diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000..92d902f
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,2 @@
+/.quarto/
+_site/
\ No newline at end of file
diff --git a/_quarto.yml b/_quarto.yml
new file mode 100644
index 0000000..47c217c
--- /dev/null
+++ b/_quarto.yml
@@ -0,0 +1,91 @@
+project:
+ type: website
+
+website:
+ title: "Données émergentes"
+ navbar:
+ left:
+ - text: "Home"
+ file: index.qmd
+ - text: "Introduction"
+ file: introduction.qmd
+ - text: "Données administratives"
+ menu:
+ - administratives.qmd
+ - administratives_exemples.qmd
+ - text: "Données géolocalisées"
+ file: geolocalized_data.qmd
+ - text: "Analyse textuelle"
+ menu:
+ - textes.qmd
+ - textes_exemples.qmd
+ - text: "Analyse d'images"
+ menu:
+ - images.qmd
+ - images_exemples.qmd
+ - text: "Nowcasting"
+ menu:
+ - series_temporelles.qmd
+ - nowcasting_exemples.qmd
+ sidebar:
+ style: "docked"
+ search: true
+ contents:
+ - section: "Introduction"
+ contents:
+ - introduction.qmd
+ - section: "Données administratives"
+ contents:
+ - administratives.qmd
+ - administratives_exemples.qmd
+ - section: "Données géolocalisées"
+ contents:
+ - geolocalized_data.qmd
+ - section: "Analyse textuelle"
+ contents:
+ - textes.qmd
+ - textes_exemples.qmd
+ - section: "Analyse d'images"
+ contents:
+ - images.qmd
+ - images_exemples.qmd
+ - section: "Nowcasting"
+ contents:
+ - series_temporelles.qmd
+ - nowcasting_exemples.qmd
+ tools:
+ - icon: twitter
+ href: https://twitter.com
+ - icon: github
+ menu:
+ - text: Source Code
+ url: https://github.com/linogaliana/ensai-donnees-emergentes
+ - text: Report a Bug
+ url: https://github.com/linogaliana/ensai-donnees-emergentes/issues
+ page-navigation: true
+ page-footer:
+ left: "(c) 2022, Lino Galiana and Tom Seimandi"
+ right:
+ - icon: github
+ href: https://github.com/linogaliana/ensai-donnees-emergentes
+ - icon: twitter
+ href: https://twitter.com/
+ reader-mode: true
+ repo-url: https://github.com/linogaliana/ensai-donnees-emergentes
+ repo-actions: [edit, issue]
+ twitter-card:
+ creator: "@linogaliana"
+ open-graph: true
+
+
+bibliography: references.bib
+
+format:
+ html:
+ theme: cosmo
+ css: styles.css
+ toc: true
+
+theme:
+ light: flatly
+ dark: darkly
diff --git a/administratives.qmd b/administratives.qmd
new file mode 100644
index 0000000..1e8a81b
--- /dev/null
+++ b/administratives.qmd
@@ -0,0 +1,487 @@
+---
+title: "Données administratives"
+---
+
+La
+baisse généralisée au niveau
+européen des taux de réponse[^1] [@LuitenHoxde; @beck2022],
+qui accroît les coûts de collecte et
+rend plus difficile celle-ci sur certaines
+sous-populations, notamment les plus jeunes,
+nécessite de trouver des solutions pour
+répondre à la demande toujours accrue de
+statistique officielle.
+
+[^1]: Par exemple, le taux de réponse a baissé pour l'enquête en face-à-face Cadre de vie et sécurité de 72 % à 66 % entre
+2012 et 2021. En ce qui concerne SRCV (Statistiques sur les ressources et les conditions de vie), le taux
+de réponse est passé de 85 % à 80 % entre 2010 et 2019. Des événements
+ponctuels comme la crise du Covid-19 peuvent de plus avoir des
+effets très forts sur le taux de réponse.
+Par exemple, en 2020, à la date du 23 avril, le taux de réponse à l'enquête sur la production industrielle en mars, qui sert d'indicateur avancé de l'activité économique,
+était inférieur d'environ 20 points de pourcentage à ce qui est observé lors d’un mois habituel (voir [blog de l'Insee](https://blog.insee.fr/suivre-la-conjoncture-lorsque-les-entreprises-repondent-moins-aux-enquetes/)).
+
+
+Comme développé dans l'introduction, les données
+administratives sont des données de gestion
+produites par l'administration.
+Le processus de production statistique, où la collecte
+de donnée est construite de manière à mesurer
+le plus objectivement possible un phénomène cible,
+diffère du processus de production administratif.
+Pour cette dernière, la donnée est produite de sorte
+à faciliter la gestion. L'exploitation de celle-ci
+à des fins de production de statistique ou de recherche
+n'est pas le moteur de leur construction. L'exploitation
+de cette donnée est une affaire d'opportunité.
+Cette perte de contrôle du processus de production, qui
+fait que l'exploitant de la donnée se retrouve en aval
+de son processus de production, a tout de même des bénéfices :
+l'exhaustivité sur une population cible et
+la plus haute fréquence de ces données.
+Ceci explique qu'elles deviennent de plus en plus importantes
+dans la production de statistique officielle.
+
+Ce chapitre revient sur le contexte d'utilisation des données
+administratives, leurs différences avec d'autres sources
+de données et les apports de celles-ci à la production
+de savoir statistique.
+
+
+# Contexte
+
+> In this world, nothing is certain except death and taxes.
+>
+> Benjamin Franklin
+
+## Nature des données
+
+Les données statistiques traditionnelles (sondage ou recensement)
+sont produites pour informer. Cette finalité guide la conception
+de celles-ci, que ce soit au niveau du _design_, des concepts
+mesurés ou des retraitements post-collecte.
+La logique des données administratives est toute autre.
+Il s'agit de bases dont la finalité de construction est
+la gestion, c'est-à-dire l'enregistrement d'événements
+pour déclencher des actions (remboursement, paiement, etc.).
+
+Cet aspect transactionnel de la donnée adminstrative change ainsi
+le processus de production. Ces bases sont susceptibles d'être mises
+à jour à plusieurs échéances. D'abord, leur structure n'est
+pas figée dans le temps. Selon les événements à enregistrer, la
+structure du fichier de données évoluera. Par exemple, un nouveau
+crédit d'impôt amènera à l'ajout d'une catégorie dans les déclarations
+fiscales ce qui se traduira par un changement du fichier de gestion.
+A ce premier facteur d'évolution peut s'ajouter des changements à
+plus brève échéance. La collecte de données administratives est un
+processus vivant. Les données sont généralement modifiables
+au cours d'un exercice de gestion voire au-delà. La
+donnée n'est stabilisée qu'après plusieurs cycles de gestion
+et sa continuité, au niveau de l'unité statistique, ne va
+pas de soi. Par exemple, une entreprise changeant d'identifiant
+SIREN pour une raison
+liée à un changement administratif (par exemple une fusion)
+ne sera identifiable dans différents millésimes de données
+administratives que si on est en mesure de relier
+les différents identifiants sous lequel elle apparaît.
+
+Les données administratives peuvent provenir de plusieurs origines.
+Elles sont en premier lieu issues de processus de gestion interne à l’administration concernée.
+Par exemple, pour être en mesure de gérer les remboursements liés au système de
+protection sociale français, l'assurance maladie collecte et enregistre de nombreuses
+informations sur les actes médicaux. Cette collecte est automatisée grâce à la carte
+vitale et au système d'information de l'assurance maladie ou passe par des déclarations papiers
+normalisées.
+
+Une seconde source d'origine des données administratives sont les
+déclarations administratives[^2] [@riviere2018].
+Par exemple, les déclarations fiscales des ménages
+sont annuelles, avec un calendrier déterminé à l'avance (qui dépend du format, papier ou internet).
+Ce calendrier inclut d'ailleurs des possibilités allongées de retour sur la donnée fournie.
+L'obligation de certaines déclarations administratives
+se traduit par un pouvoir coercitif, pouvant prendre diverses formes, comme celle d’engager des poursuites.
+Ceci réduit le risque de non-déclaration ou de déclaration faussée mais ne l’annihile pas non plus.
+Selon la nature de la donnée, ces poursuites peuvent être pénales et les amendes non négligeables.
+L'existence de ces moyens coercitifs permet d'anticiper
+une information exhaustive sur la sous-population concernée par la donnée et
+honnête[^3].
+
+[^2]: Obligation est faite à un certain nombre d’entités (individus, entreprises, organismes publics) de fournir des informations respectant une certaine forme, selon certaines modalités (internet, papier) et temporalités.
+
+[^3]: Certaines enquêtes, reconnues d'utilité publique, comme l'enquête
+emploi, le recensement ou encore l'enquête ressources et conditions
+de vie (SRCV), sont obligatoires. Bien que cela permette d'avoir des taux
+de réponse élevés, cela n'assure pas un taux de 100%. Comme cela a été
+évoqué précédemment, le taux de réponse de SRCV
+est par exemple passé de 85 % à 80 % entre 2010 et 2019.
+Pour plus d'informations sur les enquêtes obligatoires, voir
+[la description du CNIS](https://www.cnis.fr/obligation-de-reponse/)
+et la liste des enquêtes concernées
+parmi [les enquêtes auprès des particuliers](https://www.insee.fr/fr/information/5390996).
+
+Si les données administratives sont devenues centrales dans le champ
+de la production statistique, c'est certes de par leur nature
+exhaustive mais aussi du fait de leur disponibilité à faible coût marginal.
+Les données administratives étant collectées et centralisées dans un
+système informatique à des fins de gestion, leur mise à disposition
+pour d'autres usages, s'il soulève certains enjeux sur lesquels
+nous reviendrons comme les questions de confidentialité,
+est marginalement peu coûteux. L'utilisation de ces données
+est ainsi une affaire d'opportunité: comme ces données
+sont disponibles et, sous un certain cadre juridique et technique,
+peuvent être ré-utilisables à d'autres fins, si elles fournissent
+une information de qualité, il est utile pour la production
+statistique de les exploiter.
+
+## Quelle différence avec les autres sources de données numériques ?
+
+Cette propriété des données administratives qu'est le coût
+marginal faible
+rapproche celles-ci des traces numériques.
+Les entreprises du numérique
+ont pu centrer leur modèle économique
+autour de la collecte et de la valorisation
+de données justement parce que la collecte
+de nouvelles informations est d'un coût marginal
+nul.
+Il en va de même avec les données de gestion: la collecte
+d'une information supplémentaire sur une unité ou d'une unité
+supplémentaire n'est pas coûteuse. Dans le monde de la donnée
+numérique, il est certes nécessaire d'engager des investissements
+pour être en mesure de collecter des données de manière massive
+ou mettre à l'échelle un processus de collecte devenu plus
+ambitieux que le plan initial mais la donnée marginale
+ne coûte pas très cher puisque, comme nous allons le voir,
+la collecte de celle-ci est reportée
+sur un tiers.
+
+Dès lors, la distinction entre données administratives et données
+numériques, telles qu'on peut formaliser le _buzzword_ "big-data",
+apparaît floue. La distinction correspond en premier lieu à l'origine des données.
+La donnée administrative est une donnée produite par
+la sphère administrative. Dans sa nature, son processus de
+production ne diffère pas de celui de la donnée privée. Dans les deux
+cas, un acteur effectue une activité (par exemple déclarer quelque chose)
+et cette activité va être transformée en information plus ou moins
+normalisée pour intégrer un système d'information et être stockée
+dans les serveurs d'un acteur centralisateur. Dans les deux cas,
+la personne dont la donnée a été collectée pourra éventuellement
+corriger l'information et/ou produire de nouvelles activités.
+
+La différence entre données administratives et données
+privée est ainsi plutôt une différence de degré que de nature.
+Les données administratives sont généralement collectées à plus faible fréquence.
+Par exemple, le rythme de collecte de nombreuses données est annuel pour
+correspondre aux rythmes des campagnes fiscales. Mais certaines sources sont
+à des rythmes plus fréquents. Par exemple la DSN, sur laquelle nous reviendrons,
+est collectée à un rythme mensuel. Certaines données sont mêmes enregistrées
+à des rythmes qui n'ont pas grand chose à envier avec les traces numériques
+du _big data_. Par exemple, les systèmes d'information SIVIC et SIDEP, respectivement
+celui de suivi des entrées à l'hôpital des personnes malades du Covid et celui des
+tests, étaient mis à jour quotidiennement. De même, le système
+d'information de l'assurance maladie est mis à jour en continu en fonction
+des nouveaux événements qui appellent un remboursement. Bien qu'on n'associe
+pas forcément les données administratives avec une collecte en temps réel, il
+ne s'agit ainsi pas d'un critère les discriminant vis à vis des traces numériques.
+
+La différence principale, peut-être, entre les données administratives
+et les données privées est que pour les premières, le champ est connu
+par le fait que celles-ci sont issues d'une collecte d'une population
+bien ciblée. Comme indiqué précédemment, comme la collecte de données
+administrative est souvent assortie de prérogatives légales, la population
+cible est généralement bien identifiée. Dans le monde de la donnée privée,
+comme c'est l'activité qui génère la donnée, le champ dépend de la base
+d'utilisateurs. Selon le type de données, celle-ci peut être plus ou
+moins large. Même parmi les données privées où les populations sont
+les plus larges, la couverture de la population n'est pas parfaite.
+Par exemple,
+les smartphones sont largement
+partagés dans la population. Néanmoins, cette
+technologie a un moindre taux de pénétration dans
+certaines population, notamment les plus
+agées. De plus, les opérateurs ont des parts de marché potentiellement
+hétérogènes (en fonction de critères d'âge ou territoriaux).
+Pour les opérateurs,
+il est difficile d'évaluer le champ de leur clientèle puisque cette
+information nécessite une enquête, et ainsi souffre de taux de réponse
+imparfaits ou de réponses incorrectes.
+Le champ est donc incertain
+puisqu'il n'est pas possible pour les producteurs
+de données privées d'apparier de manière automatique ces données
+avec les données administratives.
+Même s'il n'est pas toujours possible d'apparier des données administratives
+entre elles pour des raisons légales, le fait de fournir des informations
+communes dans différentes sources (état civil voire NIR)
+à un même acteur (l'Etat), facilite l'association entre les sources
+lorsque celle-ci est autorisée.
+
+Les 5V du big-data, initialement listés dans un rapport de MacKinsey,
+ne sont pas l'apanage des données privées.
+Il y a peut-être une différence de degré avec le big-data mais certainement pas
+de nature:
+
+- _Volume_: certaines données administratives représentent des volumes conséquents.
+La DSN représente ainsi plus d'1To de données par an ;
+- _Vélocité_: certaines données, notamment celles de l'assurance maladie, sont à haute fréquence ;
+- _Variété_: l'Etat collecte et exploite des données de natures très différentes ;
+- _Véracité_: les données collectées par l'Etat ne sont pas à l'abri d'erreurs mais ces dernières,
+qu'elles soient volontaires ou non, pouvant être couteuses, les données sont normalement de meilleure
+qualité que celles auto-déclarées sans contrôle ex-post ;
+- _Valeur_: les données collectées par l'Etat sont d'une grande valeur même si elles ne sont pas
+monétisées. La valorisation par l'Etat n'est bien-sûr pas individuelle mais la collecte de données
+qui sont ensuite agrégées permet de créer une statistique publique, qui est un bien public,
+sans valeur de marché mais avec une valeur sociale.
+
+
+Finalement, il y a peu de différence entre les données administratives
+et certaines données privées disponibles sous forme
+structurée. Par exemple, les données générées par les paiements par
+cartes bancaires (données du GIE CB)
+ne sont pas d'une nature très différente de données
+administratives. Comme celles-ci, il s'agit de données
+structurées issues d'un organisme centralisateur (le GIE CB)
+et mises à disposition consolidées pour la statistique publique.
+
+### Une donnée plus sensible
+
+L'aspect exhaustif, sur un certain champ d'unités et d'informations
+de gestion,
+des données
+administratives peut les rendre, au niveau individuel, assez sensibles.
+La question de la confidentialité et de la sensibilité
+des données fournie à l'administration n'est pas nouvelle,
+il s'agit de la raison d'être du secret statistique défini dans
+l'une des lois les plus importantes de la statistique
+publique, à savoir la loi de 1951.
+Les informations fournies dans le cadre de certaines enquêtes peuvent
+être sensibles (informations sur le revenu ou le patrimoine, la santé,
+l'appartenance à certains groupes sociaux...).
+Cependant, l'aspect non exhaustif des enquêtes rend plus difficile
+la réidentification après la phase d'anonymisation.
+Avec les
+données administratives, l'information fournie peut parfois être
+moins précise mais le caractère exhaustif de celles-ci fait
+qu'en combinant plusieurs sources de données la réindentification
+est facilitée.
+
+La question de la confidentialité est donc, au même titre que pour
+les données privées, devenu un enjeu dans le domaine des données
+administratives. Il est à noter que par rapport aux données
+privées cette question ne se pose pas au même niveau.
+Au niveau de la collecte de données, c'est-à-dire de la
+transformation d'une activité en donnée de gestion, là
+où l'utilisateur d'un service numérique bénéficie d'une
+relative liberté sur le choix des données collectées du fait du RGPD,
+ce n'est pas le cas pour l'utilisateur d'un service
+géré par l'Etat. Ce privilège de l'Etat s'appuie sur des
+décrets qui définissent des missions de service public.
+Cependant, au niveau des traitements mis en oeuvre,
+du stockage puis de la diffusion de la donnée,
+des conditions restrictives s'appliquent aussi
+à l'Etat.
+Exemple: SNDS.
+
+
+:::{.callout-note}
+
+## Cadre légal
+
+Cet encadré résume des éléments juridiques listés par @isnard2018.
+
+Les membres du service statistique public (SSP)
+bénéficient d’une disposition importante qui facilite énormément le travail du statisticien.
+Ce sont les seuls organismes à pouvoir mettre en œuvre l’article 7bis de la __loi de 1951__. Cet article leur permet de se faire communiquer, à des fins d’élaboration de statistiques publiques, tout fichier de gestion d’une administration ou d’une personne privée gérant un service public, dès lors que le Conseil national de l’information statistique a été consulté et que la demande émane du ministre chargé de l’économie (en pratique du directeur général de l’Insee). Cette mesure, insérée dans la loi du 7 juin 1951 par la loi du 26 décembre 1986, a permis une exploitation large des données administratives et ainsi un allègement de la charge de réponse aux enquêtes.
+
+L’utilisation de déclarations ou de sources administratives à des fins statistiques est préconisée par le code de bonnes pratiques de la statistique européenne dans le but d’alléger la charge statistique des déclarants. En France, ceci est rendu possible par la loi de 1951 relative à l’obligation, à la coordination et au secret en matière de statistique et a été réaffirmé récemment par la loi pour une République numérique (2016).
+
+:::
+
+
+## Processus de production
+
+Le processus de production de la donnée administrative est différent de
+celui de la donnée traditionnelle. La différence
+principale est la place
+centrale d'une autorité gestionnaire, qui centralise la donnée,
+dans le modèle de production des données administratives [@riviere2018].
+Cet acteur doit être distingué de l'administration qui exploite le
+flux, que ce soit à des fins de gestion ou d'exploitation statistique.
+
+La @tbl-autorites-centralisatrices donne quelques
+exemples de plateformes centralisatrices. Ces dernières ne se contentent
+pas de centraliser ou mettre à disposition la donnée, elles ont aussi
+en charge la normalisation de celle-ci à partir de systèmes d'informations
+divers. La normalisation est un enjeu majeur car elle seule permet
+l'exploitation des données: la collecte étant en général réalisée automatiquement
+via des auto-déclarations, les plateformes centralisatrices récupèrent
+des informations aux contenus hétérogènes.
+
+| Donnée | Autorité centralisatrice |
+|------|------|
+| DSN | Gip-MDS |
+| Données hospitalières | ATIH-10 |
+| SI gestion des eaux | SANDRE12 |
+
+: Exemples d'autorités centralisatrices [@riviere2018] {#tbl-autorites-centralisatrices}
+
+La @fig-dsn résume la place du GIP-MDS dans le processus de
+production de la DSN:
+
+::: {#fig-dsn}
+
+
+Schéma de la place du GIP-MDS dans la production de la DSN. Source: @Humbert2018.
+:::
+
+## Usage de la donnée administrative
+
+L'usage de ces données est de deux nature: l'usage à des fins
+de gestion (la finalité pour laquelle elles sont construites)
+et l'usage à des fins d'analyse (la finalité fortuite).
+Ces peut aller au-delà de l’administration concernée.
+Par exemple,
+la déclaration sociale nominative n'est
+pas utilisée exclusivement par le Ministère du Travail mais aussi
+par la DGFIP, les institutions de prévoyance, les organismes de retraite, l’Acoss, pour leurs propres usages de gestion ; les données de SIRENE servent de référence, de preuve pour les entreprises, elles sont utilisées par les chambres de commerce et d’industrie ou par les greffes des tribunaux de commerce [@riviere2018].
+
+### Un usage accru pour apparier des sources
+
+Certaines sources administratives ont un rôle
+particulier dans le processus de production
+statistique car elle permettent d'identifier
+des unités statistiques dans plusieurs sources.
+Le Répertoire national d’identification des personnes physiques (RNIPP),
+le répertoire Sirene pour les entreprises
+ou encore XXX pour les logements, sont
+des sources qui permettent de relier des unités
+statistiques entre plusieurs sources.
+On parle d'appariements pour désigner ce type
+d'opérations où plusieurs sources de données
+sont associées grâce à une information
+commune. Cela peut se faire sur la base d'une
+information exacte, en général un identifiant
+unique fourni par un des référentiels,
+ou de manière floue à partir d'informations
+non uniques mais qui, combinées, peuvent aider
+à identifier une unité (nom, raison sociale d'une
+entreprise, adresse, etc.).
+
+Ces répertoires administratifs
+sont ainsi des sources
+devenues centrales dans le processus
+de production statistique. Ils permettent
+d'enrichir d'autres sources administratives,
+ou des enquêtes, d'informations administratives.
+Ces dernières peuvent ainsi permettre d'alléger
+certains questionnaires d'enquêtes ou de
+concentrer ceux-ci sur des informations qui
+ne sont pas disponibles dans les sources
+administratives.
+
+:::{.callout-note}
+## Le CSNS
+Un enjeu fort existe autour de la production d'un [code statistique non signifiant](https://www.insee.fr/fr/information/5388962) (CSNS) pour les besoins de mise en œuvre de traitements à finalité de statistique publique impliquant le numéro de sécurité sociale (NIR) ou des traits d’identité, en particulier les appariements au sein du Service statistique publique. La version finale est prévue pour la fin de l'année 2022.
+:::
+
+### Un changement de la place de l'analyste de la donnée
+
+Cette situation change la place du statisticien
+dans le processus de production de la statistique officielle.
+Il convient de transformer en aval les données pour répondre
+aux besoins de l'analyse statistique.
+Cela implique un contrôle qualité ex-post, éventuellement
+un travail de reconstitution et de consolidation.
+
+Cette situation change également la place des chercheurs dans
+le processus de production de la donnée. Comme le statisticien,
+le chercheur n'est plus associé à l'amont de la production de données.
+Cependant celui-ci est, généralement, encore plus en aval que le statisticien public.
+Il reçoit les données généralement consolidées, anonymisées et éventuellement appariées
+entre différentes sources. A cet égard, les données administratives
+scandinaves sont parmi les données les plus utilisées par les chercheurs sur
+le marché du travail car elles constituent une source depuis longtemps
+centralisée et mise à disposition de manière anonymisée.
+
+
+## En conclusion, quels avantages et inconvénients ?
+
+La production et l'usage de données administratives
+se sont généralisés. La numérisation croissante
+de l'économie est amené à confirmer cette
+tendance. L'utilisation par la statistique
+publique de données privées, sous leur forme
+structurée, n'est qu'un prolongement de cette
+dynamique. Ces dernières permettent d'enrichir
+l'information dont dispose l'administration
+avec des informations collectées dans
+le cadre d'activités économiques détachées de l'administration.
+
+Les avantages des données administratives sont multiples.
+En premier lieu, la collecte automatisée de celle-ci,
+associée à un pouvoir public coercitif, permet d'atteindre
+sur un champ d'unités statistiques bien définies (usuellement
+par le biais d'un décret), une forme d'exhaustivité.
+Cette dernière permet de construire des statistiques plus
+fines. Si aujourd'hui il est possible pour des chercheurs
+de zoomer sur le très haut de la distribution de revenu (voir les travaux de Piketty),
+c'est parce que l'aspect exhaustif des données permet
+d'avoir des groupements suffisamment nombreux pour assurer la confidentialité
+de ces groupes.
+
+Une fois payé le coût d'investissement pour automatiser la production statistique
+à partir de données de gestion, les données administratives
+ouvrent la voie à la production à plus haute fréquence
+de statistiques officielles.
+La production annuelle ou infra-annuelle de statistiques
+n'est possible qu'avec un nombre restreint d'enquêtes - dans la plupart des cas,
+les résultats d'enquêtes sont connus avec du retard.
+La publication quotidienne par le service statistique du Ministère de la Santé
+(la DREES) et Santé Publique France d'indicateurs sur la pandémie
+est un bon exemple de l'intérêt de ces données. Ces dernières ont permis
+un suivi très fin par la puissance publique mais aussi par la société civile des
+évolutions de l'épidémie.
+
+Un autre avantage des données administratives est que les informations
+qui sont disponibles dans celles-ci sont certes diverses (nous reviendrons
+sur cela dans le prochain chapitre à travers quelques exemples) mais elles sont,
+sur certains champs, très fiables. Elles souffrent normalement moins de biais
+de réponses même si elles n'en sont pas exemptées (les déclarations erronées
+à l'administration fiscale existent, qu'il s'agisse d'un comportement volontaire
+ou non).
+
+Ces données soulèvent de nouveaux défis pour la statistique publique.
+En premier lieu, elles amènent à redéfinir le rôle du métier
+dans le processus de production de la donnée. Ceci est vrai dans le
+monde de la donnée administrative mais aussi dans le domaine des
+données privées.
+Comme l'utilisateur de données ne contrôle pas le champ ou la
+définition du concept mesuré, c'est le concentrateur, cet acteur
+dont l'activité est spécialisée autour de la collecte et de
+la gestion du flux, qui intervient à cet étape. Il peut ainsi
+être amené à faire évoluer le champ, la définition du phénomène
+mesuré ou encore le formulaire sans
+que l'analyste de données n'ait son mot à dire.
+Pour reprendre l'exemple des données quotidiennes, l'apparition de
+variants à plusieurs reprises a amené à des évolutions, parfois
+sans préavis, du type de donnée collectée, enregistrée.
