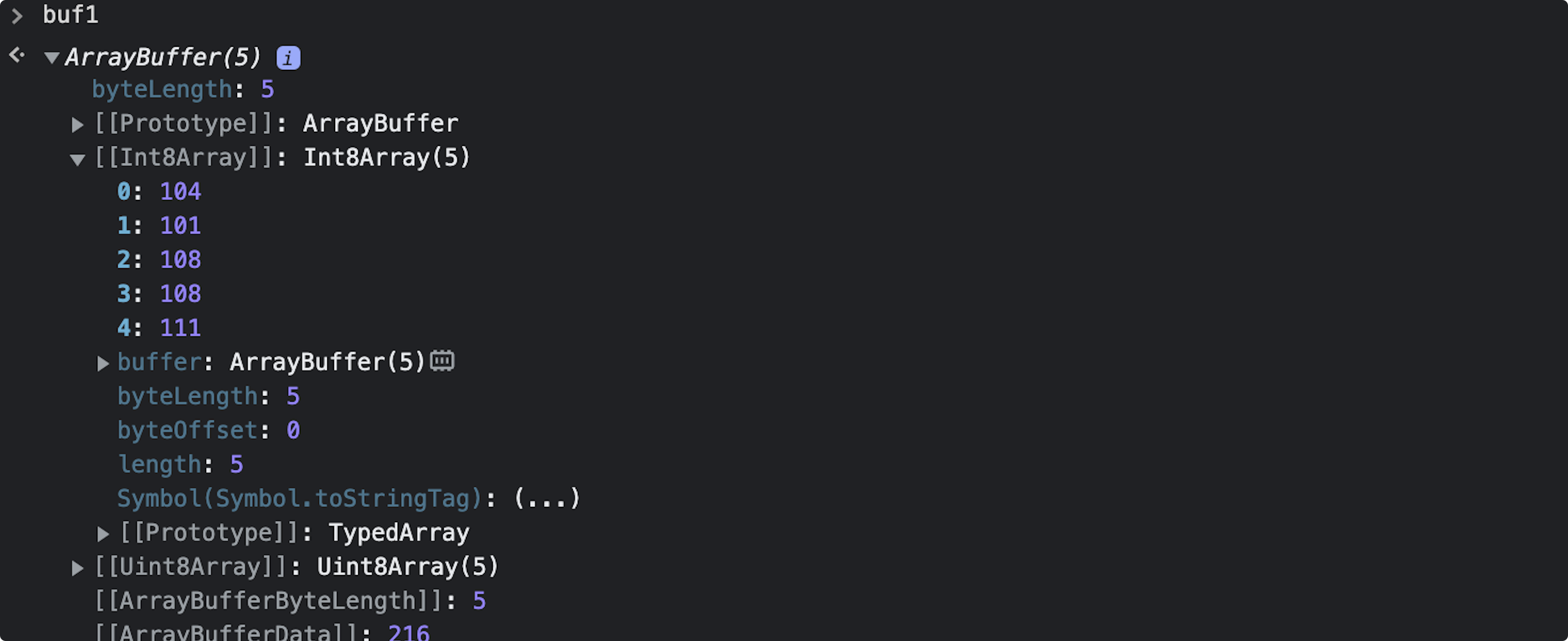
Int16Array存储结果如下图,符合预期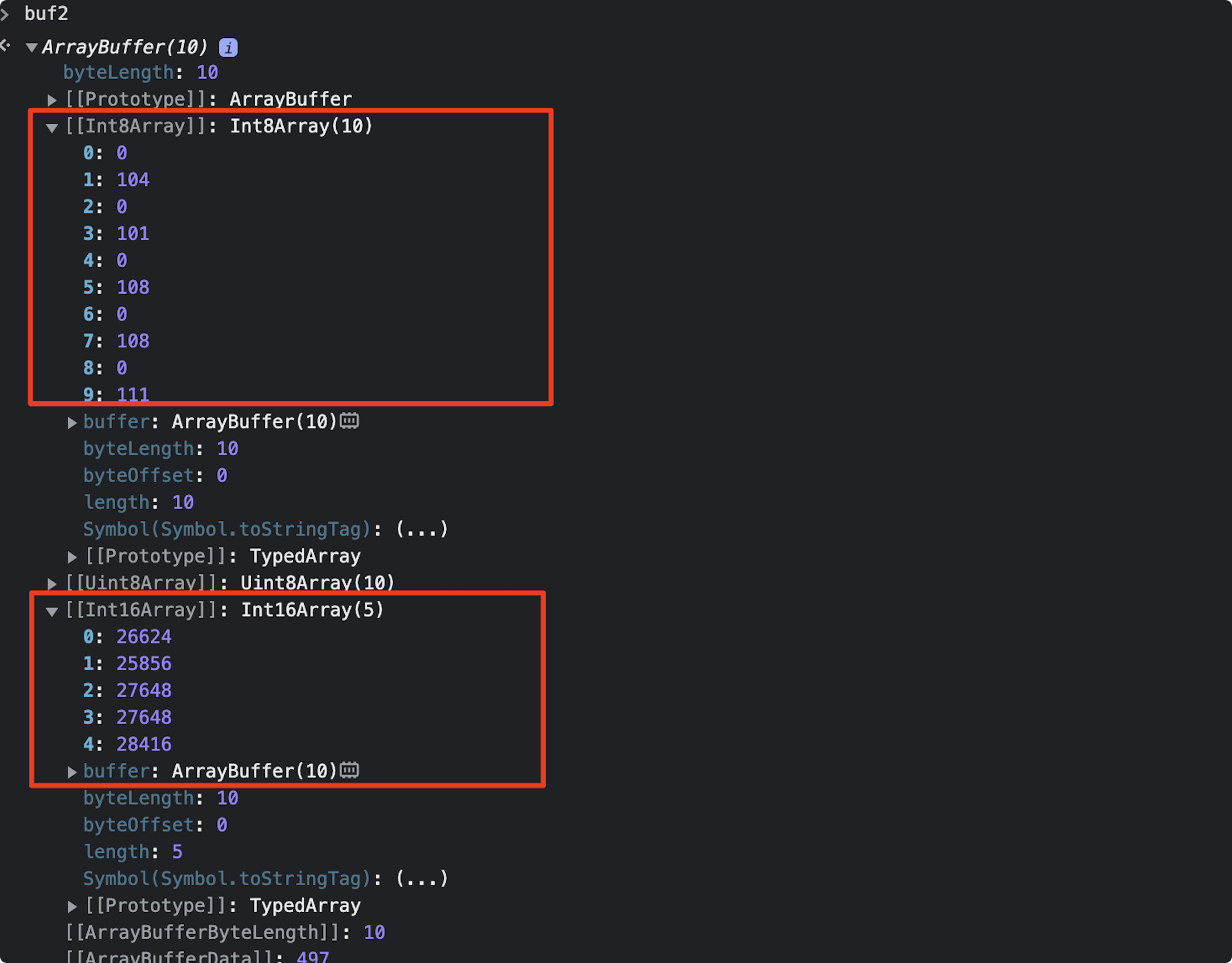
在
Int16Array,每一位存放的都是 unicode 码点,譬如// 第一位码点转化为二进制表示 26624..toString(2) // 得到完整的 16 进制表示 01101000 00000000
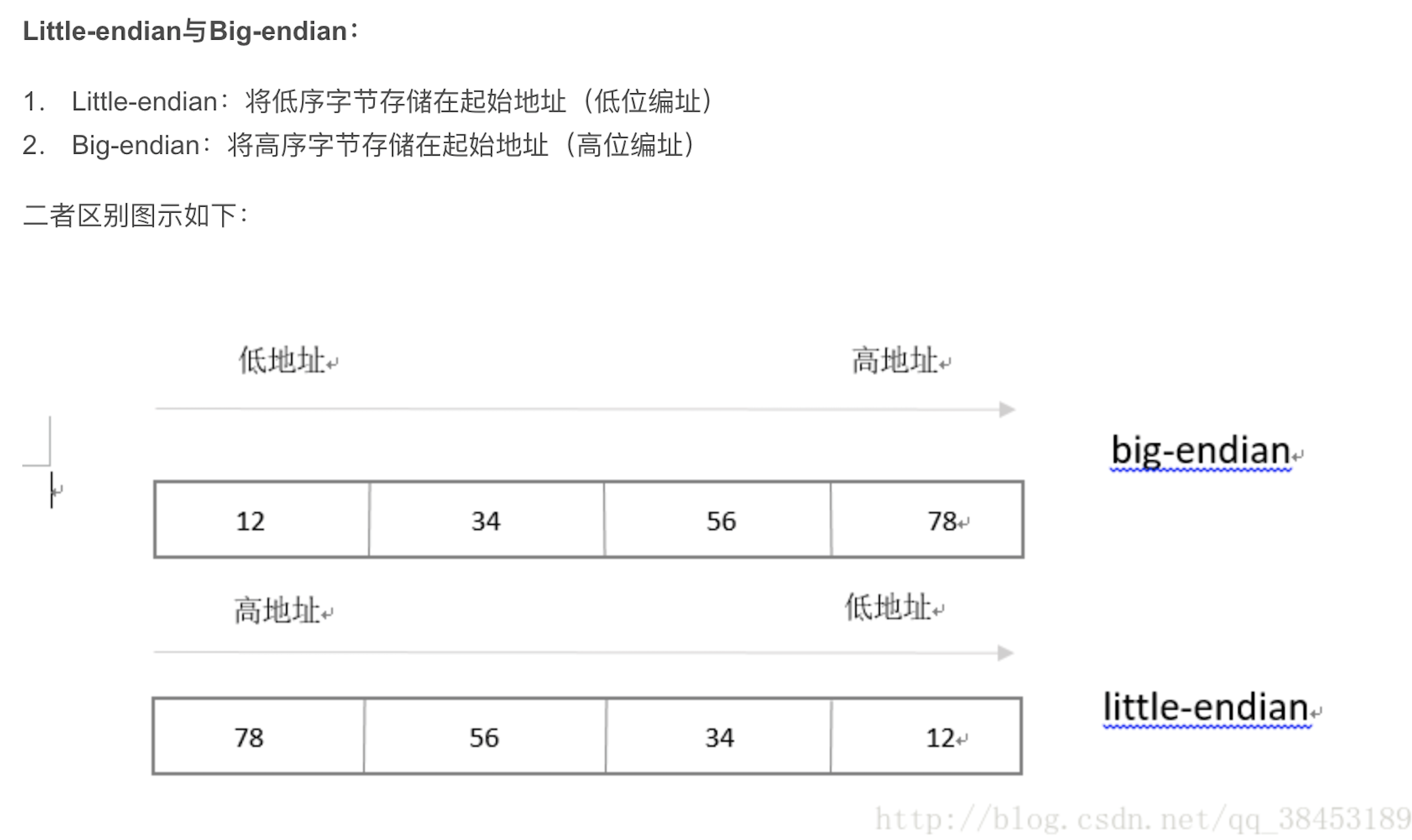
计算机都采用小端字节序(little endian),相对重要的字节排在后面的内存地址,相对不重要字节排在前面的内存地址