+Les données déjà collectées n'ayant pas vocation à intégrer
+ces informations qui n'avaient pas de sens au moment de la collecte,
+c'est à l'analyste de données de faire des choix méthodologiques pour
+reconstruire une série cohérente.
+Le statisticien, parce qu'il intervient plus en aval, change donc de rôle.
+Les données administratives n'étant pas construites pour mesurer un
+phénomène qui a du sens pour le statisticien public (ou l'analyste de la
+donnée privée), c'est à lui de reconstruire à partir de l'information
+de gestion la réalité statistique derrière [@salgado-20]. Le travail
+de l'analyse de données va au donc au delà de la simple reconstruction
+de variable, ou du contrôle qualité, il est également nécessaire
+de réfléchir au concept mesuré pour ne pas construire d'"artefact",
+au sens de Bourdieu.
+Cette problématique se pose, de la même manière,
+à la recherche et à l'exploitation
+de données privées.
+
+
+# References
+
+::: {#refs}
+:::
diff --git a/administratives_exemples.qmd b/administratives_exemples.qmd
new file mode 100644
index 0000000..700af1d
--- /dev/null
+++ b/administratives_exemples.qmd
@@ -0,0 +1,145 @@
+---
+title: "Quelques exemples approfondis de données administratives"
+---
+
+# Exemples
+
+4 exemples de nature différente:
+
+- la DSN: base de gestion transmise à l'Insee et la DARES pour la production ;
+- Sirene: répertoire géré par l'Insee, utilisé par d'autres acteurs ;
+- Fidéli: agrégation et mise en cohérence de plusieurs sources ;
+- SNDS: mise en cohérence de données de gestion hospitalières et de l'assurance maladie, enjeu encore plus fort de confidentialité ;
+
+:::{.callout-note}
+## Les autres répertoires de la statistique publique
+
+- Filosofi (Fichier localisé social et fiscal): répertoire de synthèse des sources fiscales ;
+- La Base permanente des équipements (BPE): répertoire d'équipements et services.
+:::
+
+## La DSN
+
+:::{.callout-note}
+## Les DADS et la DSN
+
+Descriptions sur le site de l'Insee de la [Déclaration annuelle de données sociales](https://www.insee.fr/fr/metadonnees/source/serie/s1163) (DADS) et de la [Déclaration sociale nominative](https://www.insee.fr/fr/information/3647025?sommaire=3647035) (DSN).
+:::
+
+La Déclaration sociale nominative est aujourd'hui le mode d'échanges de données sociales des entreprises vers l'administration, et concerne toutes les entreprises du secteur privé. Elle résulte d'un projet de simplification administrative qui s’est étalé sur près de dix ans : la collecte des données est adossée au processus générateur de la collecte des cotisations sociales, c’est-à-dire au processus de paie [@Humbert2018]. En plus de réduire la charge imposée aux entreprise, la DSN garantit une bien meilleure qualité et l'exhaustivité de l’information recueillie.
+
+### Avant la DSN
+
+Les déclarations sociales font partie des tâches administratives historiquement imposées aux entreprises françaises. La déclaration sociale nominative (DSN), née à la fin des années 2000, a été instituée par la loi de simplification du 22 mars 2012, dite loi Warsman. Elle est obligatoire pour toutes les entreprises depuis début 2017.
+
+Les déclarations sociales reposaient auparavant sur des formulaires Cerfa dont le contenu était fixé par les textes fondant la collecte des données utiles aux organismes de protection sociale et à l’administration pour l’exercice de leurs missions. Non seulement les déclarants étaient amenés à fournir plusieurs fois la même information, mais ils devaient surtout fournir une information qui n’était pas naturellement produite par leur système de gestion, ce qui était source d’incohérences et d’erreurs dans les déclarations. La DSN met en œuvre une logique fondamentalement différente : elle s’approche au plus près du fait générateur des rémunérations et cotisations sociales dans le domaine de la protection sociale, la paie. Elle repose sur un modèle unique de cette dernière et un échange de données primaires de gestion entre l’émetteur, qui fait la paie, et tous les organismes et administrations qui ont besoin de ces données sociales pour recouvrer des cotisations et servir des droits. Elle opère donc un déplacement de la charge de traitement des données de l’amont (l’entreprise déclarante) vers l’aval.
+
+La DSN se fait au niveau de chaque établissement avec un principe clé : chaque salarié doit apparaître dans la déclaration. Cette dernière se fait de manière mensuelle et reflète la paie du mois $M-1$, avec certaines possibilités de correction.
+
+::: {#fig-image-nb}
+
+
+Schéma explicatif des changements apportés par la DSN. Source : @Humbert2018.
+:::
+
+### Avantages
+
+La DSN présente de nombreux avantages. Elle constitue une source unique et cohérente entre administrations. Avec la DSN, on est sûr que les employeurs et les salariés sont identifiés de la même façon quel que soit l’organisme destinataire de l’information [@Renne2018].
+
+Elle a aussi permis une forte réduction des charges pour les entreprisess ("dites le nous bien une seule fois"). Par exemple, depuis janvier 2018, les entreprises n’ont plus obligation de fournir leur effectif salarié de fin de période, celui-ci pouvant être recalculé directement par les organismes destinataires à partir des informations individuelles transmises sur les salariés [@Renne2018].
+
+La fréquence mensuelle de transmission des données permet un meilleur suivi des changements infra-annuels. Auparavant, les entreprises transmettaient des données multiples à diverses échéances et à différents organismes, globalisées par établissement.
+
+La DSN n’a pas vocation à servir un besoin spécifique, mais au contraire à couvrir différents usages. Les systèmes d'informations des administrations utilisatrices (Insee, DARES, Pole Emploi, etc.) reçoivent une liste spécifique de données, fixée par arrêté selon leurs missions et se sont synchronisés au fur et à mesure de l’élargissement du périmètre. Depuis 2019, la DSN est le support du prélèvement à la source pour les salariés.
+
+### Challenges
+
+Plusieurs challenges se posent au moment d'utiliser les données issues de la DSN à des fins statistiques. Tout d'abord, les données sont complexes, ce qui implique un certain coût d'entrée. Elles sont aussi volumineuses (environ 1To par an, sans la fonction publique) et leur traitement requiert ainsi des ressources informatiques conséquentes et des outils adaptés. On constate bien un transfert d'une partie de la charge des entreprises vers les systèmes d’information en aval.
+
+Autres challenges liés à l'exploitation statistique:
+
+- parvenir à relier les concepts administratifs à des réalités économiques ;
+- éviter les "artefacts" au sens de Bourdieu.
+
+## Sirene
+
+Le Système national d’identification et du répertoire des entreprises et de leurs établissements (Sirene) est un répertoire administré par l’Insee qui centralise de l'information sur chacun des 32 millions d'établissements (dont 13 millions d'établissements actifs) existant en France. En particulier, il attribue un numéro SIREN aux entreprises, organismes et associations ainsi qu'un numéro SIRET aux établissements de ces entités.
+
+L’utilité du numéro SIRET est multiple. S’il constitue avant tout la preuve juridique de l’existence d’un établissement, il permet également d’effectuer un certain nombre de démarches commerciales et administratives.
+
+Ainsi, il sert à :
+
+- Émettre des factures, mais aussi des documents commerciaux. En effet, il est obligatoire de faire apparaître le numéro sur chacun de ces documents. En outre, si l’entreprise à un site internet, le numéro doit apparaître dans les mentions légales ;
+- Obtenir des informations officielles sur les sociétés. Grâce au SIRET, tout prestataire ou client peut vérifier la fiabilité des données que l’entreprise lui fournit, via une recherche sur internet notamment ;
+- Prouver l’existence légale de la compagnie. Ce numéro permet en effet de l’identifier auprès de ses clients, prestataires, co-contractants et par l’administration fiscale ;
+- Produire des statistiques à partir de la base Sirene et du numéro SIRET. En effet, ces deux éléments donnent accès à des informations capitales que l’INSEE peut réutiliser et analyser.
+
+Pour la statistique publique, Sirene met à disposition des utilisateurs un code APE (pour activité principale exercée) choisi dans la Nomenclature d'activité française (NAF) pour chaque établissement (APET) et pour chaque entreprise (APEN), ainsi que sa localisation, sa catégorie juridique, son effectif salarié et l’historique des mouvements (création, cessation, etc.). Le répertoire SIRENE est aussi la base de référence pour toutes les études et enquêtes statistiques sur les entreprises.
+
+## Fidéli
+
+Le Fichier démographique sur les logements et les individus (Fidéli) est une base annuelle exhaustive de données statistiques sur les logements et de leurs occupants. Fidéli est en réalité un assemblage raisonné de données administratives conçu pour répondre à des finalités en matière de statistiques démographiques.
+
+Cet appariement met en regard:
+
+- des données d'origine fiscale: fichier de la taxe d'habitation, fichier des propriétés bâties, fichiers d'imposition des personnes et fichier des déclarations de revenus. Ces données sont de nature démographique pour les personnes et la structure des ménages, ainsi que sur les revenus perçus au sein des foyers;
+- des données contextuelles pour décrire les adresses: coordonnées, appartenance à des mailles géographiques (IRIS, quartiers de la ville), etc. ;
+- des informations sur les agrégats de revenus déclarés et les montants de prestations sociales reçues.
+
+Fidéli fournit des possibilités d'études poussées sur des sujets extrêmement variés et à des échelles géographiques fines. Des exemples de projets de recherche récents :
+
+- Dynamiques de l’organisation du territoire et des inégalités spatiales en milieux urbains pollués ;
+- Caractérisation spatiale de la vulnérabilité sociale à la hausse des températures en milieu urbain ;
+- Evaluation de l’impact de la majoration de la taxe d’habitation sur les résidences secondaires...
+
+## SNDS
+
+Le Système national des données de santé (SNDS) est un entrepôt de données médico-administratives pseudonymisées couvrant l'ensemble de la population française et contenant l'ensemble des soins présentés au remboursement. Le SNDS peut être vu comme un appariement des grandes bases médico-administratives nationales, notamment :
+
+- les données de l'assurance maladie (base SNIIRAM) ;
+- les données des hôpitaux (base PMSI) ;
+- les causes médicales de décès (base du CépiDC de l'Inserm).
+
+Le SNDS est un dispositif quasiment sans équivalent en Europe ou dans le monde. Il contient un flux annuel de 1,2 milliards de feuilles de soins, 11 millions de séjours hospitaliers et 500 millions d'actes (plus de 3000 variables) qui représentes 450 To de données.
+
+Une des grandes forces du SNDS est qu'il fait le lien entre médecine de ville et médecine hospitalière, ce qui permet de travailler sur les parcours de soin complets des patients pour des études, recherches ou évaluations présentant un caractère d'intérêt public. Les finalités autorisées pour les traitements sont :
+
+- l'information sur la santé et l'offre de soins ;
+- l'évaluation des politiques de santé ;
+- l'évaluation des dépenses de santé ;
+- l'information des professionnels de santé sur leur activité ;
+- la veille et la sécurité sanitaires ;
+- la recherche, les études, l'évaluation et l'innovation en santé.
+
+:::{.callout-note}
+## Mise à disposition des données
+Créé par la Loi du 24 juillet 2019 relative à l’organisation et la transformation du système de santé, le Health Data Hub est un groupement d’intérêt public qui associe 56 parties prenantes, en grande majorité issues de la puissance publique (CNAM, CNRS, Haute Autorité de santé, France Assos Santé, etc.). Le Health Data Hub est en charge de mettre en œuvre les grandes orientations stratégiques relatives au Système National des Données de Santé fixées par l’Etat.
+
+L'offre du Health Data Hub s'articule autour de 4 enjeux stratégiques:
+
+- mettre en valeur le patrimoine des données de santé, en appuyant leur collecte, leur standardisation et leur documentation, en fournissant un hébergement à l’état de l’art sécurisé et un accompagnement dans la mise en conformité RGPD ;
+- faciliter l'usage des données, en proposant un catalogue de données documentées, ainsi qu'une plateforme d'analyse et des outils à l’état de l’art ;
+- protéger les données et les citoyens, en garantissant un très haut niveau de sécurité à travers une démarche éthique de protection des données et de transparence ;
+- innover avec l'ensemble des acteurs, en développant des partenariats académiques et industriels, et en appuyant la dynamique de développement d’outils open source et de l’open data.
+:::
+
+:::{.callout-note}
+## Confidentialité et données de santé
+Pour protéger l'identité des patients et garantir la confidentialité des données, chaque patient est repéré dans l'ensemble du SNDS par un pseudonyme, obtenu par l'application au NIR d'un procédé cryptographique irréversible appelé FOIN. Les données du SNDS sont conservées pour une durée totale de 20 ans, puis archivées pour une durée de 10 ans.
+
+L'accès aux données du SNDS et leur analyse ne peut se faire que dans un cadre d'hébergement très restrictif respectant le référentiel de sécurité du SNDS, afin de garantir la traçabilité des accès et des traitements, la confidentialité des données et leur intégrité.
+:::
+
+### L'EDP-Santé
+
+L'EDP-Santé est un enrichissement des données de l’[échantillon démographique permanent](https://www.insee.fr/fr/metadonnees/source/serie/s1166) (EDP) avec des informations issues du SNDS sur les années 2008-2022. Ce traitement a fait l’objet d’une autorisation de la CNIL et s’inscrit dans le cadre du règlement général sur la protection des données (RGPD), ainsi que la loi relative à l’informatique, aux fichiers et aux libertés (n° 78-17 du 6 janvier 1978 modifiée). Constitué dans le cadre de la stratégie nationale de santé 2018-2022, les données ne sont exploitables que par les personnes habilitées au sein de la DREES et sont conservées pour une période de 5 ans.
+
+L'EDP-Santé contient :
+
+- les données issues de l’EDP concernent l’état civil, la situation familiale, la vie professionnelle (diplôme, situation professionnelle, données relatives à l’activité salariée) et des informations d’ordre économique (revenus, situation fiscale) ;
+- les données issues du SNDS sur les recours aux soins et les données issues des certificats de décès.
+
+# References
+
+::: {#refs}
+:::
diff --git a/geolocalized_data.qmd b/geolocalized_data.qmd
new file mode 100644
index 0000000..5ce5800
--- /dev/null
+++ b/geolocalized_data.qmd
@@ -0,0 +1,163 @@
+---
+title: "Données géolocalisées"
+bibliography: references.bib
+---
+
+### Introduction
+
+Disposer de données géolocalisées pour produire de la statistique publique est un besoin qui se fait de plus en plus fort. Pour cause, un intérêt croissant est accordé aux caractéristiques spatiales des phénomènes que la statistique publique a pour rôle de décrire. Le comité d'experts des Nations Unies sur la gestion de l'information géospatiale mondiale (`UN-GGIM`) a d'ailleurs *reconnu l’importance cruciale d’intégrer les informations géospatiales aux statistiques et aux données socio-économiques et le développement d’une infrastructure statistique géospatiale*.
+
+La production et la diffusion accrue de données géolocalisées dépasse le cadre de la statistique publique.
+La généralisation
+de traces numériques géolocalisées (données mobile, GPS, localisation d'adresses IP...) a entraîné une
+multiplication des acteurs valorisant des données spatiales. Certains acteurs de l'écosystème
+de la donnée sont spécialisés dans la collecte ou la valorisation de sources géolocalisées
+collectées par d'autres.
+
+Un premier apport fondamental des données géolocalisées
+est qu'elles permettent de calculer des indicateurs avec
+une granularité spatiale plus fine que les découpages administratifs ou historiques classiques.
+Cette approche permet d'éclairer des phénomènes socio-économiques locaux comme les problématiques
+de mixité [@galiana2020segregation].
+L'Insee met à disposition en _open-data_ des données très fines sur une grande variété
+de facteur. Les sites officiels [geoportail](https://www.geoportail.gouv.fr/) et
+[statistiques-locales.insee.fr](https://statistiques-locales.insee.fr) ou encore
+les sites faits par des tiers comme [celui d'Etienne Côme](https://www.comeetie.fr/galerie/francepixels/)
+ou [hubblo](https://www.hubblo.fr/) permettent d'explorer la richesse des sources fines
+mises à disposition.
+Pour désigner les sources les plus fines, on parle de données carroyées, publiées sur des carreaux pouvant aller de 200 mètres à plusieurs kilomètres de côté (voir @fig-carroyees). Une telle granularité permet de capter certains phénomènes démographiques ou socio-économiques qui ne sont pas détectables au niveau de l'IRIS ou de la commune[^1].
+
+[^1]: Le [projet `gridviz`](https://github.com/eurostat/gridviz) porté par `Eurostat` vise à proposer un
+outil facilitant la construction de mosaiques agrégées à partir de données spatiales.
+
+::: {#fig-carroyees}
+{ width=70% }
+
+Carte des densités de population sur des carreaux de largeur d'un kilomètre à Lyon et ses alentours en 2017 (calculées à partir de Filosofi). Source : [géoportail](https://www.geoportail.gouv.fr/donnees/densite-de-population).
+:::
+
+### Les données publiques géolocalisées
+
+Plusieurs grands répertoires de données de l'Insee sont ainsi géolocalisés aujourd'hui :
+
+- `Filosofi` (pour __Fichier localisé social et fiscal__) est un fichier de synthèse de sources fiscales (déclarations de revenus des ménages, taxe d'habitation, fichier d'imposition des personnes) enrichi par les données sur les prestations sociales fournies par les organismes sociaux, pour un peu plus de 26 millions de ménages fiscaux en France. Les résidences des ménages y sont géolocalisées ;
+- `Fidéli` (pour Fichier démographique sur les logements et les individus) peut se définir comme une base annuelle exhaustive de données statistiques sur les logements - qui sont géolocalisés - et de leurs occupants ;
+- La `Base Permanente des Equipements (BPE)` est une source qui fournit le niveau de services rendus à la population sur un territoire, en répertoriant un large éventail d'équipements et de services accessibles au public sur l'ensemble de la France au 1er janvier de chaque année. La plupart des types d'équipement (commerce, services, santé, etc.) sont géolocalisés dans la base accessible en *open data* ;
+- Les établissements du répertoire `Sirene` sont géolocalisés (hors Mayotte) et ces données sont mises à disposition des utilisateurs en *open data*. La géolocalisation des établissements actifs de 200 salariés ou plus a été systématiquement vérifiée par des gestionnaires de reprise de géolocalisation, ainsi que celle des établissements de 20 à 199 salariés pour lesquels la géolocalisation automatique est incertaine ;
+- Le `Recensement de la Population` conduit aujourd'hui à une publication de statistiques à la maille des IRIS. Une première diffusion de données carroyées à partir du recensement suite à une phase de géolocalisation est prévue pour 2024.
+
+En général, la géolocalisation est réalisée par une combinaison d'un appariement avec un référentiel d’adresses géolocalisées construit à partir du `Répertoire d’Immeubles Localisés (RIL)` pour les besoins du Recensement de la Population dans les communes de plus de 10 000 habitants, et de la géolocalisation des parcelles cadastrales. Ce sont ainsi ces deux répertoires administratifs qui permettent de géolocaliser de nombreuses autres sources. Une reprise manuelle peut être faite dans les cas où la géolocalisation n'est pas possible ou s'est faite avec un faible niveau de confiance.
+
+L'appariement entre les grands répertoires géolocalisés et d'autres sources peut donner naissance à des bases de données extrêmement riches et ainsi à des études de phénomènes socio-économiques à des échelles spatiales très faibles. Par exemple, @andre-21 constituent une base exhaustive rassemblant les caractéristiques des ménages et la description détaillée de leur patrimoine immobilier, à partir de différentes sources administratives (le cadastre, le fichier Fidéli, les revenus fiscaux et sociaux, les transactions immobilières et des données sur les sociétés civiles immobilières). Cette base permet d'analyser finement la concentration de la propriété immobilière en fonction du niveau de vie ou encore le profil redistributif de la taxe foncière (part de cette taxe dans le revenu disponible en fonction de ce dernier).
+
+:::{.callout-note}
+Les données géolocalisées sont relativement récentes à l'Insee et ne sont pas encore exploitées à leur plein potentiel. Preuve de la reconnaissance de ce dernier, un *Manuel d'analyse spatiale* [@feuillet-18] a été publié pour former les agents de l'Institut (entre autres) à la fois sur la théorie et l'application pratique avec `R` de méthodes d'analyse spatiale.
+:::
+
+:::{.callout-note}
+Une attention particulière doit être portée lors de la publication d'informations à un niveau fin à la protection de la vie privée et au respect du secret statistique. En effet, les réglementations européennes et nationales interdisent la diffusion de données permettant la réidentification de l'identité de ménages (ou d’entreprises) concernés. Or c'est un risque qui devient important dès lors que l'on publie des indicateurs à une échelle territoriale fine.
+
+Pour garantir la confidentialité au moment de la publication d'indicateurs, une possibilité est de contrôler les cellules au sein desquelles les calculs ont été faits pour identifier des cellules à risque, typiquement des cellules avec une population faible. Ces cellules à risque peuvent être fusionnées avec d'autres cellules ou subir d'autres traitements spécifiques (imputation de l'indicateur d'intérêt par exemple) pour diminuer le risque de réidentification [@feuillet-18].
+
+Une autre approche consiste à travailler en amont du calcul des indicateurs à publier. On associe à chaque observation un niveau de risque qui représente sa probabilité d'être réidentifié et qui dépend des caractéristiques des observations voisines. Les observations présentant un risque élevé peuvent ensuite subir un traitement spécifique, comme la permutation de leurs caractéristiques avec d'autres observations (méthodes de *swapping*).
+:::
+
+De nombreux acteurs privés collectent des données géolocalisées, en général en grande quantité, qui ont un fort potentiel pour la statistique publique. Dans le cadre de partenariats, l'Insee peut obtenir des accès temporaires (parfois indirects) à de telles données.
+
+### Données de téléphonie mobile
+
+Les données de téléphonie mobile en sont un bon exemple. On distingue en général 2 types de données de téléphonie mobile :
+
+- Les *Call Detail Records* (CDR) qui sont générés lors des communications actives d'un utilisateur à travers son téléphone mobile (appel, envoi de SMS, etc.);
+- Les données de signalisation passive qui sont collectées par les opérateurs principalement à des fins d'optimisation et de surveillance de leurs réseaux. Ces données de signalisation sont caractérisées par une fréquence temporelle bien supérieure à celle des données CDR.
+
+Ces deux types de données contiennent la même information spatiale : chaque observation contient des informations sur l'antenne radio avec laquelle le téléphone est en communication. Les données CDR permettent de produire des statistiques intéressantes sur les populations présentes et les déplacements de la population. Par exemple, @galiana-20 observe à partir de comptages issus des données CDR que la répartition de la population sur le territoire s’est significativement modifiée à la mise en place du confinement en mars 2020, au début de la pandémie de Covid-19 (voir @fig-confinement-deconfinement). Pendant le confinement, la population a davantage passé la nuit dans son département de résidence qu’avant le confinement. Au moment du déconfinement, les mêmes données de CDR indiquent que les mouvements de population sur le territoire ont repris partiellement, le sûrcroit de population se trouvant dans son département de résidence diminuant de moitié par rapport à la période de confinement.
+
+::: {#fig-confinement-deconfinement}
+{ width=80% }
+
+Évolution du nombre de personnes présentes dans les départementents métropolitains lors du confinement par rapport à la période antérieure (à gauche) et lors du déconfinement par rapport au confinement (à droite).
+:::
+
+Les données de signalisation permettent d'aller plus loin, par exemple en estimant des populations présentes avec une fréquence temporelle élevée [@ricciato-20]. Pour un maillage territorial donné, par exemple des carreaux de 200 mètres de côté, les opérateurs téléphoniques peuvent modéliser leur réseau de manière à estimer la probabilité qu'un téléphone se trouvant au sein d'un carreau $i$ soit détecté dans une cellule (aire couverte par une antenne) $j$. Ceci permet d'avoir une estimation du lieu où se trouvent tous les téléphones en lien avec le réseau quasiment en continu. En repondérant les nombres de téléphones estimés dans chaque tuile en fonction du nombre du nombre de téléphones considérés comme résidant dans chaque tuile et la population effectivement résidente de chaque tuile (obtenue grâce aux données fiscales géolocalisées), il est possible d'avoir une estimation en temps réelle de la population présente pour le maillage territorial choisi.
+
+La @fig-france-pops et la @fig-paris-pops illustrent ces estimations des variations de densité de population présente, heure par heure dans une même journée et jour par jour dans une même semaine, respectivement en France métropolitaine et à Paris et ses alentours. Même s'il faut prendre ces résultats avec précaution au vu de la simplicité de la méthodologie adoptée, on constate des tendances intéressantes :
+
+- On peut observer les variations de populations présentes intra-journalières dues aux mouvements des habitants des banlieues d'agglomérations qui travaillent en centre-ville. La population présente a tendance à être élevée dans la périphérie des villes la nuit, où elle diminue à partir de 9 heures du matin et jusqu'au soir au profit des centres-villes ;
+- Lorsqu'on regarde Paris et ses alentours avec une granularité spatiale plus fine, les variations de populations présentes intra-journalières discriminent les zones avec une forte activité touristique, économique et de loisirs des zones résidentielles ;
+- Les variations de populations présentes à l'intérieur de la semaine montrent que les villes (et en particulier Paris) se vident en partie pendant les week-ends, au moment où les régions côtières et montagneuses ont tendance à accueillir des visiteurs. À Paris, certaines zones voient leur population présente augmenter la nuit lors des week-ends, ce qui suggère une activité nocturne ou des nuitées touristiques.
+
+::: {#fig-france-pops}
+
+  +
+  +
+
+
+Estimation des variations de densité de population présente (nombre de personnes présentes par kilomètre carré), heure par heure dans une même journée (à gauche) et jour par jour dans une même semaine en France métropolitaine.
+:::
+
+::: {#fig-paris-pops}
+
+  +
+  +
+
+
+Estimation des variations de densité de population présente (nombre de personnes présentes par kilomètre carré), heure par heure dans une même journée (à gauche) et jour par jour dans une même semaine à Paris et ses environs.
+:::
+
+:::{.callout-note}
+L'utilisation de données de téléphonie mobile pour la production de statistiques publiques pose des questions :
+
+- **Questions sur la qualité** : les données disponibles ne concernent qu'un sous-champ de la population, par exemple les clients d'un opérateur en particulier, ce qui engendre en général des biais de sélection. Dès lors, il est nécessaire d'évaluer la représentativité de ce sous-champ par rapport à la population générale pour s'assurer de la validité (partielle) des résultats;
+- **Questions sur la perennité** : les données viennent de tiers privés et l'Insee n'a donc aucun contrôle sur des possibles changements de format ou de méthode de collection des données. Dans ce contexte, il n'y a pas de garantie que les indicateurs restent comparables au cours du temps.
+- **Questions d'éthique** : avant d'utiliser ces données personnelles, il faut s'assurer que l'usage qui en est fait est proportionné et que la production statistique qui en résulte a une valeur ajoutée pour la population.
+- **Questions légales** : les aspects légaux autour des données personnelles sont aussi à prendre en compte, en lien d'ailleurs avec les questions d'éthique et les questions sur la pérennité. Aujourd'hui la législation européenne et son application dans la loi française ne sont pas favorables à l'utilisation de données téléphoniques de signalisation pour la statistique publique. Même si elles venaient à le devenir, il n'y a aucune garantie qu'on ne revienne pas quelques années après à la situation actuelle.
+:::
+
+### Données de réseaux sociaux
+
+Les réseaux sociaux sont une autre source privée d'informations parfois géolocalisées. Les données issues de réseaux sociaux ont potentiellement des applications intéressantes pour la statistique publique :
+
+ - En complément des données de téléphonie mobile, elles peuvent participer à l'estimation de populations présentes en temps réel, avec un apport particulier pour le tourisme. Pour cause, les touristes sont souvent absents des données de téléphonie mobile et ont tendance à être très actifs sur les réseaux sociaux ;
+ - Elles peuvent servir à estimer le niveau de bien-être de la population à partir de méthodes d'analyse de sentiment ;
+ - Elles peuvent servir à analyser l'opinion publique à propos de sujets ou d'évènements particulier. Par exemple, `CBS` (INS des Pays-Bas) utilise un indicateur de sentiment calculé à partir de données issues de réseaux sociaux pour complémenter un indicateur de confiance des consommateurs lui calculé à partir de données d'enquête [@brakel-17].
+
+Aujourd'hui plusieurs réseaux sociaux fournissent des interfaces pour accéder à leurs données. Par exemple, `Twitter` propose une API qui permet de récupérer des tweets à partir de requêtes simples à construire. Il est ainsi possible de récupérer tous les tweets contenant un ou plusieurs mots clés, en excluant les retweets et les tweets sans information de géolocalisation.
+Tous les _tweets_ ne contiennent pas d'information sur la position de l'appareil utilisé au moment de l'envoi : il faut que l'utilisateur ait activé cette fonctionnalité. On peut avec de telles requêtes de connaître la position et l'heure exactes de l'envoi des tweets - géolocalisés - portant sur un sujet.
+
+:::{.callout-note}
+Des forts biais de sélection peuvent exister lorsque l'on exploite les données de réseaux sociaux.
+Dans le cas de `Twitter` par exemple, les personnes qui tweetent, et a fortiori les personnes qui tweetent en partageant leur localisation ne constituent a priori pas un échantillon représentatif de la population générale. C'est encore davantage le cas sur un sujet en particulier.
+A priori, les gens qui communiquent sur ce sujet sont plus souvent concernés directement que la population générale.
+
+Pour publier des indicateurs relevant de la statistique publique et calculés entièrement à partir de données de réseaux sociaux, il est nécessaire d'adopter un cadre de contrôle qualité très strict, en commençant par dresser une liste exhaustive des différents biais possibles [@olteanu-19].
+:::
+
+### Données de suivi de navires ou de vols
+
+Les données `AIS` sont des données de localisation de navires. AIS fait référence au système d'identification automatique utilisé par les navires partout dans le monde, utilisé à l'origine pour les échanges d'information entre navires équipés de terminaux AIS. Les données AIS sont générées et transmises de manière automatique, toutes les 2 à 10 secondes en fonction de la position et de la vitesse du navire. Lorsque ce dernier est à l'arrêt, des informations sont transmises toutes les 6 minutes. Les données transmises incluent :
+
+- Des données sur les caractéristiques des navires : identifiant, nom, type de vaisseau, taille, nationalité, etc.
+- Des données géospatiales : localisation, vitesse, etc.
+- Des données techniques supplémentaires : source de la transmission, date et heure, etc.
+
+Des applications potentielles impliquant l'utilisation des données AIS existent pour la statistique publique et pourraient être explorées par l'Insee :
+
+- Prévisions à court-terme (*nowcasting*) sur le commerce domestique et/ou international : les données AIS sont disponibles quasiment en temps réel, ce qui les rend adaptées pour faire des prévisions à court-terme. Par exemple, l'ONS (INS du Royaume-Uni) a étudie en continu l'activité maritime de 10 grands ports britanniques, en se concentrant sur deux indicateurs : le *temps passé au port* et le *trafic total*. Ces indicateurs offrent une mesure rapide du niveau de l'activité de transport maritime, qui est liée au commerce de marchandises. Ils sont à prendre en compte lors de l'élaboration d'indicateurs conjoncturels.
+- De manière similaire, le Fond Monétaire International a estimé des volumes d'échanges commerciaux à partir de données AIS et a constaté une forte corrélation avec des statistiques officielles sur le commerce, au niveau de pays individuels aussi bien qu'au niveau mondial [@cerdeiro-20].
+- Estimation des émissions de gaz à effet de serre liés au transport maritime : en appariant les données AIS avec des données relatives aux types de moteurs et à la consommation de carburant, il est possible de calculer les émissions de chaque navire. Utiliser les données AIS permet de discriminer les transports nationaux des transports internationaux [@imo-20].
+
+:::{.callout-note}
+Des défis se posent au moment d'utiliser les données AIS :
+
+- Des problèmes de qualité existent et demandent des pré-traitements spécifiques :
+ - Données corrompues à cause d'un équipement défectueux ou de conflits lors de la transmission de signaux ;
+ - La couverture des émetteurs-récepteurs terrestres est limitée aux zones proches du rivage. En haute mer, des récepteurs satellites sont utilisés pour empêcher les problèmes de transmissions mais ces derniers peuvent tout de même se produire ;
+- Les données brutes sont complexes et demandent de manière générale des pré-traitements lourds pour être utilisables. Des fournisseurs de données privées collectent, nettoient et vendent les données traitées (mais à des prix élevés). Des données pré-traitées sont aussi mises à disposition des Instituts statistiques nationaux sur la *UN Global Platform* ;
+- La taille des données constitue un fort enjeu. En effet, 310 milliards de transmissions sont effectuées chaque année. Une infrastructure adaptée est indispensable pour pouvoir traiter les données brutes ;
+:::
+
+### References
+
+::: {#refs}
+:::
diff --git a/gif/france_day_densities_cropped.gif b/gif/france_day_densities_cropped.gif
new file mode 100644
index 0000000..6adf503
Binary files /dev/null and b/gif/france_day_densities_cropped.gif differ
diff --git a/gif/france_week_densities_cropped.gif b/gif/france_week_densities_cropped.gif
new file mode 100644
index 0000000..e46d002
Binary files /dev/null and b/gif/france_week_densities_cropped.gif differ
diff --git a/gif/paris_day_densities.gif b/gif/paris_day_densities.gif
new file mode 100644
index 0000000..3cd5987
Binary files /dev/null and b/gif/paris_day_densities.gif differ
diff --git a/gif/paris_week_densities.gif b/gif/paris_week_densities.gif
new file mode 100644
index 0000000..89bb6d8
Binary files /dev/null and b/gif/paris_week_densities.gif differ
diff --git a/images.qmd b/images.qmd
new file mode 100644
index 0000000..c803a14
--- /dev/null
+++ b/images.qmd
@@ -0,0 +1,356 @@
+---
+title: "Images"
+---
+
+# Introduction
+
+Les images sont des données qui sont utilisées depuis longtemps de manière automatique.
+Une image pour un ordinateur est représentée par un tableau en 2 ou 3 dimensions (images en nuances de gris et images en couleur respectivement).
+En 2 dimensions, l'image a ainsi une longueur $L$ et une largeur $W$ :
+elle est constituée de $L \times W$ pixels, chacun associé à une valeur entière comprise entre 0 et 255
+(ou parfois à une valeur décimale comprise entre 0 et 1),
+comme illustré en @fig-image-nb.
+
+::: {#fig-image-nb}
+{ width=50% }
+
+Représentation du logo de `Python` en nuances de gris avec une faible résolution.
+La valeur de chaque pixel (entier allant de 0 pour un pixel complètement noir à 255 pour un pixel complètement blanc) figure à l'emplacement de ce dernier.
+:::
+
+Une image en couleur est constituée de 3 canaux (RGB pour *Red*, *Green* et *Blue*).
+Chacun des $L \times W$ pixels de l'image est ainsi associé à 3 valeurs entières comprises entre 0 et 225 (ou à 3 valeurs décimales comprises entre 0 et 1), comme illustré en @fig-image-couleur.
+
+::: {#fig-image-couleur layout="[[-26,14,-26], [-8,16,-1,16,-1,16,-8]]"}
+
+
+
+
+
+
+
+
+Représentation du logo de `Python` en couleurs. L'image du haut correspond
+à la superposition des trois canaux représentés sur la rangée inférieure.
+:::
+
+Le domaine de la vision par ordinateur (*computer vision*) a vu le jour dans les années 1960
+avec le développement des premiers algorithmes cherchant à extraire de l'information d'images.
+Par exemple, @sobel-73 introduit la méthode suivante pour faire de la détection de contours sur une image $A$.
+
+On calcule
+
+$$
+G_x = \begin{bmatrix}
++1 & 0 & -1\\
++2 & 0 & -2\\
++1 & 0 & -1
+\end{bmatrix} \star A \quad \text{et} \quad G_y = \begin{bmatrix}
++1 & +2 & +1\\
+0 & 0 & 0\\
+-1 & -2 & -1
+\end{bmatrix} \star A
+$$
+
+où $\star$ est l'opérateur de convolution 2-dimensionnel en traitement du signal (illustré en @fig-convol).
+
+Alors l'image $G = \sqrt{G_x^2 + G_y^2}$ fournit une représentation des contours de l'image $A$. Une illustration de l'application de cette méthode est donnée en @fig-sobel.
+
+::: {#fig-sobel layout="[-3,10,-1,10,-3]"}
+
+
+
+
+L'image de droite est obtenue par application sur l'image de gauche de la méthode de détection de contours introduite par @sobel-73. Source : [Wikipedia](https://en.wikipedia.org/wiki/Sobel_operator).
+:::
+
+::: {#fig-convol}
+{ width=60% }
+
+Illustration de l'opérateur de convolution 2-dimensionnel $\star$. Le noyau (matrice en bleu sur le dessin) est multiplié par -1 et *glisse* sur la matrice de gauche. Une multiplication élément par élément est faite sur chaque sous-matrice de la taille du noyau. Pour chacune de ces multiplication, les coefficients sont ensuite sommés pour donner une valeur de sortie unique. Par exemple ici, la valeur du pixel en vert correspond au calcul $3 = 1*(-1) + 1*1 + 1*2 + 1*1$.
+:::
+
+# La révolution du Deep Learning
+
+Dans les dernières années, l'apprentissage profond a permis une véritable révolution dans le domaine de la vision par ordinateur [@voulodimos-18].
+Les réseaux de neurone ont permis l'introduction de
+modèles complexes qui parviennent à apprendre et à représenter des données
+sur plusieurs niveaux d'abstraction,
+à l'image de la manière dont le cerveau perçoit et comprend les informations multi-modales.
+
+Ainsi, les performance *state-of-the-art* ont été largement améliorées pour une multitude de tâches différentes :
+classification d'image, segmentation sémantique, reconnaissance faciale et détection d'objets...
+Par exemple, dans le domaine de la robotique ou de la voiture autonome, ces modèles ont
+changé la donne en permettant que certaines opérations d'analyse et de décisions soient néanmoins
+applicables dans une grande diversité de scénarios.
+
+## Réseaux de neurone convolutifs
+
+Une architecture de modèles a joué un rôle particulièrement important dans cette révolution : les __réseaux de neurones convolutifs__ [voir @lecun-89 pour un des articles fondateurs].
+Ces réseaux de neurones sont constitués d'un enchaînement de couches convolutives, chacune composée de trois étapes :
+
+- __Une étape de *convolution*__ utilisant l'opérateur $\star$ décrit ci-dessus qui transforme un [tenseur](https://fr.wikipedia.org/wiki/Tenseur_(math%C3%A9matiques))
+3-dimensionnel de taille $(H, W, C)$ en entrée en un tenseur de taille $(H', W', C')$ ou $H'$, $W'$ et $C'$ dépendent de la taille du noyau de convolution choisi ;
+- Une __étape de *détection*__ où une fonction non-linéaire est appliquée au tenseur obtenu en sortie de l'étape de convolution ;
+- Une __étape de *pooling*__ où chaque canal du tenseur en entrée voit sa hauteur et largeur réduite à l'aide une fonction qui remplace chaque valeur par une statistique impliquant les valeurs des pixels voisins (fréquemment, la valeur maximale dans un voisinage rectangulaire : c'est l'opération de *max pooling*).
+
+La succession de ces opérations est résumée dans la @fig-nn-convol
+
+::: {#fig-nn-convol}
+
+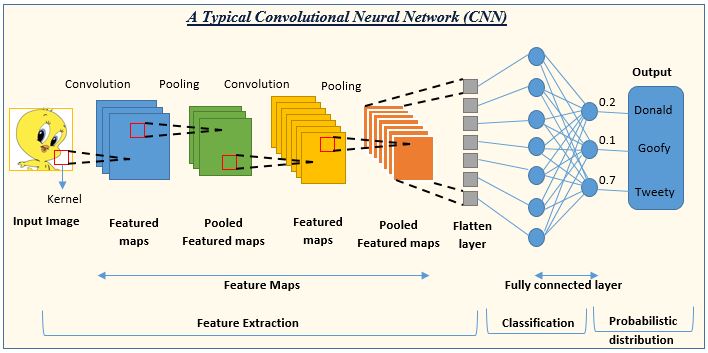
+
+Illustration d'une succession de séquences d'un réseau convolutionnel.
+Emprunté à https://www.analyticsvidhya.com/blog/2022/01/convolutional-neural-network-an-overview/
+
+:::
+
+Les tenseurs obtenus en sortie des couches convolutives sont appelés *activation maps* ou *feature maps*.
+Chaque *feature map* peut s'interpréter comme une carte qui indique les endroits où on peut trouver une *feature* particulière (par exemple un bord, une texture, une partie d'un objet, etc.) au sein de l'image.
+Les _features_ pertinentes (c'est-à-dire les coefficients des filtres de convolution utilisés)
+sont apprises par le réseau de neurones au cours de la phase d'entraînement.
+On peut voir ces _features_ comme des structures latentes qui combinées ensemble génèrent un objet sur
+l'image
+finale.
+
+
+Les réseaux de neurones convolutifs présentent plusieurs caractéristiques essentielles pour des tâches de vision par ordinateur, qui expliquent en partie leur succès : une invariance (relative) à la translation, la rotation et à l'échelle.
+Ces caractéristiques permettent aux modèles d'abstraire l'identité d'un objet de détails spécifiques aux images données en entrée tels que la position et l'orientation de cet objet par rapport à la caméra.
+
+## Segmentation sémantique
+
+La segmentation sémantique est une tâche de vision par ordinateur qui consiste à associer une étiquette ou une catégorie à chaque pixel d'une image (illustration en @fig-segmentation). Plusieurs architectures de réseaux de neurones convolutifs entraînées sur des gros jeux d'entraînement obtiennent des performances très élevées sur des jeux de données d'évaluation de référence, comme l'architecture `DeepLabV3` [@chen-17]. Les principaux frameworks de Deep Learning fournissent des implémentations de modèles de segmentation sémantique (avec ou sans coefficients pré-entraînés) : c'est le cas du package `Python` [`torchvision`](https://pytorch.org/vision/) par exemple qui propose une implémentation des modèles `DeepLabV3`, `FCN` et `LRASPP`.
+
+::: {#fig-segmentation layout-ncol=2}
+
+
+
+
+Segmentation sémantique effectuée sur une photo de chat (partie gauche de la Figure). Sur le masque de segmentation (partie droite de la Figure), les pixels verts sont associés à la classe *chat* tandis que les pixels roses sont associés à la classe *arrière-plan*. Source : [Hugging Face](https://huggingface.co/tasks/image-segmentation).
+:::
+
+::: {#fig-segmentation}
+
+
+
+
+Un autre exemple de segmentation sémantique, issu de ce [blog](https://nanonets.com/blog/semantic-image-segmentation-2020/)
+:::
+
+
+# Application à la statistique publique
+
+La statistique publique, et plus largement l'administration,
+peut désirer tirer parti des méthodes de vision par ordinateur
+de plusieurs manières.
+La suite de ce chapitre va développer quelques cas d'usages,
+non exhaustifs, des données satellites pour la statistique
+publique. Les cas d'usage sont très nombreux et ne seront
+pas tous évoqués. Par exemple, pour en savoir
+plus sur la production des données LIDAR de l'IGN,
+il est recommandé de lire [cette page](https://geoservices.ign.fr/lidarhd).
+
+
+## Utilisation de données d'observation satellitaire
+
+### Nature de la donnée
+
+Dans le domaine des données d'*Earth Observation*,
+qui regroupent en fait différentes sources de données (radars, [orthophotographies](http://geoconfluences.ens-lyon.fr/glossaire/orthophotographie)...), les données photographiques
+issues de satellites ont une place de choix.
+Celles-ci
+permettent d'observer les territoires, que ce soit leur topologie
+ou leur usage
+et potentiellement d'en tirer des enseignements à diffuser sous la forme de statistiques publiques.
+Par exemple, l'utilisation de données satellitaires peut permettre d'améliorer la granularité spatiale et temporelles de statistiques publiées aujourd'hui sur la production agricole (part du territoire cultivé, nature des cultures...).
+
+De manière générale, ces données ont beaucoup de potentiel lorsqu'elles sont utilisées en combinaison avec d'autres sources de données lorsqu'il s'agit de pallier des insuffisances ou des manques concernant les données traditionnellement utilisées pour la statistique publique. Par exemple, @steele-17 combinent données de satellites et données de téléphonie mobile pour estimer des taux de pauvreté.
+En France, les départements et régions d'outre-mer sont particulièrement concernés.
+Les données satellites permettraient d'y combler des imperfections des données administratives.
+Par exemple, les parcelles cadastrales y sont parfois mal identifiées ou rarement mises à jour. Les données satellitaires peuvent être utilisées pour fiabiliser cette information.
+
+:::{.callout-note}
+Les données d'*Earth Observation* présentent des difficultés d'utilisation non-négligeables dans un contexte de production statistique :
+
+- Il faut au moment de la production de la statistique désirée s'assurer que l'on parvient à des résultats statistiquement robustes ;
+- Produire des statistiques de manière récurrente à partir d'une source de données demande d'avoir du recul sur le fonctionnement de la chaîne de traitement en production. Comme les données d'*Earth Observation* ne sont aujourd'hui utilisées que par peu d'instituts statistiques, il est difficile d'avoir un tel recul sans soi-même avoir une chaîne de traitement qui tourne depuis plusieurs années ;
+- Pour de nombreuses applications, on souhaite utiliser des images avec une résolution élevée mais aussi exploiter la haute fréquence temporelle de passage de certains satellites. Dans un tel cadre les données d'*Earth Observation* ont souvent un volume très important. Entraîner des modèles pertinents (les modèles de _Deep Learning_ *state-of-the-art* sont complexes) demande d'avoir des ressources informatiques adaptées à disposition ;
+- Selon les besoins, la résolution disponible peut ne pas correspondre aux besoins de la statistique.
+:::
+
+### Fournisseurs de données
+
+Des acteurs publient des données satellitaires en *open data* :
+
+- La `NASA` à travers son programme historique [`Landsat`](https://landsat.gsfc.nasa.gov/data/). Les dernières générations des satellites Landsat recueillent des images dans une dizaine de bandes spectrales (bandes visibles mais aussi bandes infrarouges) avec une résolution spatiale de 30 mètres (pour les bandes visibles) ;
+- L'`Agence spatiale européenne (ESA)` a lancé le programme [`Sentinel-2`](https://sentinel.esa.int/web/sentinel/sentinel-data-access) en 2015. Les images des satellites `Sentinel-2` sont aussi disponibles en *open data*, sur 12 bandes avec une résolution spatiale de 10 mètres, plus fine que celle des images de `Landsat`. La périodicité de la couverture des satellites `Sentinel-2` est relativement faible : ces derniers repassent au-dessus des mêmes zones tous les cinq jours.
+
+Des entreprises privées collectent aussi des images avec leurs propres satellites,
+parfois avec des meilleures résolutions que les images disponibles en libre accès,
+ce qui peut être nécessaire en fonction du cas d'usage envisagé.
+De manière générale,
+il y a toutefois un arbitrage à faire entre le détail local des mesures
+(résolution radiométrique, nombre de bandes spectrales) et la résolution spatiale des images.
+La richesse des images issues de satellites réside plutôt dans la première dimensions,
+alors que les orthophotographies par exemple sont à privilégier si on désire une plus haute résolution spatiale.
+
+### Pipeline
+
+Le traitement d'images de satellites se divise de manière classique en trois parties [@plan-sat] :
+
+- d'abord vient le __pré-traitement__ des données, qui inclut le stockage, le *data managment*, le contrôle de la qualité des données, l'inclusion d'autres sources et l'identification d'outils appropriés pour l'analyse.
+- Ce pré-traitement est suivi par une __phase d'analyse__, où l'on définit les indicateurs à calculer, les données à utiliser et où l'on applique la méthode analytique choisie.
+- Enfin, au cours de la __phase d'évaluation__, on collecte et on interprète les résultats de l'analyse.
+
+Des méthodes historiques existent pour analyser des images de satellites (pour *in fine* produire des statistiques).
+Par exemple, l'utilisation de modèle physiques
+pour prédire la valeur d'une variable d'intérêt à partir de l'observation empirique de certaine bandes,
+ou encore de méthodes d'analyse d'images traditionnelles où des informations spatiales,
+relatives à des motifs, à des textures, etc. sert à segmenter l'image sous supervision humaine (OBIA).
+Récemment, le Machine Learning (et en particulier le Deep Learning) a fourni des outils d'analyse puissants facilement applicables aux images satellites.
+
+### Cas d'usage
+
+Les cas d'usage potentiels d'utilisation de ces données pour la statistique publique touchent de nombreux thèmes, qui incluent :
+
+- La supervision des forêts, de l'agriculture, des masses d'eau ;
+- L'urbanisation et les infrastructures ;
+- La pollution environnementale et la qualité de l'air atmosphérique ;
+
+En particulier, l'analyse d'images satellite peut permettre de calculer des indicateurs comme la proportion de surface agricole en agriculture intensive ou en agriculture durable,
+le pourcentage de masses d'eau présentant une bonne qualité de l'eau ambiante,
+la couverture forestière dans le cadre d'une gestion forestière durable,
+la perte nette permanente de forêts, etc.
+
+
+
+Plusieurs cas d'usage précis ont été ciblés aujourd'hui pour la statistique publique en France et donnent ou vont donner lieu à des travaux expérimentaux.
+
+1. Un des cas d'usage identifiés depuis un moment déjà est l'utilisation d'images satellites pour calculer les __statistiques sur l'occupation et l'usage des sols sur le territoire français__. Aujourd'hui, ces statistiques sont tirées de l'enquête `Teruti` conduite par le Bureau des statistiques structurelles environnementales et forestières du SSP (Ministère de l'Agriculture).
+
+ Un échantillon de points est observé sur le terrain sur un cycle de 3 ans permettant d'estimer l’occupation des sols avec une précision qui reste satisfaisante à l'échelon départemental. L'échantillonnage des points se fait à partir de sources multiples, dont des données satellitaires (satellite SPOT) et des orthophotographies de l'IGN. En outre, une phase de validation des résultats de l'enquête est réalisée à partir d'une couche d'exploitation du sol issue de données de Sentinel-2 et réalisée de manière automatique est le Centre d'Etudes Spatiales sur la BIOsphere à Toulouse.
+
+ Des travaux sont actuellement en cours pour encore davantage améliorer la phase d'échantillonnage à l'aide d'images satellitaires. En outre, une méthode automatique donnant des couches d'exploitation des sols avec une précision suffisante pour les besoins de la statistique publique pourrait permettre de diffuser des statistiques plus régulièrement qu'avec l'enquête Teruti et avec une granularité territoriale plus fine.
+
+2. Les __parcelles cadastrales__ sont parfois mal identifiées dans les départements et région d'outre-mer, en particulier en Guyane et à Mayotte. Or ces parcelles sont utilisées pour des tirages d'échantillon par l'Insee, pour le recensement de la population par exemple.
+
+ Ici encore, des modèles de segmentation retournant des couches d'exploitation et d'usage des sols peuvent être utilisés pour consolider l'information disponible sur les parcelles cadastrales. Dans le cadre d'une expérimentation, un modèle de segmentation `U-Net` [@ronneberger-15] pré-entraîné sur le jeu de données [`ImageNet`](https://www.image-net.org/) a été fine-tuné sur un sous-échantillon du jeu annoté `S2GLC` (`Sentinel-2 Global Land Cover`). Ce modèle prend en entrée une image satellite et renvoie une prédiction pixel par pixel de la catégorie de terrain (en 10 classes), comme illustré en @fig-satellite. S'il est assez précis sur la catégorie *surfaces artificielles et construction*, ses prédictions pourraient servir à consolider les données cadastrales.
+
+::: {#fig-satellite layout="[-1,10,-1,10,-1,10,-1]"}
+
+
+
+
+
+
+À gauche : image satellite issue de Sentinel-2. Au milieu : segmentation prédite par le modèle U-Net. À droite : vraie segmentation de l'image.
+:::
+
+3. L'__enquête sur la structure des exploitations agricoles__ (Bureau des statistiques structurelles environnementales et forestières du SSP) dont la prochaine édition aura lieu en 2023 pose des questions sur les vergers. Il n'existe aujourd'hui pas de source administrative permettant de consolider les résultats de l'enquête sur cette thématique.Ainsi, un projet d'expérimentation utilisant des orthophotographies pour dénombrer le nombre d'arbres et la surface associée est envisagé. La librairie [`DeepForest`](https://github.com/weecology/DeepForest-pytorch) propose des modèles pré-entraînés pour faire de la détection d'arbres (voir @fig-detection) et pourra servir de point de départ pour cette expérimentation.
+
+::: {#fig-detection}
+
+
+Détection d'arbres sur une orthophotographie à l'aide de la librairie `DeepForest`.
+:::
+
+:::{.callout-note}
+Plusieurs questions méthodologiques essentielles se posent lorsqu'on exploite des données satellitaires grâce à des méthodes de Deep Learning :
+
+- Architectures des modèles
+- Utilisation des différentes bandes
+- Pré-traitements sur les images : détection et suppression de nuages, amélioration de la résolution ;
+- Transférabilité des modèles : est-ce qu'un modèle entraîné sur des images provenant d'un satellite fonctionnera correctement avec des images provenant d'un autre satellite ? Ou avec un réentraînement minimal ?