所以实际存储的是
00000000 01101000
转化为十进制表示就是 104,其它位数的计算同理。
其实,我们也可以从上图中看到
Int8Array中浪费了一位存储。 -
接着,我们再将 ArrayBuffer 转化为字符串
// 将 buffer 转化为 Blob 对象 const blob = new Blob([view2]) // 进而使用浏览器中的文件读取功能 const reader = new FileReader() reader.readAsText(blob) reader.onload = (e) => { console.log(e.target.result) // hello }
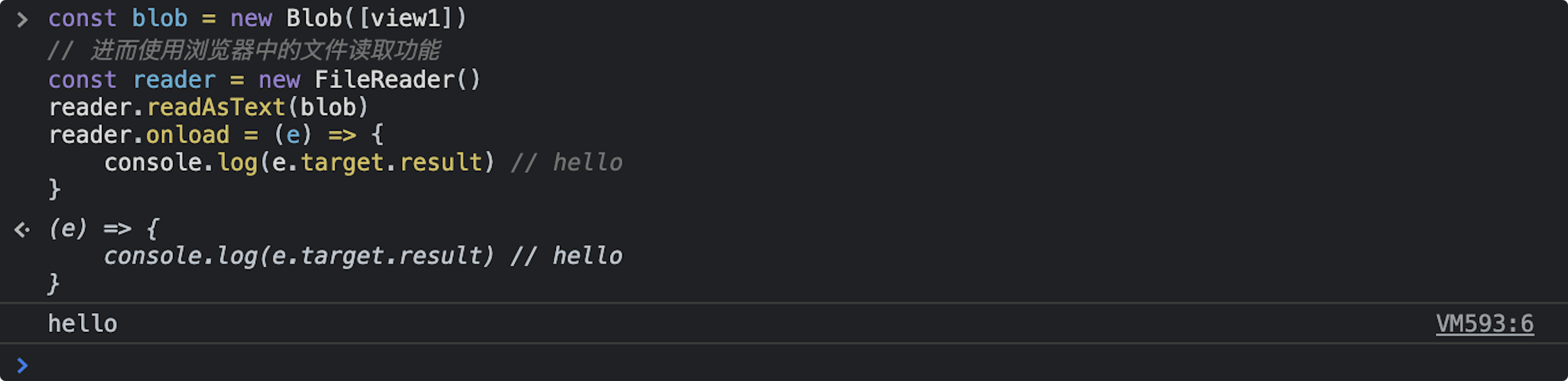
值得注意的是,在前后端交互的场景中,由于只会使用到 binary string,所以不用担心字节位数的问题,选用 Uint8Array 去读写 ArrayBuffer 即可,虽然也能使用 Int16Array 正常读写 ArrayBuffer,但是,在内存中的存储不连续了(中间位数为空的 0),导致文件不能正常被计算机读取显示。
-
关于 Int16Array 和 Int8Array 的转换从这篇文章了解到字节序、补码的基础知识:理解ArrayBuffer存储
-
关于字节序,这篇文章末尾 也参考了些,可以帮助加深理解