+
+Un enjeu majeur est l'obtention de __données annotées__ (même si le pré-entraînement de modèles sur des jeux de données énormes réduit le besoin de données annotées pour la tâche considérée). Pour des tâches de prédiction de l'utilisation du sol, on peut par exemple mobiliser la base de données géographiques [`CORINE Land Cover`](https://www.statistiques.developpement-durable.gouv.fr/corine-land-cover-0), un inventaire biophysique qui fournit une photographie complète de l’occupation des sols, à des fréquences régulières.
+
+Elle est issue de l'interprétation visuelle d'images satellitaires, avec des données complémentaires d'appui. Les classes d'occupation correspondent à une nomenclature comportant 44 postes.
+:::
+
+## La reconnaissance optique de caractères
+
+L'administration française a été historiquement une grande productrice
+de fichiers sous format papier. Même si la numérisation des sources
+de collectes administratives réduit le volume de production papier,
+ce dernier mode de collecte est encore d'usage. Afin de réduire
+le temps de numérisation, il est donc utile de mettre en oeuvre
+des routines automatisées. Dans la même veine, l'administration
+a longtemps mis en oeuvre des publications (tableaux ou graphiques)
+sous format papier. Être en mesure de valoriser ce patrimoine
+de connaissance est un enjeu pour la recherche.
+
+La reconnaissance optique de caractères (souvent abrégée par `OCR` pour *Optical character recognition*) désigne la tâche de conversion de texte manuscrit ou imprimé en texte encodé par un ordinateur. C'est une tâche essentielle pour exploiter des documents disponibles sous la forme d'images numériques.
+
+Développer son propre moteur d'OCR est une tâche très complexe mais heureusement des moteurs *open source* existent. [`Tesseract`](https://github.com/tesseract-ocr/tesseract) est un logiciel pour la reconnaissance de caractères *open source* depuis 2015. `Tesseract` offre plusieurs moteurs depuis sa version 4 : en plus du moteur historique, un moteur basé sur le Deep Learning (réseaux de neurones LSTM) est aujourd'hui disponible.
+
+### Application : extraction d'informations de documents scannés photographiés
+
+Des documents scannés ou photographies peuvent souvent constituer
+une source d'information précieuse pour la production de statistiques publiques.
+
+Par exemple, la Direction des Statistiques d'Entreprises (DSE) à l'Insee effectue de manière périodique un *profilage* des groupes de sociétés.
+Pour la statistique publique la notion d'entreprise est souvent associée à une définition purement juridique,
+c'est-à-dire à la notion d'unité légale inscrite au répertoire Sirene.
+Toutefois, aujourd'hui certaines unités légales sont détenues par d’autres et peuvent ainsi perdre une partie de leur autonomie.
+Le *profilage* consiste à identifier au sein des groupes les entreprises au sens économique,
+puis à collecter et calculer des statistiques sur ces nouveaux contours.
+
+La plupart des catégories de sociétés ont l'obligation de déposer annuellement leurs comptes sociaux au Registre du commerce et des sociétés (RCS), afin d'en garantir la transparence.
+Les documents à déposer incluent les comptes annuels (bilan actif et passif, compte de résultats et annexes), le rapport de gestion pour les sociétés cotées, les documents portant sur l'affectation du résultat, etc.
+Dans le cas où une société possède des filiales ou participations au moins à hauteur de 10\% du capital,
+elle doit inclure dans ses comptes sociaux un tableau *des filiales et participations* (voir @fig-filiales-ex) offrant une vision financière synthétique des différentes filiales et participations détenues. Ce tableau est très utile pour consolider le profilage d'un groupe, car il centralise des informations qui sont difficiles à obtenir par ailleurs.
+
+::: {#fig-filiales-ex}
+{ width=60% }
+
+Exemple d'un tableau *des filiales et participations* figurant dans les comptes sociaux d'une société.
+:::
+
+Aujourd'hui, les profileurs de la DSE utilisent les comptes sociaux de manière manuelle.
+Ils récupèrent les comptes sociaux,
+souvent sous la forme de documents scannés, depuis une interface de programmation mise à disposition par l'Institut National de la Propriété Industrielle (INPI) et pour chaque groupe qui les intéresse,
+cherchent eux-mêmes l'emplacement du tableau *des filiales et participations* dans le document puis récupèrent les informations pertinentes pour la consolidation.
+La reconnaissance optique de caractères peut permettre de traiter automatiquement (au moins en partie) les comptes sociaux,
+ce qui permettrait à la fois de dégager du temps aux profileurs pour des activités à plus forte valeur ajoutée,
+mais aussi de consolider plus de comptes.
+
+Une chaîne de traitement complète envisagée pour l'extraction d'un tableaux filiales et participations est décrite ci-dessous :
+
+- On récupère l'exemplaire des comptes sociaux d'intérêt via un appel à l'API de l'INPI ;
+- Un document est en général constitué de plusieurs pages. Pour identifier la page sur laquelle se trouve le tableau des *filiales et participations*, tout le texte de chaque page du document est extrait à l'aide d'un moteur de reconnaissance de caractères. Puis un modèle de forêt aléatoire qui a été entraîné sur des observations annotées à la main prend en entrée la totalité des mots présents sur chaque page, pour renvoyer en sortie une probabilité que le tableau des *filiales et participations* y soit présent. Pour un document donné, on retient la page avec la probabilité de sortie la plus élevée si cette dernière dépasse un certain seuil fixé empiriquement.
+- L'extraction à proprement parler du tableau se fait ensuite en plusieurs étapes :
+ - D'abord l'image est pré-traitée : elle est remise droite dans le cas où le document a été scanné de travers, les couleurs sont inversées si on repère une zone de l'image où du texte blanc figure sur une zone sombre, etc. ;
+ - On applique ensuite le modèle de segmentation `TableNet` [@paliwal-20] à l'image, qui retourne deux masques : le premier masque indique l'emplacement des tableaux au sein de l'image, et le deuxième indique l'emplacement des colonnes au sein de l'image (voir @fig-tablenet). Ce modèle a été entraîné à partir du jeu de données annotées [Marmot](https://www.icst.pku.edu.cn/cpdp/sjzy/) disponible en libre accès sur Internet et optionnellement à partir de données supplémentaires des comptes sociaux annotées à la main ;
+ - Les masques sont post-traités dans l'étape suivante où des artefacts sont retirés, la table et les colonnes sont remplis lorsque des *trous* apparaissent sur les masques, etc. ;
+ - Le contenu de chaque colonne est extrait (chaque caractère accompagné de sa position sur l'image) grâce à un moteur de reconnaissance optique de caractères (par exemple Tesseract) ;
+ - Les colonnes sont alignées pour reconstituer la table aussi bien que possible ;
+ - On identifie les colonnes de la table utile pour la consolidation des comptes grâce à l'utilisation d'expressions régulières et d'une distance textuelle ;
+ - Le tableau avec les noms de colonnes nettoyés est enfin exporté (par exemple en format csv).
+
+::: {#fig-tablenet layout="[-3,10,-1,10,-3]"}
+
+
+
+
+Exemple de masques bruts obtenus en sortie de TableNet. À gauche, le masque indiquant l'emplacement de la table. À droite, le masque indiquant l'emplacement des colonnes.
+:::
+
+### Extraction d'information de tickets de caisse
+
+L'enquête Budget des Familles, réalisée par
+la Direction des statistiques démographiques et sociales (DSDS) de l'Insee,
+repose traditionnellement sur la collecte de tickets de caisse dont les
+champs sont
+manuellement repris et numérisés par les enquêteurs[^1].
+Toutefois, il existe aujourd'hui des méthodes pour automatiser cette extraction en utilisant des moteurs de reconnaissance optique de caractères.
+
+[^1]: Plus précisément, les ménages enquêtés se voient confier un carnet de dépenses qu'ils doivent remplir pendant une certaine période. Pour certaines dépenses les carnets sont renseignés à la main par un membre du ménage. Pour d'autres, le ménage a la possibilité d'inclure dans le carnet des tickets de caisse. Jusqu'à présent les enquêteurs étaient chargés de recopier le contenu des tickets de caisse pour rendre ces données exploitables.
+
+
+
+Une première idée envisageable est d'utiliser un moteur d'OCR pour récupérer ligne par ligne le texte figurant sur un ticket de caisse puis d'extraire l'information sous forme structurée avec une approche basée sur des règles. Les tickets de caisse se ressemblant en général beaucoup, cette approche fonctionne convenablement sur cette tâche quelque soit le ticket, mais elle présente tout de même des défauts de généralisabilité. Une approche *Deep Learning end-to-end* est préférable, même si elle nécessite des données annotées. De telles méthodes ont été testées dans le cadre de compétitions (notamment sur les jeux de données [SROIE 2019](https://rrc.cvc.uab.es/?ch=13&com=introduction) et [Cord](https://github.com/clovaai/cord)) et ont donné de bons résultats.
+
+### References
+
+::: {#refs}
+:::
diff --git a/images_exemples.qmd b/images_exemples.qmd
new file mode 100644
index 0000000..710a969
--- /dev/null
+++ b/images_exemples.qmd
@@ -0,0 +1,16 @@
+---
+title: "Application"
+---
+
+L'objectif de ce TP est d'explorer l'exploitation d'images à l'aide de modèles de Deep Learning,
+avec une application sur les images satellitaires pour la statistique publique.
+
+Le TP peut être lancé sur le `SSP Cloud` en cliquant sur le bouton suivant:
+
+ +
+Le notebook `classification_oiseau.ipynb` traite un problème simple de classification d'image, à regarder dans un premier temps. Le notebook `donnees_satellite.ipynb` traite ensuite un problème de segmentation sémantique sur des images satellitaires, qui permet d'obtenir des cartes de couverture du territoire pouvant être utilisées pour produire des statistiques officielles.
+
+Un second bouton si l'installation de `Pytorch` est trop longue:
+
+
diff --git a/img/geolocalized_data/carte_densite.png b/img/geolocalized_data/carte_densite.png
new file mode 100644
index 0000000..3fcfe50
Binary files /dev/null and b/img/geolocalized_data/carte_densite.png differ
diff --git a/img/geolocalized_data/confinement-deconfinement.png b/img/geolocalized_data/confinement-deconfinement.png
new file mode 100644
index 0000000..bd38f18
Binary files /dev/null and b/img/geolocalized_data/confinement-deconfinement.png differ
diff --git a/img/images/bike.jpg b/img/images/bike.jpg
new file mode 100644
index 0000000..d401a4f
Binary files /dev/null and b/img/images/bike.jpg differ
diff --git a/img/images/bike_sobel.jpg b/img/images/bike_sobel.jpg
new file mode 100644
index 0000000..e15cc2b
Binary files /dev/null and b/img/images/bike_sobel.jpg differ
diff --git a/img/images/column_mask.png b/img/images/column_mask.png
new file mode 100644
index 0000000..4889f32
Binary files /dev/null and b/img/images/column_mask.png differ
diff --git a/img/images/convol.png b/img/images/convol.png
new file mode 100644
index 0000000..c1e3d1f
Binary files /dev/null and b/img/images/convol.png differ
diff --git a/img/images/detection_arbre.png b/img/images/detection_arbre.png
new file mode 100644
index 0000000..87c2f95
Binary files /dev/null and b/img/images/detection_arbre.png differ
diff --git a/img/images/dsn-diff.png b/img/images/dsn-diff.png
new file mode 100644
index 0000000..2949d0f
Binary files /dev/null and b/img/images/dsn-diff.png differ
diff --git a/img/images/dsn-schema.png b/img/images/dsn-schema.png
new file mode 100644
index 0000000..7a46683
Binary files /dev/null and b/img/images/dsn-schema.png differ
diff --git a/img/images/filiales_ex.png b/img/images/filiales_ex.png
new file mode 100644
index 0000000..0be3246
Binary files /dev/null and b/img/images/filiales_ex.png differ
diff --git a/img/images/image_satellite.png b/img/images/image_satellite.png
new file mode 100644
index 0000000..1c417cc
Binary files /dev/null and b/img/images/image_satellite.png differ
diff --git a/img/images/image_segmentation_input.jpeg b/img/images/image_segmentation_input.jpeg
new file mode 100644
index 0000000..2d981e4
Binary files /dev/null and b/img/images/image_segmentation_input.jpeg differ
diff --git a/img/images/image_segmentation_output.png b/img/images/image_segmentation_output.png
new file mode 100644
index 0000000..71ec57b
Binary files /dev/null and b/img/images/image_segmentation_output.png differ
diff --git a/img/images/predicted_segmentation.png b/img/images/predicted_segmentation.png
new file mode 100644
index 0000000..8cb1566
Binary files /dev/null and b/img/images/predicted_segmentation.png differ
diff --git a/img/images/python_blue.png b/img/images/python_blue.png
new file mode 100644
index 0000000..1c9592b
Binary files /dev/null and b/img/images/python_blue.png differ
diff --git a/img/images/python_green.png b/img/images/python_green.png
new file mode 100644
index 0000000..9dbcf25
Binary files /dev/null and b/img/images/python_green.png differ
diff --git a/img/images/python_pixels.png b/img/images/python_pixels.png
new file mode 100644
index 0000000..1e213ec
Binary files /dev/null and b/img/images/python_pixels.png differ
diff --git a/img/images/python_red.png b/img/images/python_red.png
new file mode 100644
index 0000000..9ff3a83
Binary files /dev/null and b/img/images/python_red.png differ
diff --git a/img/images/real_segmentation.png b/img/images/real_segmentation.png
new file mode 100644
index 0000000..bd383db
Binary files /dev/null and b/img/images/real_segmentation.png differ
diff --git a/img/images/rgb_image.png b/img/images/rgb_image.png
new file mode 100644
index 0000000..e9abf0d
Binary files /dev/null and b/img/images/rgb_image.png differ
diff --git a/img/images/table_mask.png b/img/images/table_mask.png
new file mode 100644
index 0000000..bd84c91
Binary files /dev/null and b/img/images/table_mask.png differ
diff --git a/index.qmd b/index.qmd
new file mode 100644
index 0000000..e58e383
--- /dev/null
+++ b/index.qmd
@@ -0,0 +1,9 @@
+---
+title: "Données émergentes (ENSAI)"
+---
+
+Ce site web centralise les contenus du cours de Master de l'ENSAI sur les données émergentes
+
+:::{.callout-note}
+Ce site est encore dans une version très provisoire. Le contenu peut ainsi être amené à évoluer rapidement
+:::
\ No newline at end of file
diff --git a/introduction.qmd b/introduction.qmd
new file mode 100644
index 0000000..b0583bc
--- /dev/null
+++ b/introduction.qmd
@@ -0,0 +1,290 @@
+---
+title: "Introduction"
+---
+
+## Les données émergentes dans le temps long
+
+L'histoire de la statistique est une suite d'évolutions
+de la discipline où les données émergentes un jour deviennent
+le lendemain traditionnelles.
+Le XIXe siècle, qui est celui
+où la statistique s'est constituée en temps
+que discipline autonome et s'est dotée d'une partie
+des concepts qui en font aujourd'hui les fondements,
+est ainsi une période où de nombreuses données
+ont émergé et ont pu entraîner des révolutions scientifiques.
+Parmi celles-ci, la construction de la loi normale,
+qui constitue aujourd'hui l'objet central
+de la statistique, correspond au besoin de construire
+de nouveaux concepts et
+outils afin de structurer dans une théorie commune
+un ensemble de nouvelles données.
+La manière dont Gauss a collecté et
+synthétisé un ensemble d'observations
+astronomiques a ainsi permis de construire
+la méthode des moindres carrés et
+le concept de loi normale, appréhendé
+à partir des erreurs d'observations.
+
+L'accès à des recensements par des universitaires
+à la fin
+du XIXe siècle a été un élément moteur
+de la constitution de la sociologie en temps
+que discipline autonome.
+Les registres de décès ont ainsi permis
+à Durkheim de participer aux débats sociologiques
+sur le suicide et de proposer une
+interprétation sociologique
+de ses causes à rebours des
+approches psychologisantes qui
+étaient fréquentes à l'époque.
+Avant Durkheim, l'usage novateur
+des monographies a permis de
+dessiner les prémisses de la sociologie en
+temps que discipline autonome.
+Les avancées de la statistique au cours
+du XXe siècle sont intimement liées
+à la génération des enquêtes ou des sondages.
+
+Les notions d'échantillonnage, de représentativité,
+ou encore de marges d'erreur, qui sont au coeur de la
+statistique moderne, ont permis de rendre traditionnel
+ce nouveau mode de collecte. Ces enquêtes sont
+aujourd'hui
+encore très
+utilisées dans la production statistique moderne ou
+dans les
+études économiques et sociologiques.
+
+La prolifération de traces numériques, parce
+qu'elle a créé de nouvelles opportunités pour
+la puissance publique ou pour des acteurs privés
+de valoriser des données, est un moteur
+d'évolution de la statistique.
+L'émergence du concept
+de _data-science_, qu'on le considère
+comme un ensemble de pratiques ou uniquement comme
+un _buzzword_, est intimement lié à la multiplication
+des traces numériques.
+Les nouvelles disciplines ou méthodes qui se sont développées récemment
+sont intrinsèquement liées aux données
+émergentes.
+La vitesse à laquelle se
+développent les innovations dans le domaine de
+la _data-science_
+est d'une ampleur inédite du fait
+de la multiplicité des données collectées
+et des acteurs impliqués. IBM estimait en effet que 2.5 quintillions d'octets de données étaient générés chaque jour il y a environ 10 ans.
+Dans un ouvrage sur l'histoire de la statistique, @hacking-90 parle déjà en 1990 du début d'une "avalanche de chiffres".
+
+
+## La production renouvelée de données de la puissance publique
+
+La puissance publique est une productrice
+historique de données. Les
+registres administratifs ou
+comptables sont une source
+de données très appréciée des
+historiens. Si elles n'atteignent
+pas les volumétries actuelles,
+ces sources sont néanmoins
+les ancêtres de nos données administratives actuelles.
+Les recensements de population sont également
+une des productions historiques de données.
+Le comptage de la population et des impôts
+fait partie intégrante du processus
+de constitution de la puissance
+publique centralisatrice [@desrosieres2016politique].
+Curieusement, la tablette Kish de l'empire sumérien (environ 3500 av. J.-C.), l'un des plus anciens exemples d'écriture humaine, semble être un document administratif destiné à des fins statistiques.
+
+
+La
+statistique publique, si elle est aujourd'hui
+entendue beaucoup plus largement que par le passé,
+et qu'elle dispose d'une indépendance vis-à-vis
+d'autres branches de l'Etat,
+c'est parce qu'elle est un élément essentiel pour
+pour permettre le bon fonctionnement de l'économie et de la démocratie.
+Le slogan de l'Insee, _"mesurer pour comprendre"_,
+correspond bien à cette idée.
+Les statistiques officielles essaient d'objectiver les phénomènes
+socio-économiques par la collecte de données et la construction
+de concepts cohérents avec le phénomène mesuré.
+
+Les enquêtes sont historiquement une
+source privilégiée puisque
+la conception de celles-ci, en amont de la collecte et
+des retraitements post-collecte, est
+justement effectuée en fonction des
+réutilisations futures.
+Les questions sont ainsi conçues pour
+s'approcher au plus près des phénomènes qu'on
+désire quantifier et
+l'échantillonnage puis les redressements post-collecte
+permettront de contrôler la population
+sur laquelle portent les statistiques construites.
+L'inconvénient est que cette production nécessite des moyens
+et un temps conséquents (en amont de la collecte, lors de celle-ci puis
+à l'issue de celle-ci). De plus, les enquêtes ne sont pas à l'abri
+d'erreurs dans la collecte, qu'il s'agisse d'omissions ou réponses
+erronnées, qu'elles soient volontaires ou non.
+A ces problèmes s'ajoute la baisse historique des taux de réponse
+[@riviere2018].
+
+L'Etat n'accumule pas uniquement de la connaissance sur sa population
+par le biais d'enquête. Les registres des impôts, de l'assurance maladie, etc.
+sont des sources de gestion par lesquelles chaque individu communique
+un certain nombre d'informations sur lui. On parle
+de données administratives pour regrouper cet ensemble
+de sources qui sont produites par la puissance publique
+et dont la collecte répond à des enjeux de
+gestion mais pas à des besoins de statistique publique.
+La définition qu'en donnait @desrosieres2004,
+résume bien ceci: _"une source administrative est issue d'une institution dont la finalité n'est pas de produire une telle information, mais dont les activités de gestion impliquent la tenue, selon des règles générales, de fichiers ou de registres individuels, dont l'agrégation n'est qu'un sous-produit"_.
+Les besoins de la statistique publique
+ne sont donc pas à la source de la collecte mais on peut utiliser celle-ci
+comme opportunité pour enrichir la connaissance de phénomènes
+socio-économiques
+(Connelly et al., Einav et al.).
+Certaines informations disponibles dans ces données sont très
+génériques et communes à de nombreuses bases de gestion (l'état civil notamment),
+ce qui peut faciliter l'association entre elles,
+alors que d'autres sont propres à chaque source. Outre la possibilité de
+disposer d'informations sur une population plus importante, la différence
+principale entre ces
+sources de données,
+historiquement collectées
+par papier et de plus en plus par collecte numérique, et les enquêtes est
+que les premières ne sont pas conçues initialement
+à des fins de statistique donc le statisticien n'en contrôle pas
+la conceptualisation et la collecte.
+Néanmoins, ces sources peuvent fournir des informations très
+précieuses à la statistique publique. Si on est en mesure de relier celles-ci à
+une enquête, il devient possible d'enrichir ou de corriger certaines informations
+collectées si les concepts présents dans l'enquête correspondent à ceux de la
+source administrative.
+
+Les données administratives deviennent ainsi de plus en plus
+fréquemment mobilisées dans la production officielle
+de statistiques ou dans les études économiques.
+La numérisation de l'économie et
+des démarches administratives, parce qu'elle a facilité
+la constitution de bases et l'association entre
+celles-ci, a accéléré
+le mouvement de constitution de grands répertoires
+administratifs. Parmi les principaux exploités par la statistique
+publique :
+la DSN, Fidéli, le SNDS... La construction de ces sources,
+car celles-ci nécessitent pour leur usage à des fins
+statistiques une reconstruction,
+implique également un changement des institutions collectant
+la donnée. Ce n'est plus l'Insee qui collecte directement la
+donnée (que ce soit à son compte ou pour le compte d'autres
+institutions comme les services statistiques ministériels)
+mais des ministères. Ces derniers peuvent, ou non,
+exploiter ces données à leur propre compte mais aussi
+mettre à disposition la donnée brute ou une version
+retravaillée de celle-ci.
+Par exemple, la Direction Générale des Finances Publiques (DGFiP)
+est, par son rôle de collecte des impôts, un acteur central
+dans la constitution de bases sur les revenus qui permettent
+de produire de nombreuses statistiques socio-économiques.
+De même, la Caisse Nationale d'Assurance Maladie (CNAM)
+est, par son rôle de gestionnaire du système français de sécurité sociale,
+un élément central dans la constitution
+du Système national des données de santé (SNDS).
+
+La multiplication de traces numériques collectées non plus
+seulement par les acteurs publics mais aussi par des
+acteurs privés a permis de produire de nouvelles
+sources de données, à une fréquence ou à une échelle inédite.
+A ce premier facteur qu'est l'intensification de la production
+de statistique, s'ajoute la demande croissante de la
+population et des décideurs publics pour des statistiques
+plus détaillées et disponibles plus rapidement.
+Cela a ainsi amené à une intensification de la disponibilité
+de statistiques, dont la production n'est plus le monopole
+de la puissance publique.
+Afin de pouvoir produire ces statistiques, tout en satisfaisant
+aux critères usuels de qualité sur lesquels nous reviendrons,
+la statistique publique se doit d'innover dans la collecte
+traditionnelle, l'utilisation de nouvelles statistiques
+et concepts ou dans les processus de valorisation de données
+auquel elle accédait déjà. Parmi ces trois facteurs, nous
+allons principalement nous concentrer sur le deuxième,
+c'est-à-dire la valorisation de nouvelles sources de données, qu'il
+s'agisse de données produites par l'administration ou de données
+privées. Le premier point - l'innovation dans les méthodes de collecte
+traditionnelles - renvoie, entre autres, à la question du multimode.
+Enfin, en ce qui concerne le troisième élément - la rénovation des processus
+de production - il y a des éléments connexes à notre problématique
+(certaines méthodes sont intrinsèquement liées à de nouvelles sources) mais
+aussi certains qui le dépassent. Nous n'allons donc pas nous concentrer sur
+ceux-ci bien qu'il se peut que nous évoquions à plusieurs reprises ces enjeux.
+
+# Innover pour traiter ces données
+
+Les nouvelles données permettent ainsi de faire évoluer la production statistique
+en amenant à essayer d'objectiver des phénomènes qui l'étaient difficilement
+par le passé. Le fait qu'elles n'aient pas été produites initialement pour être traitées à
+des fins de statistique publique implique un surcroit de travail et de précautions
+méthodologiques pour en assurer la qualité et l'exploitation.
+Il est également nécessaire de travailler sur les métadonnées (description des données)
+pour répondre aux exigences de la statistique publique.
+
+La volumétrie et la (dé)structuration des nouvelles sources de données
+a de forts enjeux informatiques. Les innovations dans
+ce domaine sont à un rythme impressionnant. Les acteurs
+majeurs du numérique, qui sont les principaux acteurs de la collecte
+de données, sont ainsi les principaux développeurs des langages de _data-science_
+modernes. Ces derniers sont des solutions logicielles pour faciliter le traitement
+de tel ou tel type de données.
+Par exemple, `TensorFlow` a été développé par `Google`, `PyTorch` par
+`Meta`, `Airflow` par `Airbnb`.
+
+# Collaboration avec de nouveaux acteurs
+
+Ces nouvelles sources de données sont collectées par de nouveaux acteurs, qu'il
+s'agisse d'administrations, d'acteurs privés ou d'autres acteurs
+tiers (ONG, associations, instituts de recherche, etc.).
+Ces données sont parfois déjà valorisées par ces acteurs: certains acteurs
+proposent des solutions commerciales qui revendent certains agrégats
+issus des données qu'ils collectent.
+
+Pour la statistique publique, il y a donc un enjeu à
+construire des partenariats pour accéder sur la durée
+à des données collectées par d'autres. Les
+exploitations de nouvelles sources ayant été
+principalement expérimentales,
+les partenariats entre l'administration et les
+entreprises ont jusqu'à présent été souvent
+ponctuels. Les données de caisse, c'est-à-dire
+les données de supermarchés qui sont collectées
+automatiquement en caisse, sont une exception. Une réglementation
+européenne imposant leur usage pour la constitution des statistiques
+d'inflation et des séries de prix, [l'accès pérenne à celles-ci a été nécessaire](https://www.insee.fr/fr/information/4318285).
+
+Pour construire ces partenariats durables,
+il est nécessaire de respecter les intérêts des entreprises qui détiennent les données.
+Il y a besoin de confiance, de garanties de confidentialité, ce qui demande un cadre légal facilitateur.
+La responsabilité sociale doit constituer un moteur pour avancer.
+
+
+- Sur la confidentialité des données : *privacy-enhancing technologies*.
+- Besoin de moderniser la manière de produire des statistiques officielles pour s'adapter aux nouvelles sources de données et faciliter les partenariats : méthodologie et travail sur la qualité transparents (code open-source, reproductible au maximum);
+- Fonctionnement participatif et agile pour identifier les potentiels problèmes liés à la réutilisation de données privées (besoin d'experts de ces données). Réseaux de recherche avec les partenaires privés, la recherche académique, etc.
+
+# Historique
+
+- [Principes fondamentaux de la statistique publique](https://unstats.un.org/unsd/dnss/gp/fundprinciples.aspx) établis par les Nations Unies ;
+- Règles de qualité fixées par le [Code Européen de Bonnes Pratiques Statistiques](https://ec.europa.eu/eurostat/web/quality/european-quality-standards/european-statistics-code-of-practice).
+
+# Futur
+
+- L'[*Open Data Directive*](https://eur-lex.europa.eu/legal-content/EN/TXT/?qid=1561563110433&uri=CELEX:32019L1024) adoptée en 2019 identifie des jeux de données open-source à forte valeur potentielle pour la statistique publique ;
+- Le *Data Governance Act* (adopté en Mai 2022 et appliqué à partir de Septembre 2023) : promeut le partage de données personnelles et non-personnelles en mettant en place des structures d'intermédiation:
+ - Assistance technique et légale pour faciliter la réutilisation de certaines données protégées du secteur publique;
+ - Structures d'intermédiation de la donnée;
+ - Certification pour les organisations qui pratiquent le *data altruism*.
+- Le *Data Act* (proposition en Février 2022): règles sur qui peut accéder aux données générées au sein de l'UE dans chaque secteur économique, avec l'objectif de rendre les données plus accessibles pour tous;
+- Les textes vont dans une direction commune: encourager la réutilisation de données privées. Il est aussi nécessaire d'encourager une intensification des dialogues entre parties prenantes et la société entière.
diff --git a/nowcasting_exemples.qmd b/nowcasting_exemples.qmd
new file mode 100644
index 0000000..e4592e1
--- /dev/null
+++ b/nowcasting_exemples.qmd
@@ -0,0 +1,14 @@
+---
+title: "Application"
+---
+
+L'objectif de ce TP est de montrer comment récupérer des données à partir de l'API de Twitter
+et de montrer un début d'exemple d'exploitation de ces données.
+
+Le TP peut être lancé sur le `SSP Cloud` en cliquant sur le bouton suivant:
+
+
+
+Un second bouton si l'installation de `Pytorch` est trop longue:
+
+
diff --git a/references.bib b/references.bib
new file mode 100644
index 0000000..831840f
--- /dev/null
+++ b/references.bib
@@ -0,0 +1,389 @@
+@article{sobel-73,
+author = {Sobel, Irwin and Feldman, Gary},
+year = {1973},
+month = {01},
+pages = {271-272},
+title = {A 3×3 isotropic gradient operator for image processing},
+journal = {Pattern Classification and Scene Analysis}
+}
+
+@article{brown2020language,
+ title={Language models are few-shot learners},
+ author={Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and others},
+ journal={Advances in neural information processing systems},
+ volume={33},
+ pages={1877--1901},
+ year={2020}
+}
+
+@inproceedings{pennington2014glove,
+ title={Glove: Global vectors for word representation},
+ author={Pennington, Jeffrey and Socher, Richard and Manning, Christopher D},
+ booktitle={Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP)},
+ pages={1532--1543},
+ year={2014}
+}
+
+
+@inproceedings{galiana2022,
+ author = {Galiana, Lino and Suarez Castillo, Milena},
+ title = {Fuzzy Matching on Big-Data: An Illustration with Scanner and Crowd-Sourced Nutritional Datasets},
+ year = {2022},
+ isbn = {9781450392846},
+ publisher = {Association for Computing Machinery},
+ address = {New York, NY, USA},
+ url = {https://doi.org/10.1145/3524458.3547244},
+ doi = {10.1145/3524458.3547244},
+ abstract = {Food retailers’ scanner data provide unprecedented details on local consumption, provided that product identifiers allow a linkage with features of interest, such as nutritional information. In this paper, we enrich a large retailer dataset with nutritional information extracted from crowd-sourced and administrative nutritional datasets. To compensate for imperfect matching through the barcode, we develop a methodology to efficiently match short textual descriptions. After a preprocessing step to normalize short labels, we resort to fuzzy matching based on several tokenizers (including n-grams) by querying an ElasticSearch customized index and validate candidates echos as matches with a Levensthein edit-distance and an embedding-based similarity measure created from a siamese neural network model. The pipeline is composed of several steps successively relaxing constraints to find relevant matching candidates.},
+ booktitle = {Proceedings of the 2022 ACM Conference on Information Technology for Social Good},
+ pages = {331–337},
+ numpages = {7},
+ keywords = {ElasticSearch, Fuzzy matching, Siamese neural networks, Natural language processing, Word embeddings},
+ location = {Limassol, Cyprus},
+ series = {GoodIT '22}
+}
+
+
+@article{LuitenHoxde,
+author = {Annemieke Luiten and Joop Hox and Edith de Leeuw},
+doi = {doi:10.2478/jos-2020-0025},
+url = {https://doi.org/10.2478/jos-2020-0025},
+title = {Survey Nonresponse Trends and Fieldwork Effort in the 21st Century: Results of an International Study across Countries and Surveys},
+journal = {Journal of Official Statistics},
+number = {3},
+volume = {36},
+year = {2020},
+pages = {469--487}
+}
+
+
+
+@ARTICLE{lecun-89,
+author={LeCun, Y. and Boser, B. and Denker, J. S. and Henderson, D. and Howard, R. E. and Hubbard, W. and Jackel, L. D.},
+journal={Neural Computation},
+title={Backpropagation Applied to Handwritten Zip Code Recognition},
+year={1989},
+volume={1},
+number={4},
+pages={541-551},
+doi={10.1162/neco.1989.1.4.541}
+}
+
+@article{voulodimos-18,
+doi = {10.1155/2018/7068349},
+url = {https://doi.org/10.1155/2018/7068349},
+year = {2018},
+publisher = {Hindawi Limited},
+volume = {2018},
+pages = {1--13},
+author = {Athanasios Voulodimos and Nikolaos Doulamis and Anastasios Doulamis and Eftychios Protopapadakis},
+title = {Deep Learning for Computer Vision: A Brief Review},
+journal = {Computational Intelligence and Neuroscience}
+}
+
+@article{chen-17,
+author = {Liang{-}Chieh Chen and
+ George Papandreou and
+ Florian Schroff and
+ Hartwig Adam},
+title = {Rethinking Atrous Convolution for Semantic Image Segmentation},
+journal = {CoRR},
+volume = {abs/1706.05587},
+year = {2017},
+url = {http://arxiv.org/abs/1706.05587},
+eprinttype = {arXiv},
+eprint = {1706.05587},
+timestamp = {Mon, 13 Aug 2018 16:48:07 +0200},
+biburl = {https://dblp.org/rec/journals/corr/ChenPSA17.bib},
+bibsource = {dblp computer science bibliography, https://dblp.org}
+}
+
+@article{steele-17,
+doi = {10.1098/rsif.2016.0690},
+url = {https://doi.org/10.1098/rsif.2016.0690},
+year = {2017},
+month = feb,
+publisher = {The Royal Society},
+volume = {14},
+number = {127},
+pages = {20160690},
+author = {Jessica E. Steele and P{\aa}l Roe Sunds{\o}y and Carla Pezzulo and Victor A. Alegana and Tomas J. Bird and Joshua Blumenstock and Johannes Bjelland and Kenth Eng{\o}-Monsen and Yves-Alexandre de Montjoye and Asif M. Iqbal and Khandakar N. Hadiuzzaman and Xin Lu and Erik Wetter and Andrew J. Tatem and Linus Bengtsson},
+title = {Mapping poverty using mobile phone and satellite data},
+journal = {Journal of The Royal Society Interface}
+}
+
+@book{plan-sat,
+author = {Commissariat général au développement durable – Direction de la recherche et de l’innovation},
+year = {2018},
+month = {07},
+pages = {},
+title = {Plan d’applications satellitaires 2018 - Des solutions spatiales pour connaître le territoire}
+}
+
+@article{ronneberger-15,
+author = {Olaf Ronneberger and
+ Philipp Fischer and
+ Thomas Brox},
+title = {U-Net: Convolutional Networks for Biomedical Image Segmentation},
+journal = {CoRR},
+volume = {abs/1505.04597},
+year = {2015},
+url = {http://arxiv.org/abs/1505.04597},
+eprinttype = {arXiv},
+eprint = {1505.04597},
+timestamp = {Mon, 13 Aug 2018 16:46:52 +0200},
+biburl = {https://dblp.org/rec/journals/corr/RonnebergerFB15.bib},
+bibsource = {dblp computer science bibliography, https://dblp.org}
+}
+
+@article{paliwal-20,
+author = {Shubham Paliwal and
+ Vishwanath D and
+ Rohit Rahul and
+ Monika Sharma and
+ Lovekesh Vig},
+title = {TableNet: Deep Learning model for end-to-end Table detection and Tabular
+ data extraction from Scanned Document Images},
+journal = {CoRR},
+volume = {abs/2001.01469},
+year = {2020},
+url = {http://arxiv.org/abs/2001.01469},
+eprinttype = {arXiv},
+eprint = {2001.01469},
+timestamp = {Thu, 14 Oct 2021 09:16:25 +0200},
+biburl = {https://dblp.org/rec/journals/corr/abs-2001-01469.bib},
+bibsource = {dblp computer science bibliography, https://dblp.org}
+}
+
+@article{beck2022,
+ title={Le multimode dans les enquêtes auprès des ménages : une collecte modernisée, un processus complexifié},
+ author={Beck, François and Castell, Laura and Legleye, Stéphane and Schreiber, Amandine},
+ journal={Courrier des statistiques},
+ year={2022}
+}
+
+
+@article{riviere2018,
+ title={Utiliser les déclarations administratives à des fins statistiques},
+ author={Rivière, Pascal},
+ journal={Courrier des statistiques},
+ year={2018}
+}
+
+@book{desrosieres2016politique,
+ title={La politique des grands nombres: histoire de la raison statistique},
+ author={Desrosi{\`e}res, Alain},
+ year={2010},
+ publisher={La d{\'e}couverte}
+}
+
+@article{desrosieres2004,
+ title={Enquêtes versus registres administratifs: réflexions sur la dualité des sources statistiques},
+ author={Desrosi{\`e}res, Alain},
+ journal={Courrier des statistiques},
+ year={2004}
+}
+
+@article{isnard2018,
+ title={Qu'entends-on par statistique(s) publique(s)},
+ author={Isnard, Michel},
+ journal={Courrier des statistiques},
+ year={2018}
+}
+
+@article{Humbert2018,
+ title={La déclaration sociale nominative: nouvelle référence pour les échanges de données sociales des entreprises vers les administrations},
+ author={Humbert-Bottin, Élisabeth},
+ journal={Courrier des statistiques},
+ year={2018}
+}
+
+@article{Renne2018,
+ title={Bien comprendre la déclaration sociale nominative pour mieux mesurer},
+ author={Renne, Catherine},
+ journal={Courrier des statistiques},
+ year={2018}
+}
+
+
+@article{galiana-20,
+title={Retour partiel des mouvements de population avec le d{\'e}confinement},
+author={Galiana, Lino and Suarez-Castillo, Milena and S{\'e}m{\'e}curbe, Fran{\c{c}}ois and Coudin, {\'E}lise and de Bellefon, Marie-Pierre},
+year={2020},
+publisher={Insee Analyses}
+}
+
+@article{galiana2020segregation,
+ title={Residential segregation, daytime segregation and spatial frictions: an analysis from mobile phone data },
+ author={Galiana, Lino and S{\'e}m{\'e}curbe, Fran{\c{c}}ois and Sakarovitch, Benjamin and Smoreda, Zbigniew},
+ year={2020},
+ publisher={Insee Working Paper}
+}
+
+@article{ricciato-20,
+title = {Towards a methodological framework for estimating present population density from mobile network operator data},
+journal = {Pervasive and Mobile Computing},
+volume = {68},
+pages = {101263},
+year = {2020},
+issn = {1574-1192},
+doi = {10.1016/j.pmcj.2020.101263},
+url = {https://www.sciencedirect.com/science/article/pii/S1574119220301097},
+author = {Fabio Ricciato and Giampaolo Lanzieri and Albrecht Wirthmann and Gerdy Seynaeve},
+keywords = {Mobile network operator data, Signalling data, Present population, Spatial density estimation, Experimental statistics},
+abstract = {The concept of present population is gaining increasing attention in official statistics. One possible approach to measure present population exploits data collected by Mobile Network Operators (MNO), from simple Call Detail Records (CDR) to more informative and complex signalling records. Such data, collected primarily for network operation processes, can be repurposed to infer patterns of human mobility. Two decades of research literature have produced several case studies, mostly focused on to CDR data, and a variety of ad-hoc methodologies tailored to specific datasets. Moving beyond the stage of explorative research, the regular production of official statistics across different MNO requires a more systematic approach to methodological development. Towards this aim, Eurostat and other members of the European Statistical System are working towards the definition of a general Reference Methodological Framework for processing MNO data for official statistics. In this contribution we report on the methodological aspects related to the estimation of present population density, for which we present a general and modular methodological structure that generalises previous proposals found in the academic literature. Along the way, we define a number of specific research problems requiring further attention by the research community. We stress the importance of comparing different methodological options at various points in the data workflow, e.g. in the geolocation of individual observations and in the inference method. Finally, we present illustrative results from a case-study based on real signalling data from a European operational network, complemented by numerical results from a simple simulation scenario.}
+}
+
+@article{feuillet-18,
+doi = {10.4000/cybergeo.29853},
+url = {https://doi.org/10.4000/cybergeo.29853},
+year = {2018},
+month = dec,
+publisher = {{OpenEdition}},
+author = {Vincent Loonis and Marie-Pierre de Bellefon},
+title = {Manuel d'analyse spatiale. Th{\'{e}}orie et mise en {\oe}uvre pratique avec R, Insee~M{\'{e}}thodes n{\textdegree}~131, Insee, Eurostat, 392~p.},
+journal = {Cybergeo}
+}
+
+@article{andre-21,
+title={Et pour quelques appartements de plus : {\'E}tude de la propri{\'e}t{\'e} immobili{\`e}re des m{\'e}nages et du profil redistributif de la taxe fonci{\`e}re},
+author={Mathias Andr{\'e} and Olivier Meslin},
+year={2021},
+publisher={Documents de travail, Insee}
+}
+
+@TechReport{cerdeiro-20,
+author={Mr. Diego A. Cerdeiro and Andras Komaromi and Yang Liu and Mamoon Saeed},
+title={{World Seaborne Trade in Real Time: A Proof of Concept for Building AIS-based Nowcasts from Scratch}},
+year=2020,
+month=May,
+institution={International Monetary Fund},
+type={IMF Working Papers},
+url={https://ideas.repec.org/p/imf/imfwpa/2020-057.html},
+number={2020/057},
+abstract={Maritime data from the Automatic Identification System (AIS) have emerged as a potential source for real time information on trade activity. However, no globally applicable end-to-end solution has been published to transform raw AIS messages into economically meaningful, policy-relevant indicators of international trade. Our paper proposes and tests a set of algorithms to fill this gap. We build indicators of world seaborne trade using raw data from the radio signals that the global vessel fleet emits for navigational safety purposes. We leverage different machine-learning techniques to identify port boundaries, construct port-to-port voyages, and estimate trade volumes at the world, bilateral and within-country levels. Our methodology achieves a good fit with official trade statistics for many countries and for the world in aggregate. We also show the usefulness of our approach for sectoral analyses of crude oil trade, and for event studies such as Hurricane Maria and the effect of measures taken to contain the spread of the novel coronavirus. Going forward, ongoing refinements of our algorithms, additional data on vessel characteristics, and country-specific knowledge should help improve the performance of our general approach for several country cases.},
+keywords={},
+doi={},
+}
+
+@unknown{imo-20,
+author = {International Maritime Organization},
+year = {2020},
+month = {06},
+pages = {},
+title = {IMO Fourth Greenhouse Gas Study 2020}
+}
+
+@article{brakel-17,
+author = {Brakel, Jan and Söhler, Emily and Daas, P.J.H. and Buelens, Bart},
+year = {2017},
+month = {12},
+pages = {},
+title = {Social media as a data source for official statistics; the Dutch Consumer Confidence Index},
+volume = {43},
+journal = {Survey methodology}
+}
+
+@ARTICLE{olteanu-19,
+AUTHOR={Olteanu, Alexandra and Castillo, Carlos and Diaz, Fernando and Kıcıman, Emre},
+TITLE={Social Data: Biases, Methodological Pitfalls, and Ethical Boundaries},
+JOURNAL={Frontiers in Big Data},
+VOLUME={2},
+YEAR={2019},
+URL={https://www.frontiersin.org/articles/10.3389/fdata.2019.00013},
+DOI={10.3389/fdata.2019.00013},
+ISSN={2624-909X},
+ABSTRACT={Social data in digital form—including user-generated content, expressed or implicit relations between people, and behavioral traces—are at the core of popular applications and platforms, driving the research agenda of many researchers. The promises of social data are many, including understanding “what the world thinks” about a social issue, brand, celebrity, or other entity, as well as enabling better decision-making in a variety of fields including public policy, healthcare, and economics. Many academics and practitioners have warned against the naïve usage of social data. There are biases and inaccuracies occurring at the source of the data, but also introduced during processing. There are methodological limitations and pitfalls, as well as ethical boundaries and unexpected consequences that are often overlooked. This paper recognizes the rigor with which these issues are addressed by different researchers varies across a wide range. We identify a variety of menaces in the practices around social data use, and organize them in a framework that helps to identify them.“For your own sanity, you have to remember that not all problems can be solved. Not all problems can be solved, but all problems can be illuminated.” –Ursula Franklin1}
+}
+
+@ARTICLE{schumacher-16,
+title = {A comparison of MIDAS and bridge equations},
+author = {Schumacher, Christian},
+year = {2016},
+journal = {International Journal of Forecasting},
+volume = {32},
+number = {2},
+pages = {257-270},
+abstract = {This paper compares two single-equation approaches from the recent nowcasting literature: mixed-data sampling (MIDAS) regressions and bridge equations. Both approaches are suitable for nowcasting low-frequency variables such as the quarterly GDP using higher-frequency business cycle indicators. Three differences between the approaches are identified: (1) MIDAS is a direct multi-step nowcasting tool, whereas bridge equations provide iterated forecasts; (2) the weighting of high-frequency predictor observations in MIDAS is based on functional lag polynomials, whereas the bridge equation weights are fixed partly by time aggregation; (3) for parameter estimation, the MIDAS equations consider current-quarter leads of high-frequency indicators, whereas bridge equations typically do not. To assist in discussing the differences between the approaches in isolation, intermediate specifications between MIDAS and bridge equations are provided. The alternative models are compared in an empirical application to nowcasting GDP growth in the Euro area, given a large set of business cycle indicators.},
+keywords = {Mixed-data sampling; Bridge equations; Nowcasting;},
+url = {https://EconPapers.repec.org/RePEc:eee:intfor:v:32:y:2016:i:2:p:257-270}
+}
+
+@inbook {stock-10,
+ title = {Dynamic Factor Models},
+ booktitle = {Oxford Handbook of Economic Forecasting},
+ year = {2010},
+ publisher = {Oxford University Press},
+ organization = {Oxford University Press},
+ address = {Oxford},
+ url = {http://www.economics.harvard.edu/faculty/stock/files/dfm_oup_4.pdf},
+ author = {James Stock and Mark Watson},
+ editor = {Michael P. Clements and David F. Henry}
+}
+
+@misc{hopp-21,
+ doi = {10.48550/ARXIV.2106.08901},
+ url = {https://arxiv.org/abs/2106.08901},
+ author = {Hopp, Daniel},
+ keywords = {Econometrics (econ.EM), Machine Learning (cs.LG), FOS: Economics and business, FOS: Economics and business, FOS: Computer and information sciences, FOS: Computer and information sciences},
+ title = {Economic Nowcasting with Long Short-Term Memory Artificial Neural Networks (LSTM)},
+ publisher = {arXiv},
+ year = {2021},
+ copyright = {Creative Commons Attribution 4.0 International}
+}
+
+@article{richardson-18,
+ author = {Richardson, Pete},
+ title = {Nowcasting and the Use of Big Data in Short Term Macroeconomic Forecasting: A Critical Review},
+ year = {2018},
+ url = {https://www.persee.fr/doc/estat_0336-1454_2018_num_505_1_10867},
+ note = {Included in a thematic issue : Big Data and Statistics (Part 1)},
+ journal = {Economie et Statistique},
+ volume = {505},
+ number = {1},
+ doi = {10.24187/ecostat.2018.505d.1966},
+ pages = {65--87}
+}
+
+@article{bortoli-18,
+ TITLE = {{Nowcasting GDP Growth by Reading Newspapers}},
+ AUTHOR = {Bortoli, Cl{\'e}ment and Combes, St{\'e}phanie and Renault, Thomas},
+ URL = {https://hal.archives-ouvertes.fr/hal-03205161},
+ JOURNAL = {{Economie et Statistique / Economics and Statistics}},
+ PUBLISHER = {{INSEE}},
+ SERIES = {Big Data and Statistics - Part 1},
+ NUMBER = {505-506},
+ PAGES = {17-33},
+ YEAR = {2018},
+ DOI = {10.24187/ecostat.2018.505d.1964},
+ KEYWORDS = {economic analysis ; nowcasting ; GDP ; media ; Big Data ; sentiment analysis ; machine learning ; natural language analysis},
+ HAL_ID = {hal-03205161},
+ HAL_VERSION = {v1},
+}
+
+@TechReport{fornaro-20,
+ author={Fornaro, Paolo},
+ title={{Nowcasting Industrial Production Using Uncoventional Data Sources}},
+ year=2020,
+ month=Jun,
+ institution={The Research Institute of the Finnish Economy},
+ type={ETLA Working Papers},
+ url={https://ideas.repec.org/p/rif/wpaper/80.html},
+ number={80},
+ abstract={ In this work, we rely on unconventional data sources to nowcast the year-on-year growth rate of Finnish industrial production, for different industries. As predictors, we use real-time truck traffic volumes measured automatically in different geographical locations around Finland, as well as electricity consumption data. In addition to standard time-series models, we look into the adoption of machine learning techniques to compute the predictions. We find that the use of non-typical data sources such as the volume of truck traffic is beneficial, in terms of predictive power, giving us substantial gains in nowcasting performance compared to an autoregressive model. Moreover, we find that the adoption of machine learning techniques improves substantially the accuracy of our predictions in comparison to standard linear models. While the average nowcasting errors we obtain are higher compared to the current revision errors of the official statistical institute, our nowcasts provide clear signals of the overall trend of the series and of sudden changes in growth.},
+ keywords={Flash Estimates; Machine Learning; Big Data; Nowcasting},
+ doi={},
+}
+
+@misc{salgado-20,
+ doi = {10.48550/ARXIV.2003.06797},
+ url = {https://arxiv.org/abs/2003.06797},
+ author = {Salgado, David and Oancea, Bogdan},
+ keywords = {Other Statistics (stat.OT), Applications (stat.AP), FOS: Computer and information sciences, FOS: Computer and information sciences, J.1; J.4; H.4, 62P25, 62P20},
+ title = {On new data sources for the production of official statistics},
+ publisher = {arXiv},
+ year = {2020},
+ copyright = {Creative Commons Attribution 4.0 International}
+}
+
+@book{hacking-90, place={Cambridge}, series={Ideas in Context}, title={The Taming of Chance}, DOI={10.1017/CBO9780511819766}, publisher={Cambridge University Press}, author={Hacking, Ian}, year={1990}, collection={Ideas in Context}}
\ No newline at end of file
diff --git a/series_temporelles.qmd b/series_temporelles.qmd
new file mode 100644
index 0000000..66a2884
--- /dev/null
+++ b/series_temporelles.qmd
@@ -0,0 +1,104 @@
+---
+title: "Nowcasting"
+---
+
+
+La statistique publique publiant des statistiques à intervalle régulier, une
+longue tradition de production et d'exploitation de séries temporelles
+précède les innovations récentes. La constance de la méthodologie, ou les
+harmonisations faites _a posteriori_ - par exemple la technique de la
+rétropolation en comptabilité nationale - assure en théorie
+une forme de comparabilité et permet de considérer
+les productions statistiques comme des séries temporelles.
+Parmi les productions statistiques dont la formalisation a été la plus
+précoce, la comptabilité nationale tient une bonne place. Le Système
+de Comptabilité Nationale (SCN) est ainsi un cadre international
+harmonisé qui permet la construction de séries temporelles depuis
+l'après-guerre. La France est l'un des pays pour lesquels il
+est possible de remonter le plus loin dans le passé avec des
+séries harmonisées depuis XXXX.
+
+En raison de délais imposés par la collecte et le traitement des données,
+certains indicateurs supposés donner des informations sur la situation actuelle sont publiés avec du retard et ne peuvent pas jouer leur rôle dans la prise de décision publique. C'est pourquoi la statistique publique participe aussi à la réalisation de prévisions à court terme de valeurs d'indicateurs macro-économiques.
+Si la production de séries statistiques récurrentes fait partie
+des missions de tous les instituts statistiques, l'Insee a également
+des missions plus spécifiques dans le domaine des séries temporelles.
+La construction d'indicateurs conjoncturels prospectifs, au
+service du débat public et de la prise de décision politique, en fait partie.
+A l'Insee cette mission prospective est assurée par le département de la
+conjoncture qui construit des indicateurs et des analyses prospectifs
+sur l'activité économiques des prochains trimestres.
+Ce département
+mobilise historiquement des données dont la remontée est plus rapide que celles
+utilisées pour la construction des agrégats macroéconomiques de la
+comptabilité nationale.
+Cependant, la collecte accrue de traces numériques a permis l'accès à
+des données à haute fréquence pouvant être mobilisées
+pour disposer de signaux sur la situation macroéconomique actuelle ou
+très récente.
+
+
+Dans ce cadre, l'`Insee`, `QuantCube`[^1], Paris School of Economics[^2], `CANDRIAM` et la Société Générale ont créé une Chaire de recherche **Mesures de l'économie, nowcasting ‐ au‐delà du PIB** en 2021. Cette Chaire a pour objectif de travailler sur l'amélioration des prévisions économiques, en particulier grâce à la mobilisation de nouvelles sources de données. Parmi ces nouvelles sources, on trouve les actualités [@bortoli-18], les médias sociaux, les données satellitaires, les réseaux professionnels et les avis de consommateurs, ainsi que les données sur le commerce international, la consommation d'électricité et le transport routier [@fornaro-20], le transport maritime, l'immobilier, l'hôtellerie et les télécommunications.
+Un autre objectif de la Chaire est de travailler sur la mesure de nouveaux indicateurs économiques, de bien-être ou de développement durable (**au‐delà du PIB**),
+ici encore en utilisant ces données nouvelles.
+
+[^1]: Start‐up proposant des prévisions macroéconomiques fondées sur le Big Data et l'intelligence artificielle
+[^2]: société internationale de gestion d'actifs
+
+Côté technique, des modèles autorégressifs de type *bridge models* ou *mixed-data sampling* [@schumacher-16], des *dynamic factor models* [@stock-10] ou plus récemment des modèles de Deep Learning de type LSTM [@hopp-21] sont souvent utilisés pour combiner des indicateurs de type *soft* comme le climat des affaires ou le sentiment des consommateurs avec des indicateurs *hard* comme la production industrielle, le commerce de détail, les prix de l’immobilier, etc. à différentes fréquences. La littérature fait particulièrement état de l'utilisation de deux sources de données massive permettant d'obtenir des indicateurs *soft* [@richardson-18], même si bien d'autres sources ont été expertisées :
+
+‑ les statistiques de recherches sur Internet basées sur la fréquence de recherche de mots‑clés ou de sujets spécifiques ;
+‑ les médias sociaux sur Internet (Twitter).
+
+# Statistiques de recherches sur Internet
+
+L'idée derrière l'utilisation de ces données est la suivante : les recherches sur Internet sont devenues un moyen répandu pour les agents économiques d’obtenir des informations pertinentes sur leur situation et leurs décisions économiques immédiates. Ainsi, les événements courants
+se reflètent dans le comportement de recherche et peuvent être corrélés à des statistiques macro-économiques. `Google` a mis en place des services permettant l'accès à des statistiques sur les recherches effectuées via son moteur de recherche : [`Google Trends`](https://trends.google.fr/trends/).
+
+L'apport de données de Google Trends dans le cadre de prédictions économiques a été évaluée concernant le marché du travail et le chômage, la consommation, le marché du logement, le tourisme et les anticipations d’inflation, ainsi que d'autres études macro-économiques [@givordblanchet].
+Dans la plupart des cas, les auteurs constatent une amélioration de la précision prédictive mais cette dernière est souvent assez limitée et n'est pas toujours robuste.
+
+# Données de réseaux sociaux
+
+Les données de réseaux sociaux (en particulier `Twitter`) ont déjà
+été évoquées du fait de leur dimension
+géographique ou textuelle. Elles
+présentent également un aspect temporel.
+Les données de réseaux sociaux ont
+des avantages par rapport aux données de recherches sur Internet :
+
+- ces données sont beaucoup plus riches, avec beaucoup d'information associée à chaque observation (contenu textuel du tweet, informations sur l'utilisateur, etc.) ;
+- ces données permettent une approche stratifiée, en utilisant les informations de groupes d’utilisateurs bien définis ;
+- l’absence de préparation par les propriétaires des données (comme c'est le cas pour Google Trends), qui peut en réalité constituer un avantage ou un inconvénient.
+
+Des données issues de `Twitter` ont été testées dans des études de prévisions du comportement des marchés financiers et du marché du travail (utililsation d'indicateurs dérivés de la fréquence d'utilisation des termes de perte et de recherche d'emploi dans des échantillons de tweets) entre autres.
+
+Comme pour les données de Google Trends, les résultats sont mitigés,
+ce qui est naturel si on réfléchit aux biais qui limitent le potentiel de ces données.
+Tout d'abord, pour pouvoir récupérer les tweets pertinents concernant un certain sujet,
+il est nécessaire de mettre au point des bonnes méthodes de recherche sur de grands ensembles d’entrées.
+On constate d'ailleurs une forte sensibilité aux choix des mots-clés ou en général à la spécification de la recherche. Les jeux de données récupérés sont sujets à un fort biais de sélection : les utilisateurs de Twitter qui communiquent sur un sujet ne sont pas représentatifs de la population générale. Il faut en outre pouvoir correctement interpréter le contenu des textes, ce qui représente en général une tâche difficile
+(les progrès récents en NLP ont permis des fortes avancées sur ce point).
+
+# Le *nowcasting* à l'Insee
+
+L'Insee a travaillé de manière particulièrement intensive
+sur le *nowcasting* au cours de la crise sanitaire liée au Covid-19,
+moment auquel le travail des conjoncturistes de l'Insee
+a été réorienté pour mesurer au mieux,
+à chaque instant, la chute de l'activité économique.
+
+Pour réaliser cette évaluation, l'Insee a recueilli de l'information de la part d'entreprises ou de branches professionnelles, directement ou via des partenaires (par exemple la Banque de France ou des instituts de conjoncture).
+Cette information a été traitée, secteur par secteur, pour donner un ordre de grandeur de perte d'activité à hauteur d'un tiers du PIB.
+Pour consolider ce résultat, il a été choisi d'exploiter d'autres sources de données disponibles à haute fréquence. Ont été envisagées mais écartées plusieurs pistes : consommation d'électricité, indicateurs de pollution, Google Trends, vocabulaire utilisé dans la presse, etc.
+Finalement, des statistiques issues des transactions par cartes bancaires fournies par le Groupement des Cartes Bancaires CB[^3], ont été privilégiées.
+
+[^3]: Dans le domaine de la monétique, le Groupement des cartes bancaires est un groupement d'intérêt économique privé qui réunit la plupart des établissements financiers français dans le but d'assurer l'interbancarité des cartes de paiement.
+
+Ces données ont permis, très tôt dans le confinement,
+de confirmer l'ordre de grandeur d'une chute d'un tiers pour la consommation.
+Le 26 mars, l'Insee publie donc une estimation de chute de PIB (en instantané par rapport à un régime normal) de 35 % et de chute de la consommation des ménages du même ordre de grandeur. Cet ordre de grandeur s'est révélé assez fiable. Il a été confirmé par deux mises à jour ultérieures et par des évaluations de la Banque de France et des instituts de conjoncture nationaux.
+
+Des données de téléphonie mobile à haute fréquence ont également été utilisées pour mesurer les déplacements de populations au moment des confinement et déconfinement
+[@galiana-20]. Plus d'éléments sont présentés à ce propos
+dans le chapitre sur les données géolocalisées.
diff --git a/styles.css b/styles.css
new file mode 100644
index 0000000..2ddf50c
--- /dev/null
+++ b/styles.css
@@ -0,0 +1 @@
+/* css styles */
diff --git a/textes.qmd b/textes.qmd
new file mode 100644
index 0000000..9278ca4
--- /dev/null
+++ b/textes.qmd
@@ -0,0 +1,344 @@
+---
+title: "Données textuelles et non structurées"
+---
+
+Les données textuelles sont aujourd'hui parmi les types de données les
+plus prometteurs pour la statistique publique
+et l'un des champs les plus actifs de la recherche
+en _data science_.
+Pour cause, de plus en plus de services existent
+sur le _web_ qui conduisent à la collecte de données textuelles. En outre,
+des nouvelles méthodes pour collecter et traiter ces
+traces numériques particulières ont été développées dans les
+dernières années.
+
+Une partie des méthodes d'analyse qui appartiennent
+à la palette des compétences des _data scientists_
+spécialistes du traitement de données textuelles sont en réalité assez
+anciennes.
+Par exemple, la [distance de Levensthein](https://en.wikipedia.org/wiki/Levenshtein_distance)
+a été proposée
+pour la première fois en 1965, l'ancêtre des réseaux
+de neurone actuels est le perceptron qui date de 1957, etc.[^1]
+Néanmoins, le fait que certaines entreprises du net
+basent leur _business model_ sur le traitement
+et la valorisation de la donnée
+textuelle, notamment Google, Facebook et Twitter, a amené
+à renouveler le domaine.
+
+[^1]: Pour remonter plus loin dans la ligne du temps des
+données textuelles, on peut penser
+au [`Soundex`](https://en.wikipedia.org/wiki/Soundex),
+un algorithme d'indexation des textes dans
+les annuaires dont l'objectif était de permettre
+de classer à la suite des noms qui ne déviaient que
+par une différence typographique et non sonore.
+
+La statistique publique s'appuie également sur la collecte
+et le traitement de données textuelles. Les collectes
+de données officielles ne demandent pas exclusivement
+d'informations sous le forme de texte. Les premières informations
+demandées sont généralement un état civil, une adresse, etc.
+C'est ensuite, en fonction du thème de l'enquête, que d'autres
+informations textuelles seront collectées: un nom
+d'entreprise, un titre de profession, etc. Les données
+administratives elles-aussi comportent souvent des informations
+textuelles. Ces données défient l'analyse statistique car
+cette dernière, qui vise à détecter des grandes structures
+à partir d'observations multiples, doit s'adapter à la différence
+des données textuelles: le langage est un champ où
+certaines des notions usuelles de la statistique (distance, similarité notamment)
+doivent être revues.
+
+Ce chapitre propose un panorama très incomplet de l'apport
+des données non structurées, principalement textuelles,
+pour la statistique et l'analyse de données. Nous évoquerons
+plusieurs sources ou méthodes de collecte. Nous ferons
+quelques détours par des exemples pour aller plus
+loin.
+
+# Webscraping
+
+## Présentation
+
+Le [webscraping](https://fr.wikipedia.org/wiki/Web_scraping) est une méthode de collecte de données qui repose
+sur le moissonnage d'objets de grande dimension (des pages web)
+afin d'en extraire des informations ponctuelles (du texte, des nombres...). Elle désigne les techniques d'extraction du contenu des sites Internet. C'est une pratique très utile pour toute personne souhaitant travailler sur des informations disponibles en ligne, mais n'existant pas forcément sous la forme de fichiers exportables.
+
+## Enjeux pour la statistique publique
+
+Le *webscraping* présente un certain nombre d'enjeux en termes de légalité, qui ne seront pas enseignés dans ce cours. En particulier, la Commission nationale de l'informatique et des libertés (CNIL) a publié en 2020 de nouvelles directives sur le *webscraping* reprécisant qu'aucune donnée ne peut être réutilisée à l'insu de la personne à laquelle elle appartient.
+
+Le *webscraping* est un domaine où la reproductibilité est compliquée à mettre en oeuvre. Une page *web* évolue
+régulièrement et d'une page web à l'autre, la structure peut
+être très différente ce qui rend certains codes difficilement généralisables.
+Par conséquent, la meilleure manière d'avoir un programme fonctionnel est
+de comprendre la structure d'une page web et dissocier les éléments exportables
+à d'autres cas d'usages des requêtes *ad hoc*.
+
+Un code qui fonctionne aujourd'hui peut ainsi très bien ne plus fonctionner
+au bout de quelques semaines. Il apparaît
+préférable de privilégier les API
+qui sont un accès en apparence plus compliqué mais en fait plus fiable à moyen terme.
+Cette difficulté à construire une extraction de données pérenne par
+_webscraping_ une illustration du principe _"there is no free lunch"_.
+La donnée est au cœur du business model de nombreux acteurs, il est donc logique qu'ils essaient de restreindre la moisson de leurs données.
+
+Les APIs sont un mode d'accès de plus en plus généralisé à des données.
+Cela permet un lien direct entre fournisseurs et utilisateurs de données,
+un peu sous la forme d'un contrat. Si les données sont ouvertes avec restrictions, on utilise des clés d'authentification.
+Avec les API, on structure sa demande de données sous forme de requête paramétrée (source désirée, nombre de lignes, champs...)
+et le fournisseur de données y répond, généralement sous la forme d'un résultat au format `JSON`.
+`Python` et `JavaScript` sont deux outils très populaires pour récupérer de la donnée
+selon cette méthode.
+Pour plus de détails, vous pouvez explorer le
+[chapitre sur les API dans le cours de `Python` de l'ENSAE](https://pythonds.linogaliana.fr/api/).
+
+On n'est pas à l'abri de mauvaises surprises avec les
+APIs (indisponibilité, limite atteinte de requêtes...)
+mais cela permet un lien plus direct avec la dernière donnée publiée par un producteur.
+L'avantage de l'API est qu'il s'agit d'un service du fournisseur de données, qui en tant
+que service va amener un producteur à essayer de répondre à une
+demande dans la mesure du possible.
+Le _webscraping_ étant un mode d'accès à la donnée plus opportuniste,
+où le réel objectif du producteur de données n'est pas de fournir de la
+donnée mais une page _web_, il n'y a aucune garantie de service ou
+de continuité.
+
+
+## Exemples dans la statistique publique
+
+
+
+## Implémentations
+
+`Python` est le langage le plus utilisé
+par les _scrappers_.
+`BeautifulSoup` sera suffisant quand vous voudrez travailler sur des pages HTML statiques. Dès que les informations que vous recherchez sont générées via l'exécution de scripts [`Javascript`](https://fr.wikipedia.org/wiki/JavaScript), il vous faudra passer par des outils comme [`Selenium`](https://selenium-python.readthedocs.io/).
+De même, si vous ne connaissez pas l'URL, il faudra passer par un framework comme [`Scrapy`](https://scrapy.org/), qui passe facilement d'une page à une autre ("crawl"). Scrapy est plus complexe à manipuler que `BeautifulSoup` : si vous voulez plus de détails, rendez-vous sur la page du [tutoriel `Scrapy`](https://doc.scrapy.org/en/latest/intro/tutorial.html).
+Pour plus de détails, voir le [TP sur le webscraping en 2e année de l'ENSAE](https://pythonds.linogaliana.fr/webscraping/).
+
+Les utilisateurs de `R` privilégieront `httr` and `rvest` qui sont les packages les plus
+utilisés.
+Il est intéressant d'accorder de l'attention à
+[`polite`](https://github.com/dmi3kno/polite). Ce package vise à récupérer
+des données en suivant les [recommandations de bonnes pratiques](https://towardsdatascience.com/ethics-in-web-scraping-b96b18136f01) sur
+le sujet, notamment de respecter les instructions dans
+`robots.txt` (_"The three pillars of a polite session are seeking permission, taking slowly and never asking twice"_).
+
+# Réseaux sociaux
+
+Les réseaux sociaux sont l'une des sources textuelles
+les plus
+communes. C'est leur usage à des fins commerciales
+qui a amené les entreprises du net à renouveler
+le champ de l'analyse textuelles qui bénéficie
+au-delà de leur champ d'origine.
+
+On rentre un peu plus en détail sur ces données dans le chapitre **Nowcasting**.
+
+# Les modèles de langage
+
+Un modèle de langage est un modèle statistique qui modélise la distribution de séquences de mots, plus généralement de séquences de symboles discrets (lettres, phonèmes, mots), dans une langue naturelle. Un des objectifs de ces modèles est
+de pouvoir transformer des objets (textes) situés dans un espace d'origine de très grande dimension, qui de plus
+utilise des éléments contextuels, en informations situés dans un espace de dimension réduite. Il s'agit ainsi de transformer des éléments d'un corpus,
+par exemple des mots, en vecteurs multidimensionnels sur lequel on peut
+ensuite par exemple appliquer des opérations arithmétiques.
+Un modèle de langage peut par exemple servir à prédire le mot suivant une séquence de mots
+ou la similarité de sens entre deux phrases.
+
+## Du bag of words aux modèles de langage
+
+L'objectif du _Natural Langage Processing_ (NLP)
+est de transformer une information de très haute
+dimension (une langue est un objet éminemment complexe)
+en information à dimension plus limitée qui peut
+être exploitée par un ordinateur.
+
+La première approche pour entrer dans l'analyse d'un
+texte est généralement l'approche bag of words ou topic modeling.
+Dans la première, il s'agit
+de formaliser un texte sous forme d'un ensemble de mots
+où on va piocher plus ou moins fréquemment dans un sac de
+mots possibles.
+Dans la seconde, il s'agit de modéliser le processus de choix
+de mots en deux étapes (modèle de mélange): d'abord un choix
+de thème puis, au sein de ce thème, un choix de mots plus ou
+moins fréquents selon le thème.
+
+Dans ces deux approches, l'objet central est la matrice document-terme.
+Elle formalise les fréquences d'occurrence de mots dans des textes ou
+des thèmes. Néanmoins, il s'agit d'une matrice très creuse: même
+un texte au vocabulaire très riche n'explore qu'une petite partie
+du dictionnaire des mots possibles.
+
+L’idée derrière les _embeddings_ est de proposer une information plus
+condensée qui permet néanmoins de capturer les grandes structures
+d'un texte. Il s'agit par exemple de résumer l'ensemble
+d'un corpus en un nombre relativement restreint de dimensions. Ces
+dimensions ne sont pas prédéterminées mais plutôt inférées
+par un modèle qui essaie de trouver la meilleure partition
+des dimensions pour rapprocher les termes équivalents.
+Chacune de ces dimensions va représenter un facteur latent, c’est à dire une variable inobservée, de la même manière que les composantes principales produites par une ACP.
+Techniquement,
+au lieu de représenter les documents par des vecteurs sparse de très grande dimension (la taille du vocabulaire) comme on l’a fait jusqu’à présent, on va les représenter par des vecteurs denses (continus) de dimension réduite (en général, autour de 100-300).
+
+## Intérêt des modèles de langage
+
+Par exemple, un humain sait qu'un document contenant le mot _"Roi"_
+et un autre document contenant le mot _"Reine"_ ont beaucoup de chance
+d'aborder des sujets semblables.
+
+::: {#fig-word2vec}
+
+
+Schéma illustratif de `word2vec`.
+:::
+
+Pourtant, une vectorisation de type comptage ou TF-IDF
+ne permet pas de saisir cette similarité :
+le calcul d'une mesure de similarité (norme euclidienne ou similarité cosinus)
+entre les deux vecteurs donnera une valeur très faible, puisque les mots utilisés sont différents.
+
+A l'inverse, un modèle `word2vec` (voir @fig-word2vec) bien entraîné va capter
+qu'il existe un facteur latent de type _"royauté"_,
+et la similarité entre les vecteurs associés aux deux mots sera forte.
+
+La magie va même plus loin : le modèle captera aussi qu'il existe un
+facteur latent de type _"genre"_,
+et va permettre de construire un espace sémantique dans lequel les
+relations arithmétiques entre vecteurs ont du sens ;
+par exemple (voir @fig-embeddings) :
+
+$$\text{king} - \text{man} + \text{woman} ≈ \text{queen}$$
+
+Chaque mot est représenté par un vecteur de taille fixe (comprenant $n$ nombres),
+de façon à ce que deux mots dont le sens est proche possèdent des représentations numériques proches. Ainsi les mots « chat » et « chaton » devraient avoir des vecteurs de plongement assez similaires, eux-mêmes également assez proches de celui du mot « chien » et plus éloignés de la représentation du mot « maison ».
+
+_Comment ces modèles sont-ils entraînés ?_
+Via une tâche de prédiction résolue par un réseau de neurones simple.
+L'idée fondamentale est que la signification d'un mot se comprend
+en regardant les mots qui apparaissent fréquemment dans son voisinage.
+Pour un mot donné, on va donc essayer de prédire les mots
+qui apparaissent dans une fenêtre autour du mot cible.
+
+En répétant cette tâche de nombreuses fois et sur un corpus suffisamment varié,
+on obtient finalement des *embeddings* pour chaque mot du vocabulaire,
+qui présentent les propriétés discutées précédemment.
+
+::: {#fig-embeddings}
+{ width=70% }
+
+Illustration des *word embeddings*.
+:::
+
+## Les modèles de langage aujourd'hui
+
+La méthode de construction d’un plongement lexical présentée ci-dessus est celle de l’algorithme [`Word2Vec`](https://fr.wikipedia.org/wiki/Word2vec).
+Il s’agit d’un modèle _open-source_ développé par une équipe de `Google` en 2013.
+`Word2Vec` a été le pionnier en termes de modèles de plongement lexical.
+
+Le modèle [`GloVe`](https://nlp.stanford.edu/projects/glove/) constitue un autre exemple [@pennington2014glove]. Développé en 2014 à Stanford,
+ce modèle ne repose pas sur des réseaux de neurones mais sur la construction d’une grande matrice de co-occurrences de mots. Pour chaque mot, il s’agit de calculer les fréquences d’apparition des autres mots dans une fenêtre de taille fixe autour de lui. La matrice de co-occurrences obtenue est ensuite factorisée par une décomposition en valeurs singulières.
+Il est également possible de produire des plongements de mots à partir du [modèle de langage `BERT`](https://jalammar.github.io/illustrated-bert/), développé par `Google` en 2019, dont il existe des déclinaisons dans différentes langues, notamment en Français (les
+modèles [`CamemBERT`](https://camembert-model.fr/) ou [`FlauBERT`](https://github.com/getalp/Flaubert)).
+
+Enfin, le modèle [`FastText`](https://fasttext.cc/), développé en 2016 par une équipe de `Facebook`, fonctionne de façon similaire à `Word2Vec` mais se distingue particulièrement sur deux points :
+
+* En plus des mots eux-mêmes, le modèle apprend des représentations pour les n-grams de caractères (sous-séquences de caractères de taille \\(n\\), par exemple _« tar »_, _« art »_ et _« rte »_ sont les trigrammes du mot _« tarte »_), ce qui le rend notamment robuste aux variations d’orthographe ;
+* Le modèle a été optimisé pour que son entraînement soit particulièrement rapide.
+
+Le modèle `GPT-3` (acronyme de Generative Pre-trained Transformer 3)
+a aujourd'hui le vent en poupe. Celui-ci
+a été développé par la société `OpenAI` et rendu
+public en 2020 [@brown2020language].
+GPT-3 est le plus gros modèle de langage jamais entraîné avec 175 milliards de paramètres. Il sert de brique de base à plusieurs applications
+utilisant l'analyse textuelle pour synthétiser, à partir d'une
+instruction, des éléments importants et
+proposer un texte cohérent. `Github Copilot` l'utilise pour transformer
+une instruction en proposition de code, à partir d'un grand
+corpus de code open source. `Algolia` l'utilise pour transformer une
+instruction en mots clés de recherche afin d'améliorer
+la pertinence des résultats.
+
+En ce moment, le champ du _prompt engineering_ est en effervescence.
+Les modèles de langage comme GPT-3 permettent en effet d'extraire
+les éléments qui permettent de mieux discriminer les thèmes
+d'un texte.
+
+
+## Utilisation dans un processus de créatoin de contenu créatif
+
+La publication par l'organisation [Open AI](https://openai.com/) de
+son modèle de génération de contenu créatif [Dall-E-2](https://openai.com/dall-e-2/)
+(un jeu de mot mélangeant Dali et Wall-E) a créé un bruit inédit dans
+le monde de la _data-science_.
+Un compte Twitter ([Weird Dall-E Mini Generations](https://twitter.com/weirddalle))
+propose de nombreuses générations de contenu drôles ou incongrues.
+Le bloggeur tech Casey Newton a pu parler d'une
+[révolution créative dans le monde de l'IA](https://www.platformer.news/p/how-dall-e-could-power-a-creative).
+
+
+La @fig-shiba montre un exemple d'image générée par DALL-E-2.
+
+::: {#fig-shiba}
+{ width=70% }
+
+_"A Shiba Inu dog wearing a beret and black turtleneck"_
+:::
+
+Les modèles générateurs d'image
+`DallE` et `Stable Diffusion` peuvent, schématiquement,
+être décomposés en deux niveaux de réseaux de neurones:
+
+- le contenu de la phrase est analysé par un modèle de langage comme `GPT-3` ;
+- les éléments importants de la phrase (recontextualisés) sont ensuite transformés en image à partir de
+modèles entraînés à reconnaître des images.
+
+{ fig-align="center" }
+
+`Stable Diffusion` est une version plus accessible que `DALL-E` pour les
+utilisateurs de `Python`.
+
+{ fig-align="center" }
+
+Si vous êtes intéressés par ce type de modèle, vous pouvez
+[tester les exemples du cours de Python de l'ENSAE](https://pythonds.linogaliana.fr/dalle/). Vous pouvez tester
+__"Chuck Norris fighting against Zeus on Mount Olympus in an epic Mortal Kombat scene"__
+pour générer une image comme celle-ci dessous ou chercher à obtenir
+l'image de votre choix:
+
+{ fig-align="center" }
+
+# Modèles de langage dans la statistique publique
+
+L'analyse textuelle dans la statistique publique intervient
+principalement à deux niveaux:
+
+- pour apparier des sources à partir de champs textuels qui
+ne sont pas nécessairement identiques ;
+- pour catégoriser des données dans une nomenclature normalisée
+à partir de champs libres.
+
+## Catégorisation
+
+A `l’Insee`, plusieurs modèles de classification de libellés textuels dans des nomenclatures reposent sur l’algorithme de plongement lexical [`FastText`](https://fasttext.cc/).
+Les derniers mis en oeuvre sont les suivants:
+
+1. catégorisation des professions dans la nomenclature des PCS ;
+2. catégorisation des entreprises dans la nomenclature d'activité APE ;
+3. catégorisation des produits dans la nomenclature des COICOP.
+
+Les deux premiers devraient servir prochainement à la production de statistiques
+officielles. Le troisième est une expérimentation encore en cours.
+
+## Appariements
+
+{ fig-align="center" width=80% }
+
+# Conclusion
+
+# References
+
+::: {#refs}
+:::
diff --git a/textes_exemples.qmd b/textes_exemples.qmd
new file mode 100644
index 0000000..de9b18a
--- /dev/null
+++ b/textes_exemples.qmd
@@ -0,0 +1,15 @@
+---
+title: "Application"
+---
+
+L'objectif de ce TP est d'explorer les aspects suivants du traitement
+du langage naturel:
+
+- _Preprocessing_
+- `ElasticSearch`: indexation et requêtage
+
+Il est disponible sur [cette page](https://pythonds.linogaliana.fr/elastic/) en version _web_
+et peut être ouvert sur l'environnement
+`SSPCloud` où `ElasticSearch` est disponible en cliquant sur le bouton suivant:
+
+
\ No newline at end of file
diff --git a/workflows/prod.yml b/workflows/prod.yml
new file mode 100644
index 0000000..12ba105
--- /dev/null
+++ b/workflows/prod.yml
@@ -0,0 +1,45 @@
+on:
+ push:
+ branches: master
+
+name: Render and Publish
+
+jobs:
+ build-deploy:
+ runs-on: ubuntu-latest
+ steps:
+ - name: Check out repository
+ uses: actions/checkout@v3
+
+ - name: Set up Quarto
+ uses: quarto-dev/quarto-actions/setup@v2
+ with:
+ # To install LaTeX to build PDF book
+ tinytex: true
+ # uncomment below and fill to pin a version
+ # version: 0.9.600
+
+ # add software dependencies here
+
+ # To publish to Netlify, RStudio Connect, or GitHub Pages, uncomment
+ # the appropriate block below
+
+ # - name: Publish to Netlify (and render)
+ # uses: quarto-dev/quarto-actions/publish@v2
+ # with:
+ # target: netlify
+ # NETLIFY_AUTH_TOKEN: ${{ secrets.NETLIFY_AUTH_TOKEN }}
+
+ # - name: Publish to RStudio Connect (and render)
+ # uses: quarto-dev/quarto-actions/publish@v2
+ # with:
+ # target: connect
+ # CONNECT_SERVER: enter-the-server-url-here
+ # CONNECT_API_KEY: ${{ secrets.CONNECT_API_KEY }}
+
+ - name: Publish to GitHub Pages (and render)
+ uses: quarto-dev/quarto-actions/publish@v2
+ with:
+ target: gh-pages
+ env:
+ GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} # this secret is always available for github actions
diff --git a/workflows/test.yml b/workflows/test.yml
new file mode 100644
index 0000000..f3df192
--- /dev/null
+++ b/workflows/test.yml
@@ -0,0 +1,60 @@
+on:
+ pull_request:
+ branches: master
+
+name: Render and Publish
+
+jobs:
+ build-deploy:
+ runs-on: ubuntu-latest
+ steps:
+ - name: Check out repository
+ uses: actions/checkout@v3
+
+ - name: Set up Quarto
+ uses: quarto-dev/quarto-actions/setup@v2
+ with:
+ # To install LaTeX to build PDF book
+ tinytex: true
+ # uncomment below and fill to pin a version
+ # version: 0.9.600
+
+ # add software dependencies here
+
+ # To publish to Netlify, RStudio Connect, or GitHub Pages, uncomment
+ # the appropriate block below
+
+ - name: Render
+ uses: quarto-dev/quarto-actions/render@v2
+
+ - name: Install npm
+ uses: actions/setup-node@v2
+ with:
+ node-version: '14'
+
+ # - name: Deploy to Netlify
+ # # NETLIFY_AUTH_TOKEN and NETLIFY_SITE_ID added in the repo's secrets
+ # env:
+ # NETLIFY_AUTH_TOKEN: ${{ secrets.NETLIFY_AUTH_TOKEN }}
+ # NETLIFY_SITE_ID: ${{ secrets.NETLIFY_SITE_ID }}
+ # BRANCHE_REF: ${{ github.event.pull_request.head.ref }}
+ # run: |
+ # npm init -y
+ # npm install --unsafe-perm=true netlify-cli -g
+ # netlify init
+ # netlify deploy --alias=${BRANCHE_REF} --dir="_site" --message "Preview deploy"
+
+ # - name: Publish to RStudio Connect (and render)
+ # uses: quarto-dev/quarto-actions/publish@v2
+ # with:
+ # target: connect
+ # CONNECT_SERVER: enter-the-server-url-here
+ # CONNECT_API_KEY: ${{ secrets.CONNECT_API_KEY }}
+
+ - name: Publish to GitHub Pages (and render)
+ uses: quarto-dev/quarto-actions/publish@v2
+ with:
+ target: gh-pages
+ env:
+ GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} # this secret is always available for github actions
+
+
+Le notebook `classification_oiseau.ipynb` traite un problème simple de classification d'image, à regarder dans un premier temps. Le notebook `donnees_satellite.ipynb` traite ensuite un problème de segmentation sémantique sur des images satellitaires, qui permet d'obtenir des cartes de couverture du territoire pouvant être utilisées pour produire des statistiques officielles.
+
+Un second bouton si l'installation de `Pytorch` est trop longue:
+
+
diff --git a/img/geolocalized_data/carte_densite.png b/img/geolocalized_data/carte_densite.png
new file mode 100644
index 0000000..3fcfe50
Binary files /dev/null and b/img/geolocalized_data/carte_densite.png differ
diff --git a/img/geolocalized_data/confinement-deconfinement.png b/img/geolocalized_data/confinement-deconfinement.png
new file mode 100644
index 0000000..bd38f18
Binary files /dev/null and b/img/geolocalized_data/confinement-deconfinement.png differ
diff --git a/img/images/bike.jpg b/img/images/bike.jpg
new file mode 100644
index 0000000..d401a4f
Binary files /dev/null and b/img/images/bike.jpg differ
diff --git a/img/images/bike_sobel.jpg b/img/images/bike_sobel.jpg
new file mode 100644
index 0000000..e15cc2b
Binary files /dev/null and b/img/images/bike_sobel.jpg differ
diff --git a/img/images/column_mask.png b/img/images/column_mask.png
new file mode 100644
index 0000000..4889f32
Binary files /dev/null and b/img/images/column_mask.png differ
diff --git a/img/images/convol.png b/img/images/convol.png
new file mode 100644
index 0000000..c1e3d1f
Binary files /dev/null and b/img/images/convol.png differ
diff --git a/img/images/detection_arbre.png b/img/images/detection_arbre.png
new file mode 100644
index 0000000..87c2f95
Binary files /dev/null and b/img/images/detection_arbre.png differ
diff --git a/img/images/dsn-diff.png b/img/images/dsn-diff.png
new file mode 100644
index 0000000..2949d0f
Binary files /dev/null and b/img/images/dsn-diff.png differ
diff --git a/img/images/dsn-schema.png b/img/images/dsn-schema.png
new file mode 100644
index 0000000..7a46683
Binary files /dev/null and b/img/images/dsn-schema.png differ
diff --git a/img/images/filiales_ex.png b/img/images/filiales_ex.png
new file mode 100644
index 0000000..0be3246
Binary files /dev/null and b/img/images/filiales_ex.png differ
diff --git a/img/images/image_satellite.png b/img/images/image_satellite.png
new file mode 100644
index 0000000..1c417cc
Binary files /dev/null and b/img/images/image_satellite.png differ
diff --git a/img/images/image_segmentation_input.jpeg b/img/images/image_segmentation_input.jpeg
new file mode 100644
index 0000000..2d981e4
Binary files /dev/null and b/img/images/image_segmentation_input.jpeg differ
diff --git a/img/images/image_segmentation_output.png b/img/images/image_segmentation_output.png
new file mode 100644
index 0000000..71ec57b
Binary files /dev/null and b/img/images/image_segmentation_output.png differ
diff --git a/img/images/predicted_segmentation.png b/img/images/predicted_segmentation.png
new file mode 100644
index 0000000..8cb1566
Binary files /dev/null and b/img/images/predicted_segmentation.png differ
diff --git a/img/images/python_blue.png b/img/images/python_blue.png
new file mode 100644
index 0000000..1c9592b
Binary files /dev/null and b/img/images/python_blue.png differ
diff --git a/img/images/python_green.png b/img/images/python_green.png
new file mode 100644
index 0000000..9dbcf25
Binary files /dev/null and b/img/images/python_green.png differ
diff --git a/img/images/python_pixels.png b/img/images/python_pixels.png
new file mode 100644
index 0000000..1e213ec
Binary files /dev/null and b/img/images/python_pixels.png differ
diff --git a/img/images/python_red.png b/img/images/python_red.png
new file mode 100644
index 0000000..9ff3a83
Binary files /dev/null and b/img/images/python_red.png differ
diff --git a/img/images/real_segmentation.png b/img/images/real_segmentation.png
new file mode 100644
index 0000000..bd383db
Binary files /dev/null and b/img/images/real_segmentation.png differ
diff --git a/img/images/rgb_image.png b/img/images/rgb_image.png
new file mode 100644
index 0000000..e9abf0d
Binary files /dev/null and b/img/images/rgb_image.png differ
diff --git a/img/images/table_mask.png b/img/images/table_mask.png
new file mode 100644
index 0000000..bd84c91
Binary files /dev/null and b/img/images/table_mask.png differ
diff --git a/index.qmd b/index.qmd
new file mode 100644
index 0000000..e58e383
--- /dev/null
+++ b/index.qmd
@@ -0,0 +1,9 @@
+---
+title: "Données émergentes (ENSAI)"
+---
+
+Ce site web centralise les contenus du cours de Master de l'ENSAI sur les données émergentes
+
+:::{.callout-note}
+Ce site est encore dans une version très provisoire. Le contenu peut ainsi être amené à évoluer rapidement
+:::
\ No newline at end of file
diff --git a/introduction.qmd b/introduction.qmd
new file mode 100644
index 0000000..b0583bc
--- /dev/null
+++ b/introduction.qmd
@@ -0,0 +1,290 @@
+---
+title: "Introduction"
+---
+
+## Les données émergentes dans le temps long
+
+L'histoire de la statistique est une suite d'évolutions
+de la discipline où les données émergentes un jour deviennent
+le lendemain traditionnelles.
+Le XIXe siècle, qui est celui
+où la statistique s'est constituée en temps
+que discipline autonome et s'est dotée d'une partie
+des concepts qui en font aujourd'hui les fondements,
+est ainsi une période où de nombreuses données
+ont émergé et ont pu entraîner des révolutions scientifiques.
+Parmi celles-ci, la construction de la loi normale,
+qui constitue aujourd'hui l'objet central
+de la statistique, correspond au besoin de construire
+de nouveaux concepts et
+outils afin de structurer dans une théorie commune
+un ensemble de nouvelles données.
+La manière dont Gauss a collecté et
+synthétisé un ensemble d'observations
+astronomiques a ainsi permis de construire
+la méthode des moindres carrés et
+le concept de loi normale, appréhendé
+à partir des erreurs d'observations.
+
+L'accès à des recensements par des universitaires
+à la fin
+du XIXe siècle a été un élément moteur
+de la constitution de la sociologie en temps
+que discipline autonome.
+Les registres de décès ont ainsi permis
+à Durkheim de participer aux débats sociologiques
+sur le suicide et de proposer une
+interprétation sociologique
+de ses causes à rebours des
+approches psychologisantes qui
+étaient fréquentes à l'époque.
+Avant Durkheim, l'usage novateur
+des monographies a permis de
+dessiner les prémisses de la sociologie en
+temps que discipline autonome.
+Les avancées de la statistique au cours
+du XXe siècle sont intimement liées
+à la génération des enquêtes ou des sondages.
+
+Les notions d'échantillonnage, de représentativité,
+ou encore de marges d'erreur, qui sont au coeur de la
+statistique moderne, ont permis de rendre traditionnel
+ce nouveau mode de collecte. Ces enquêtes sont
+aujourd'hui
+encore très
+utilisées dans la production statistique moderne ou
+dans les
+études économiques et sociologiques.
+
+La prolifération de traces numériques, parce
+qu'elle a créé de nouvelles opportunités pour
+la puissance publique ou pour des acteurs privés
+de valoriser des données, est un moteur
+d'évolution de la statistique.
+L'émergence du concept
+de _data-science_, qu'on le considère
+comme un ensemble de pratiques ou uniquement comme
+un _buzzword_, est intimement lié à la multiplication
+des traces numériques.
+Les nouvelles disciplines ou méthodes qui se sont développées récemment
+sont intrinsèquement liées aux données
+émergentes.
+La vitesse à laquelle se
+développent les innovations dans le domaine de
+la _data-science_
+est d'une ampleur inédite du fait
+de la multiplicité des données collectées
+et des acteurs impliqués. IBM estimait en effet que 2.5 quintillions d'octets de données étaient générés chaque jour il y a environ 10 ans.
+Dans un ouvrage sur l'histoire de la statistique, @hacking-90 parle déjà en 1990 du début d'une "avalanche de chiffres".
+
+
+## La production renouvelée de données de la puissance publique
+
+La puissance publique est une productrice
+historique de données. Les
+registres administratifs ou
+comptables sont une source
+de données très appréciée des
+historiens. Si elles n'atteignent
+pas les volumétries actuelles,
+ces sources sont néanmoins
+les ancêtres de nos données administratives actuelles.
+Les recensements de population sont également
+une des productions historiques de données.
+Le comptage de la population et des impôts
+fait partie intégrante du processus
+de constitution de la puissance
+publique centralisatrice [@desrosieres2016politique].
+Curieusement, la tablette Kish de l'empire sumérien (environ 3500 av. J.-C.), l'un des plus anciens exemples d'écriture humaine, semble être un document administratif destiné à des fins statistiques.
+
+
+La
+statistique publique, si elle est aujourd'hui
+entendue beaucoup plus largement que par le passé,
+et qu'elle dispose d'une indépendance vis-à-vis
+d'autres branches de l'Etat,
+c'est parce qu'elle est un élément essentiel pour
+pour permettre le bon fonctionnement de l'économie et de la démocratie.
+Le slogan de l'Insee, _"mesurer pour comprendre"_,
+correspond bien à cette idée.
+Les statistiques officielles essaient d'objectiver les phénomènes
+socio-économiques par la collecte de données et la construction
+de concepts cohérents avec le phénomène mesuré.
+
+Les enquêtes sont historiquement une
+source privilégiée puisque
+la conception de celles-ci, en amont de la collecte et
+des retraitements post-collecte, est
+justement effectuée en fonction des
+réutilisations futures.
+Les questions sont ainsi conçues pour
+s'approcher au plus près des phénomènes qu'on
+désire quantifier et
+l'échantillonnage puis les redressements post-collecte
+permettront de contrôler la population
+sur laquelle portent les statistiques construites.
+L'inconvénient est que cette production nécessite des moyens
+et un temps conséquents (en amont de la collecte, lors de celle-ci puis
+à l'issue de celle-ci). De plus, les enquêtes ne sont pas à l'abri
+d'erreurs dans la collecte, qu'il s'agisse d'omissions ou réponses
+erronnées, qu'elles soient volontaires ou non.
+A ces problèmes s'ajoute la baisse historique des taux de réponse
+[@riviere2018].
+
+L'Etat n'accumule pas uniquement de la connaissance sur sa population
+par le biais d'enquête. Les registres des impôts, de l'assurance maladie, etc.
+sont des sources de gestion par lesquelles chaque individu communique
+un certain nombre d'informations sur lui. On parle
+de données administratives pour regrouper cet ensemble
+de sources qui sont produites par la puissance publique
+et dont la collecte répond à des enjeux de
+gestion mais pas à des besoins de statistique publique.
+La définition qu'en donnait @desrosieres2004,
+résume bien ceci: _"une source administrative est issue d'une institution dont la finalité n'est pas de produire une telle information, mais dont les activités de gestion impliquent la tenue, selon des règles générales, de fichiers ou de registres individuels, dont l'agrégation n'est qu'un sous-produit"_.
+Les besoins de la statistique publique
+ne sont donc pas à la source de la collecte mais on peut utiliser celle-ci
+comme opportunité pour enrichir la connaissance de phénomènes
+socio-économiques
+(Connelly et al., Einav et al.).
+Certaines informations disponibles dans ces données sont très
+génériques et communes à de nombreuses bases de gestion (l'état civil notamment),
+ce qui peut faciliter l'association entre elles,
+alors que d'autres sont propres à chaque source. Outre la possibilité de
+disposer d'informations sur une population plus importante, la différence
+principale entre ces
+sources de données,
+historiquement collectées
+par papier et de plus en plus par collecte numérique, et les enquêtes est
+que les premières ne sont pas conçues initialement
+à des fins de statistique donc le statisticien n'en contrôle pas
+la conceptualisation et la collecte.
+Néanmoins, ces sources peuvent fournir des informations très
+précieuses à la statistique publique. Si on est en mesure de relier celles-ci à
+une enquête, il devient possible d'enrichir ou de corriger certaines informations
+collectées si les concepts présents dans l'enquête correspondent à ceux de la
+source administrative.
+
+Les données administratives deviennent ainsi de plus en plus
+fréquemment mobilisées dans la production officielle
+de statistiques ou dans les études économiques.
+La numérisation de l'économie et
+des démarches administratives, parce qu'elle a facilité
+la constitution de bases et l'association entre
+celles-ci, a accéléré
+le mouvement de constitution de grands répertoires
+administratifs. Parmi les principaux exploités par la statistique
+publique :
+la DSN, Fidéli, le SNDS... La construction de ces sources,
+car celles-ci nécessitent pour leur usage à des fins
+statistiques une reconstruction,
+implique également un changement des institutions collectant
+la donnée. Ce n'est plus l'Insee qui collecte directement la
+donnée (que ce soit à son compte ou pour le compte d'autres
+institutions comme les services statistiques ministériels)
+mais des ministères. Ces derniers peuvent, ou non,
+exploiter ces données à leur propre compte mais aussi
+mettre à disposition la donnée brute ou une version
+retravaillée de celle-ci.
+Par exemple, la Direction Générale des Finances Publiques (DGFiP)
+est, par son rôle de collecte des impôts, un acteur central
+dans la constitution de bases sur les revenus qui permettent
+de produire de nombreuses statistiques socio-économiques.
+De même, la Caisse Nationale d'Assurance Maladie (CNAM)
+est, par son rôle de gestionnaire du système français de sécurité sociale,
+un élément central dans la constitution
+du Système national des données de santé (SNDS).
+
+La multiplication de traces numériques collectées non plus
+seulement par les acteurs publics mais aussi par des
+acteurs privés a permis de produire de nouvelles
+sources de données, à une fréquence ou à une échelle inédite.
+A ce premier facteur qu'est l'intensification de la production
+de statistique, s'ajoute la demande croissante de la
+population et des décideurs publics pour des statistiques
+plus détaillées et disponibles plus rapidement.
+Cela a ainsi amené à une intensification de la disponibilité
+de statistiques, dont la production n'est plus le monopole
+de la puissance publique.
+Afin de pouvoir produire ces statistiques, tout en satisfaisant
+aux critères usuels de qualité sur lesquels nous reviendrons,
+la statistique publique se doit d'innover dans la collecte
+traditionnelle, l'utilisation de nouvelles statistiques
+et concepts ou dans les processus de valorisation de données
+auquel elle accédait déjà. Parmi ces trois facteurs, nous
+allons principalement nous concentrer sur le deuxième,
+c'est-à-dire la valorisation de nouvelles sources de données, qu'il
+s'agisse de données produites par l'administration ou de données
+privées. Le premier point - l'innovation dans les méthodes de collecte
+traditionnelles - renvoie, entre autres, à la question du multimode.
+Enfin, en ce qui concerne le troisième élément - la rénovation des processus
+de production - il y a des éléments connexes à notre problématique
+(certaines méthodes sont intrinsèquement liées à de nouvelles sources) mais
+aussi certains qui le dépassent. Nous n'allons donc pas nous concentrer sur
+ceux-ci bien qu'il se peut que nous évoquions à plusieurs reprises ces enjeux.
+
+# Innover pour traiter ces données
+
+Les nouvelles données permettent ainsi de faire évoluer la production statistique
+en amenant à essayer d'objectiver des phénomènes qui l'étaient difficilement
+par le passé. Le fait qu'elles n'aient pas été produites initialement pour être traitées à
+des fins de statistique publique implique un surcroit de travail et de précautions
+méthodologiques pour en assurer la qualité et l'exploitation.
+Il est également nécessaire de travailler sur les métadonnées (description des données)
+pour répondre aux exigences de la statistique publique.
+
+La volumétrie et la (dé)structuration des nouvelles sources de données
+a de forts enjeux informatiques. Les innovations dans
+ce domaine sont à un rythme impressionnant. Les acteurs
+majeurs du numérique, qui sont les principaux acteurs de la collecte
+de données, sont ainsi les principaux développeurs des langages de _data-science_
+modernes. Ces derniers sont des solutions logicielles pour faciliter le traitement
+de tel ou tel type de données.
+Par exemple, `TensorFlow` a été développé par `Google`, `PyTorch` par
+`Meta`, `Airflow` par `Airbnb`.
+
+# Collaboration avec de nouveaux acteurs
+
+Ces nouvelles sources de données sont collectées par de nouveaux acteurs, qu'il
+s'agisse d'administrations, d'acteurs privés ou d'autres acteurs
+tiers (ONG, associations, instituts de recherche, etc.).
+Ces données sont parfois déjà valorisées par ces acteurs: certains acteurs
+proposent des solutions commerciales qui revendent certains agrégats
+issus des données qu'ils collectent.
+
+Pour la statistique publique, il y a donc un enjeu à
+construire des partenariats pour accéder sur la durée
+à des données collectées par d'autres. Les
+exploitations de nouvelles sources ayant été
+principalement expérimentales,
+les partenariats entre l'administration et les
+entreprises ont jusqu'à présent été souvent
+ponctuels. Les données de caisse, c'est-à-dire
+les données de supermarchés qui sont collectées
+automatiquement en caisse, sont une exception. Une réglementation
+européenne imposant leur usage pour la constitution des statistiques
+d'inflation et des séries de prix, [l'accès pérenne à celles-ci a été nécessaire](https://www.insee.fr/fr/information/4318285).
+
+Pour construire ces partenariats durables,
+il est nécessaire de respecter les intérêts des entreprises qui détiennent les données.
+Il y a besoin de confiance, de garanties de confidentialité, ce qui demande un cadre légal facilitateur.
+La responsabilité sociale doit constituer un moteur pour avancer.
+
+
+- Sur la confidentialité des données : *privacy-enhancing technologies*.
+- Besoin de moderniser la manière de produire des statistiques officielles pour s'adapter aux nouvelles sources de données et faciliter les partenariats : méthodologie et travail sur la qualité transparents (code open-source, reproductible au maximum);
+- Fonctionnement participatif et agile pour identifier les potentiels problèmes liés à la réutilisation de données privées (besoin d'experts de ces données). Réseaux de recherche avec les partenaires privés, la recherche académique, etc.
+
+# Historique
+
+- [Principes fondamentaux de la statistique publique](https://unstats.un.org/unsd/dnss/gp/fundprinciples.aspx) établis par les Nations Unies ;
+- Règles de qualité fixées par le [Code Européen de Bonnes Pratiques Statistiques](https://ec.europa.eu/eurostat/web/quality/european-quality-standards/european-statistics-code-of-practice).
+
+# Futur
+
+- L'[*Open Data Directive*](https://eur-lex.europa.eu/legal-content/EN/TXT/?qid=1561563110433&uri=CELEX:32019L1024) adoptée en 2019 identifie des jeux de données open-source à forte valeur potentielle pour la statistique publique ;
+- Le *Data Governance Act* (adopté en Mai 2022 et appliqué à partir de Septembre 2023) : promeut le partage de données personnelles et non-personnelles en mettant en place des structures d'intermédiation:
+ - Assistance technique et légale pour faciliter la réutilisation de certaines données protégées du secteur publique;
+ - Structures d'intermédiation de la donnée;
+ - Certification pour les organisations qui pratiquent le *data altruism*.
+- Le *Data Act* (proposition en Février 2022): règles sur qui peut accéder aux données générées au sein de l'UE dans chaque secteur économique, avec l'objectif de rendre les données plus accessibles pour tous;
+- Les textes vont dans une direction commune: encourager la réutilisation de données privées. Il est aussi nécessaire d'encourager une intensification des dialogues entre parties prenantes et la société entière.
diff --git a/nowcasting_exemples.qmd b/nowcasting_exemples.qmd
new file mode 100644
index 0000000..e4592e1
--- /dev/null
+++ b/nowcasting_exemples.qmd
@@ -0,0 +1,14 @@
+---
+title: "Application"
+---
+
+L'objectif de ce TP est de montrer comment récupérer des données à partir de l'API de Twitter
+et de montrer un début d'exemple d'exploitation de ces données.
+
+Le TP peut être lancé sur le `SSP Cloud` en cliquant sur le bouton suivant:
+
+
+
+Un second bouton si l'installation de `Pytorch` est trop longue:
+
+
diff --git a/references.bib b/references.bib
new file mode 100644
index 0000000..831840f
--- /dev/null
+++ b/references.bib
@@ -0,0 +1,389 @@
+@article{sobel-73,
+author = {Sobel, Irwin and Feldman, Gary},
+year = {1973},
+month = {01},
+pages = {271-272},
+title = {A 3×3 isotropic gradient operator for image processing},
+journal = {Pattern Classification and Scene Analysis}
+}
+
+@article{brown2020language,
+ title={Language models are few-shot learners},
+ author={Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and others},
+ journal={Advances in neural information processing systems},
+ volume={33},
+ pages={1877--1901},
+ year={2020}
+}
+
+@inproceedings{pennington2014glove,
+ title={Glove: Global vectors for word representation},
+ author={Pennington, Jeffrey and Socher, Richard and Manning, Christopher D},
+ booktitle={Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP)},
+ pages={1532--1543},
+ year={2014}
+}
+
+
+@inproceedings{galiana2022,
+ author = {Galiana, Lino and Suarez Castillo, Milena},
+ title = {Fuzzy Matching on Big-Data: An Illustration with Scanner and Crowd-Sourced Nutritional Datasets},
+ year = {2022},
+ isbn = {9781450392846},
+ publisher = {Association for Computing Machinery},
+ address = {New York, NY, USA},
+ url = {https://doi.org/10.1145/3524458.3547244},
+ doi = {10.1145/3524458.3547244},
+ abstract = {Food retailers’ scanner data provide unprecedented details on local consumption, provided that product identifiers allow a linkage with features of interest, such as nutritional information. In this paper, we enrich a large retailer dataset with nutritional information extracted from crowd-sourced and administrative nutritional datasets. To compensate for imperfect matching through the barcode, we develop a methodology to efficiently match short textual descriptions. After a preprocessing step to normalize short labels, we resort to fuzzy matching based on several tokenizers (including n-grams) by querying an ElasticSearch customized index and validate candidates echos as matches with a Levensthein edit-distance and an embedding-based similarity measure created from a siamese neural network model. The pipeline is composed of several steps successively relaxing constraints to find relevant matching candidates.},
+ booktitle = {Proceedings of the 2022 ACM Conference on Information Technology for Social Good},
+ pages = {331–337},
+ numpages = {7},
+ keywords = {ElasticSearch, Fuzzy matching, Siamese neural networks, Natural language processing, Word embeddings},
+ location = {Limassol, Cyprus},
+ series = {GoodIT '22}
+}
+
+
+@article{LuitenHoxde,
+author = {Annemieke Luiten and Joop Hox and Edith de Leeuw},
+doi = {doi:10.2478/jos-2020-0025},
+url = {https://doi.org/10.2478/jos-2020-0025},
+title = {Survey Nonresponse Trends and Fieldwork Effort in the 21st Century: Results of an International Study across Countries and Surveys},
+journal = {Journal of Official Statistics},
+number = {3},
+volume = {36},
+year = {2020},
+pages = {469--487}
+}
+
+
+
+@ARTICLE{lecun-89,
+author={LeCun, Y. and Boser, B. and Denker, J. S. and Henderson, D. and Howard, R. E. and Hubbard, W. and Jackel, L. D.},
+journal={Neural Computation},
+title={Backpropagation Applied to Handwritten Zip Code Recognition},
+year={1989},
+volume={1},
+number={4},
+pages={541-551},
+doi={10.1162/neco.1989.1.4.541}
+}
+
+@article{voulodimos-18,
+doi = {10.1155/2018/7068349},
+url = {https://doi.org/10.1155/2018/7068349},
+year = {2018},
+publisher = {Hindawi Limited},
+volume = {2018},
+pages = {1--13},
+author = {Athanasios Voulodimos and Nikolaos Doulamis and Anastasios Doulamis and Eftychios Protopapadakis},
+title = {Deep Learning for Computer Vision: A Brief Review},
+journal = {Computational Intelligence and Neuroscience}
+}
+
+@article{chen-17,
+author = {Liang{-}Chieh Chen and
+ George Papandreou and
+ Florian Schroff and
+ Hartwig Adam},
+title = {Rethinking Atrous Convolution for Semantic Image Segmentation},
+journal = {CoRR},
+volume = {abs/1706.05587},
+year = {2017},
+url = {http://arxiv.org/abs/1706.05587},
+eprinttype = {arXiv},
+eprint = {1706.05587},
+timestamp = {Mon, 13 Aug 2018 16:48:07 +0200},
+biburl = {https://dblp.org/rec/journals/corr/ChenPSA17.bib},
+bibsource = {dblp computer science bibliography, https://dblp.org}
+}
+
+@article{steele-17,
+doi = {10.1098/rsif.2016.0690},
+url = {https://doi.org/10.1098/rsif.2016.0690},
+year = {2017},
+month = feb,
+publisher = {The Royal Society},
+volume = {14},
+number = {127},
+pages = {20160690},
+author = {Jessica E. Steele and P{\aa}l Roe Sunds{\o}y and Carla Pezzulo and Victor A. Alegana and Tomas J. Bird and Joshua Blumenstock and Johannes Bjelland and Kenth Eng{\o}-Monsen and Yves-Alexandre de Montjoye and Asif M. Iqbal and Khandakar N. Hadiuzzaman and Xin Lu and Erik Wetter and Andrew J. Tatem and Linus Bengtsson},
+title = {Mapping poverty using mobile phone and satellite data},
+journal = {Journal of The Royal Society Interface}
+}
+
+@book{plan-sat,
+author = {Commissariat général au développement durable – Direction de la recherche et de l’innovation},
+year = {2018},
+month = {07},
+pages = {},
+title = {Plan d’applications satellitaires 2018 - Des solutions spatiales pour connaître le territoire}
+}
+
+@article{ronneberger-15,
+author = {Olaf Ronneberger and
+ Philipp Fischer and
+ Thomas Brox},
+title = {U-Net: Convolutional Networks for Biomedical Image Segmentation},
+journal = {CoRR},
+volume = {abs/1505.04597},
+year = {2015},
+url = {http://arxiv.org/abs/1505.04597},
+eprinttype = {arXiv},
+eprint = {1505.04597},
+timestamp = {Mon, 13 Aug 2018 16:46:52 +0200},
+biburl = {https://dblp.org/rec/journals/corr/RonnebergerFB15.bib},
+bibsource = {dblp computer science bibliography, https://dblp.org}
+}
+
+@article{paliwal-20,
+author = {Shubham Paliwal and
+ Vishwanath D and
+ Rohit Rahul and
+ Monika Sharma and
+ Lovekesh Vig},
+title = {TableNet: Deep Learning model for end-to-end Table detection and Tabular
+ data extraction from Scanned Document Images},
+journal = {CoRR},
+volume = {abs/2001.01469},
+year = {2020},
+url = {http://arxiv.org/abs/2001.01469},
+eprinttype = {arXiv},
+eprint = {2001.01469},
+timestamp = {Thu, 14 Oct 2021 09:16:25 +0200},
+biburl = {https://dblp.org/rec/journals/corr/abs-2001-01469.bib},
+bibsource = {dblp computer science bibliography, https://dblp.org}
+}
+
+@article{beck2022,
+ title={Le multimode dans les enquêtes auprès des ménages : une collecte modernisée, un processus complexifié},
+ author={Beck, François and Castell, Laura and Legleye, Stéphane and Schreiber, Amandine},
+ journal={Courrier des statistiques},
+ year={2022}
+}
+
+
+@article{riviere2018,
+ title={Utiliser les déclarations administratives à des fins statistiques},
+ author={Rivière, Pascal},
+ journal={Courrier des statistiques},
+ year={2018}
+}
+
+@book{desrosieres2016politique,
+ title={La politique des grands nombres: histoire de la raison statistique},
+ author={Desrosi{\`e}res, Alain},
+ year={2010},
+ publisher={La d{\'e}couverte}
+}
+
+@article{desrosieres2004,
+ title={Enquêtes versus registres administratifs: réflexions sur la dualité des sources statistiques},
+ author={Desrosi{\`e}res, Alain},
+ journal={Courrier des statistiques},
+ year={2004}
+}
+
+@article{isnard2018,
+ title={Qu'entends-on par statistique(s) publique(s)},
+ author={Isnard, Michel},
+ journal={Courrier des statistiques},
+ year={2018}
+}
+
+@article{Humbert2018,
+ title={La déclaration sociale nominative: nouvelle référence pour les échanges de données sociales des entreprises vers les administrations},
+ author={Humbert-Bottin, Élisabeth},
+ journal={Courrier des statistiques},
+ year={2018}
+}
+
+@article{Renne2018,
+ title={Bien comprendre la déclaration sociale nominative pour mieux mesurer},
+ author={Renne, Catherine},
+ journal={Courrier des statistiques},
+ year={2018}
+}
+
+
+@article{galiana-20,
+title={Retour partiel des mouvements de population avec le d{\'e}confinement},
+author={Galiana, Lino and Suarez-Castillo, Milena and S{\'e}m{\'e}curbe, Fran{\c{c}}ois and Coudin, {\'E}lise and de Bellefon, Marie-Pierre},
+year={2020},
+publisher={Insee Analyses}
+}
+
+@article{galiana2020segregation,
+ title={Residential segregation, daytime segregation and spatial frictions: an analysis from mobile phone data },
+ author={Galiana, Lino and S{\'e}m{\'e}curbe, Fran{\c{c}}ois and Sakarovitch, Benjamin and Smoreda, Zbigniew},
+ year={2020},
+ publisher={Insee Working Paper}
+}
+
+@article{ricciato-20,
+title = {Towards a methodological framework for estimating present population density from mobile network operator data},
+journal = {Pervasive and Mobile Computing},
+volume = {68},
+pages = {101263},
+year = {2020},
+issn = {1574-1192},
+doi = {10.1016/j.pmcj.2020.101263},
+url = {https://www.sciencedirect.com/science/article/pii/S1574119220301097},
+author = {Fabio Ricciato and Giampaolo Lanzieri and Albrecht Wirthmann and Gerdy Seynaeve},
+keywords = {Mobile network operator data, Signalling data, Present population, Spatial density estimation, Experimental statistics},
+abstract = {The concept of present population is gaining increasing attention in official statistics. One possible approach to measure present population exploits data collected by Mobile Network Operators (MNO), from simple Call Detail Records (CDR) to more informative and complex signalling records. Such data, collected primarily for network operation processes, can be repurposed to infer patterns of human mobility. Two decades of research literature have produced several case studies, mostly focused on to CDR data, and a variety of ad-hoc methodologies tailored to specific datasets. Moving beyond the stage of explorative research, the regular production of official statistics across different MNO requires a more systematic approach to methodological development. Towards this aim, Eurostat and other members of the European Statistical System are working towards the definition of a general Reference Methodological Framework for processing MNO data for official statistics. In this contribution we report on the methodological aspects related to the estimation of present population density, for which we present a general and modular methodological structure that generalises previous proposals found in the academic literature. Along the way, we define a number of specific research problems requiring further attention by the research community. We stress the importance of comparing different methodological options at various points in the data workflow, e.g. in the geolocation of individual observations and in the inference method. Finally, we present illustrative results from a case-study based on real signalling data from a European operational network, complemented by numerical results from a simple simulation scenario.}
+}
+
+@article{feuillet-18,
+doi = {10.4000/cybergeo.29853},
+url = {https://doi.org/10.4000/cybergeo.29853},
+year = {2018},
+month = dec,
+publisher = {{OpenEdition}},
+author = {Vincent Loonis and Marie-Pierre de Bellefon},
+title = {Manuel d'analyse spatiale. Th{\'{e}}orie et mise en {\oe}uvre pratique avec R, Insee~M{\'{e}}thodes n{\textdegree}~131, Insee, Eurostat, 392~p.},
+journal = {Cybergeo}
+}
+
+@article{andre-21,
+title={Et pour quelques appartements de plus : {\'E}tude de la propri{\'e}t{\'e} immobili{\`e}re des m{\'e}nages et du profil redistributif de la taxe fonci{\`e}re},
+author={Mathias Andr{\'e} and Olivier Meslin},
+year={2021},
+publisher={Documents de travail, Insee}
+}
+
+@TechReport{cerdeiro-20,
+author={Mr. Diego A. Cerdeiro and Andras Komaromi and Yang Liu and Mamoon Saeed},
+title={{World Seaborne Trade in Real Time: A Proof of Concept for Building AIS-based Nowcasts from Scratch}},
+year=2020,
+month=May,
+institution={International Monetary Fund},
+type={IMF Working Papers},
+url={https://ideas.repec.org/p/imf/imfwpa/2020-057.html},
+number={2020/057},
+abstract={Maritime data from the Automatic Identification System (AIS) have emerged as a potential source for real time information on trade activity. However, no globally applicable end-to-end solution has been published to transform raw AIS messages into economically meaningful, policy-relevant indicators of international trade. Our paper proposes and tests a set of algorithms to fill this gap. We build indicators of world seaborne trade using raw data from the radio signals that the global vessel fleet emits for navigational safety purposes. We leverage different machine-learning techniques to identify port boundaries, construct port-to-port voyages, and estimate trade volumes at the world, bilateral and within-country levels. Our methodology achieves a good fit with official trade statistics for many countries and for the world in aggregate. We also show the usefulness of our approach for sectoral analyses of crude oil trade, and for event studies such as Hurricane Maria and the effect of measures taken to contain the spread of the novel coronavirus. Going forward, ongoing refinements of our algorithms, additional data on vessel characteristics, and country-specific knowledge should help improve the performance of our general approach for several country cases.},
+keywords={},
+doi={},
+}
+
+@unknown{imo-20,
+author = {International Maritime Organization},
+year = {2020},
+month = {06},
+pages = {},
+title = {IMO Fourth Greenhouse Gas Study 2020}
+}
+
+@article{brakel-17,
+author = {Brakel, Jan and Söhler, Emily and Daas, P.J.H. and Buelens, Bart},
+year = {2017},
+month = {12},
+pages = {},
+title = {Social media as a data source for official statistics; the Dutch Consumer Confidence Index},
+volume = {43},
+journal = {Survey methodology}
+}
+
+@ARTICLE{olteanu-19,
+AUTHOR={Olteanu, Alexandra and Castillo, Carlos and Diaz, Fernando and Kıcıman, Emre},
+TITLE={Social Data: Biases, Methodological Pitfalls, and Ethical Boundaries},
+JOURNAL={Frontiers in Big Data},
+VOLUME={2},
+YEAR={2019},
+URL={https://www.frontiersin.org/articles/10.3389/fdata.2019.00013},
+DOI={10.3389/fdata.2019.00013},
+ISSN={2624-909X},
+ABSTRACT={Social data in digital form—including user-generated content, expressed or implicit relations between people, and behavioral traces—are at the core of popular applications and platforms, driving the research agenda of many researchers. The promises of social data are many, including understanding “what the world thinks” about a social issue, brand, celebrity, or other entity, as well as enabling better decision-making in a variety of fields including public policy, healthcare, and economics. Many academics and practitioners have warned against the naïve usage of social data. There are biases and inaccuracies occurring at the source of the data, but also introduced during processing. There are methodological limitations and pitfalls, as well as ethical boundaries and unexpected consequences that are often overlooked. This paper recognizes the rigor with which these issues are addressed by different researchers varies across a wide range. We identify a variety of menaces in the practices around social data use, and organize them in a framework that helps to identify them.“For your own sanity, you have to remember that not all problems can be solved. Not all problems can be solved, but all problems can be illuminated.” –Ursula Franklin1}
+}
+
+@ARTICLE{schumacher-16,
+title = {A comparison of MIDAS and bridge equations},
+author = {Schumacher, Christian},
+year = {2016},
+journal = {International Journal of Forecasting},
+volume = {32},
+number = {2},
+pages = {257-270},
+abstract = {This paper compares two single-equation approaches from the recent nowcasting literature: mixed-data sampling (MIDAS) regressions and bridge equations. Both approaches are suitable for nowcasting low-frequency variables such as the quarterly GDP using higher-frequency business cycle indicators. Three differences between the approaches are identified: (1) MIDAS is a direct multi-step nowcasting tool, whereas bridge equations provide iterated forecasts; (2) the weighting of high-frequency predictor observations in MIDAS is based on functional lag polynomials, whereas the bridge equation weights are fixed partly by time aggregation; (3) for parameter estimation, the MIDAS equations consider current-quarter leads of high-frequency indicators, whereas bridge equations typically do not. To assist in discussing the differences between the approaches in isolation, intermediate specifications between MIDAS and bridge equations are provided. The alternative models are compared in an empirical application to nowcasting GDP growth in the Euro area, given a large set of business cycle indicators.},
+keywords = {Mixed-data sampling; Bridge equations; Nowcasting;},
+url = {https://EconPapers.repec.org/RePEc:eee:intfor:v:32:y:2016:i:2:p:257-270}
+}
+
+@inbook {stock-10,
+ title = {Dynamic Factor Models},
+ booktitle = {Oxford Handbook of Economic Forecasting},
+ year = {2010},
+ publisher = {Oxford University Press},
+ organization = {Oxford University Press},
+ address = {Oxford},
+ url = {http://www.economics.harvard.edu/faculty/stock/files/dfm_oup_4.pdf},
+ author = {James Stock and Mark Watson},
+ editor = {Michael P. Clements and David F. Henry}
+}
+
+@misc{hopp-21,
+ doi = {10.48550/ARXIV.2106.08901},
+ url = {https://arxiv.org/abs/2106.08901},
+ author = {Hopp, Daniel},
+ keywords = {Econometrics (econ.EM), Machine Learning (cs.LG), FOS: Economics and business, FOS: Economics and business, FOS: Computer and information sciences, FOS: Computer and information sciences},
+ title = {Economic Nowcasting with Long Short-Term Memory Artificial Neural Networks (LSTM)},
+ publisher = {arXiv},
+ year = {2021},
+ copyright = {Creative Commons Attribution 4.0 International}
+}
+
+@article{richardson-18,
+ author = {Richardson, Pete},
+ title = {Nowcasting and the Use of Big Data in Short Term Macroeconomic Forecasting: A Critical Review},
+ year = {2018},
+ url = {https://www.persee.fr/doc/estat_0336-1454_2018_num_505_1_10867},
+ note = {Included in a thematic issue : Big Data and Statistics (Part 1)},
+ journal = {Economie et Statistique},
+ volume = {505},
+ number = {1},
+ doi = {10.24187/ecostat.2018.505d.1966},
+ pages = {65--87}
+}
+
+@article{bortoli-18,
+ TITLE = {{Nowcasting GDP Growth by Reading Newspapers}},
+ AUTHOR = {Bortoli, Cl{\'e}ment and Combes, St{\'e}phanie and Renault, Thomas},
+ URL = {https://hal.archives-ouvertes.fr/hal-03205161},
+ JOURNAL = {{Economie et Statistique / Economics and Statistics}},
+ PUBLISHER = {{INSEE}},
+ SERIES = {Big Data and Statistics - Part 1},
+ NUMBER = {505-506},
+ PAGES = {17-33},
+ YEAR = {2018},
+ DOI = {10.24187/ecostat.2018.505d.1964},
+ KEYWORDS = {economic analysis ; nowcasting ; GDP ; media ; Big Data ; sentiment analysis ; machine learning ; natural language analysis},
+ HAL_ID = {hal-03205161},
+ HAL_VERSION = {v1},
+}
+
+@TechReport{fornaro-20,
+ author={Fornaro, Paolo},
+ title={{Nowcasting Industrial Production Using Uncoventional Data Sources}},
+ year=2020,
+ month=Jun,
+ institution={The Research Institute of the Finnish Economy},
+ type={ETLA Working Papers},
+ url={https://ideas.repec.org/p/rif/wpaper/80.html},
+ number={80},
+ abstract={ In this work, we rely on unconventional data sources to nowcast the year-on-year growth rate of Finnish industrial production, for different industries. As predictors, we use real-time truck traffic volumes measured automatically in different geographical locations around Finland, as well as electricity consumption data. In addition to standard time-series models, we look into the adoption of machine learning techniques to compute the predictions. We find that the use of non-typical data sources such as the volume of truck traffic is beneficial, in terms of predictive power, giving us substantial gains in nowcasting performance compared to an autoregressive model. Moreover, we find that the adoption of machine learning techniques improves substantially the accuracy of our predictions in comparison to standard linear models. While the average nowcasting errors we obtain are higher compared to the current revision errors of the official statistical institute, our nowcasts provide clear signals of the overall trend of the series and of sudden changes in growth.},
+ keywords={Flash Estimates; Machine Learning; Big Data; Nowcasting},
+ doi={},
+}
+
+@misc{salgado-20,
+ doi = {10.48550/ARXIV.2003.06797},
+ url = {https://arxiv.org/abs/2003.06797},
+ author = {Salgado, David and Oancea, Bogdan},
+ keywords = {Other Statistics (stat.OT), Applications (stat.AP), FOS: Computer and information sciences, FOS: Computer and information sciences, J.1; J.4; H.4, 62P25, 62P20},
+ title = {On new data sources for the production of official statistics},
+ publisher = {arXiv},
+ year = {2020},
+ copyright = {Creative Commons Attribution 4.0 International}
+}
+
+@book{hacking-90, place={Cambridge}, series={Ideas in Context}, title={The Taming of Chance}, DOI={10.1017/CBO9780511819766}, publisher={Cambridge University Press}, author={Hacking, Ian}, year={1990}, collection={Ideas in Context}}
\ No newline at end of file
diff --git a/series_temporelles.qmd b/series_temporelles.qmd
new file mode 100644
index 0000000..66a2884
--- /dev/null
+++ b/series_temporelles.qmd
@@ -0,0 +1,104 @@
+---
+title: "Nowcasting"
+---
+
+
+La statistique publique publiant des statistiques à intervalle régulier, une
+longue tradition de production et d'exploitation de séries temporelles
+précède les innovations récentes. La constance de la méthodologie, ou les
+harmonisations faites _a posteriori_ - par exemple la technique de la
+rétropolation en comptabilité nationale - assure en théorie
+une forme de comparabilité et permet de considérer
+les productions statistiques comme des séries temporelles.
+Parmi les productions statistiques dont la formalisation a été la plus
+précoce, la comptabilité nationale tient une bonne place. Le Système
+de Comptabilité Nationale (SCN) est ainsi un cadre international
+harmonisé qui permet la construction de séries temporelles depuis
+l'après-guerre. La France est l'un des pays pour lesquels il
+est possible de remonter le plus loin dans le passé avec des
+séries harmonisées depuis XXXX.
+
+En raison de délais imposés par la collecte et le traitement des données,
+certains indicateurs supposés donner des informations sur la situation actuelle sont publiés avec du retard et ne peuvent pas jouer leur rôle dans la prise de décision publique. C'est pourquoi la statistique publique participe aussi à la réalisation de prévisions à court terme de valeurs d'indicateurs macro-économiques.
+Si la production de séries statistiques récurrentes fait partie
+des missions de tous les instituts statistiques, l'Insee a également
+des missions plus spécifiques dans le domaine des séries temporelles.
+La construction d'indicateurs conjoncturels prospectifs, au
+service du débat public et de la prise de décision politique, en fait partie.
+A l'Insee cette mission prospective est assurée par le département de la
+conjoncture qui construit des indicateurs et des analyses prospectifs
+sur l'activité économiques des prochains trimestres.
+Ce département
+mobilise historiquement des données dont la remontée est plus rapide que celles
+utilisées pour la construction des agrégats macroéconomiques de la
+comptabilité nationale.
+Cependant, la collecte accrue de traces numériques a permis l'accès à
+des données à haute fréquence pouvant être mobilisées
+pour disposer de signaux sur la situation macroéconomique actuelle ou
+très récente.
+
+
+Dans ce cadre, l'`Insee`, `QuantCube`[^1], Paris School of Economics[^2], `CANDRIAM` et la Société Générale ont créé une Chaire de recherche **Mesures de l'économie, nowcasting ‐ au‐delà du PIB** en 2021. Cette Chaire a pour objectif de travailler sur l'amélioration des prévisions économiques, en particulier grâce à la mobilisation de nouvelles sources de données. Parmi ces nouvelles sources, on trouve les actualités [@bortoli-18], les médias sociaux, les données satellitaires, les réseaux professionnels et les avis de consommateurs, ainsi que les données sur le commerce international, la consommation d'électricité et le transport routier [@fornaro-20], le transport maritime, l'immobilier, l'hôtellerie et les télécommunications.
+Un autre objectif de la Chaire est de travailler sur la mesure de nouveaux indicateurs économiques, de bien-être ou de développement durable (**au‐delà du PIB**),
+ici encore en utilisant ces données nouvelles.
+
+[^1]: Start‐up proposant des prévisions macroéconomiques fondées sur le Big Data et l'intelligence artificielle
+[^2]: société internationale de gestion d'actifs
+
+Côté technique, des modèles autorégressifs de type *bridge models* ou *mixed-data sampling* [@schumacher-16], des *dynamic factor models* [@stock-10] ou plus récemment des modèles de Deep Learning de type LSTM [@hopp-21] sont souvent utilisés pour combiner des indicateurs de type *soft* comme le climat des affaires ou le sentiment des consommateurs avec des indicateurs *hard* comme la production industrielle, le commerce de détail, les prix de l’immobilier, etc. à différentes fréquences. La littérature fait particulièrement état de l'utilisation de deux sources de données massive permettant d'obtenir des indicateurs *soft* [@richardson-18], même si bien d'autres sources ont été expertisées :
+
+‑ les statistiques de recherches sur Internet basées sur la fréquence de recherche de mots‑clés ou de sujets spécifiques ;
+‑ les médias sociaux sur Internet (Twitter).
+
+# Statistiques de recherches sur Internet
+
+L'idée derrière l'utilisation de ces données est la suivante : les recherches sur Internet sont devenues un moyen répandu pour les agents économiques d’obtenir des informations pertinentes sur leur situation et leurs décisions économiques immédiates. Ainsi, les événements courants
+se reflètent dans le comportement de recherche et peuvent être corrélés à des statistiques macro-économiques. `Google` a mis en place des services permettant l'accès à des statistiques sur les recherches effectuées via son moteur de recherche : [`Google Trends`](https://trends.google.fr/trends/).
+
+L'apport de données de Google Trends dans le cadre de prédictions économiques a été évaluée concernant le marché du travail et le chômage, la consommation, le marché du logement, le tourisme et les anticipations d’inflation, ainsi que d'autres études macro-économiques [@givordblanchet].
+Dans la plupart des cas, les auteurs constatent une amélioration de la précision prédictive mais cette dernière est souvent assez limitée et n'est pas toujours robuste.
+
+# Données de réseaux sociaux
+
+Les données de réseaux sociaux (en particulier `Twitter`) ont déjà
+été évoquées du fait de leur dimension
+géographique ou textuelle. Elles
+présentent également un aspect temporel.
+Les données de réseaux sociaux ont
+des avantages par rapport aux données de recherches sur Internet :
+
+- ces données sont beaucoup plus riches, avec beaucoup d'information associée à chaque observation (contenu textuel du tweet, informations sur l'utilisateur, etc.) ;
+- ces données permettent une approche stratifiée, en utilisant les informations de groupes d’utilisateurs bien définis ;
+- l’absence de préparation par les propriétaires des données (comme c'est le cas pour Google Trends), qui peut en réalité constituer un avantage ou un inconvénient.
+
+Des données issues de `Twitter` ont été testées dans des études de prévisions du comportement des marchés financiers et du marché du travail (utililsation d'indicateurs dérivés de la fréquence d'utilisation des termes de perte et de recherche d'emploi dans des échantillons de tweets) entre autres.
+
+Comme pour les données de Google Trends, les résultats sont mitigés,
+ce qui est naturel si on réfléchit aux biais qui limitent le potentiel de ces données.
+Tout d'abord, pour pouvoir récupérer les tweets pertinents concernant un certain sujet,
+il est nécessaire de mettre au point des bonnes méthodes de recherche sur de grands ensembles d’entrées.
+On constate d'ailleurs une forte sensibilité aux choix des mots-clés ou en général à la spécification de la recherche. Les jeux de données récupérés sont sujets à un fort biais de sélection : les utilisateurs de Twitter qui communiquent sur un sujet ne sont pas représentatifs de la population générale. Il faut en outre pouvoir correctement interpréter le contenu des textes, ce qui représente en général une tâche difficile
+(les progrès récents en NLP ont permis des fortes avancées sur ce point).
+
+# Le *nowcasting* à l'Insee
+
+L'Insee a travaillé de manière particulièrement intensive
+sur le *nowcasting* au cours de la crise sanitaire liée au Covid-19,
+moment auquel le travail des conjoncturistes de l'Insee
+a été réorienté pour mesurer au mieux,
+à chaque instant, la chute de l'activité économique.
+
+Pour réaliser cette évaluation, l'Insee a recueilli de l'information de la part d'entreprises ou de branches professionnelles, directement ou via des partenaires (par exemple la Banque de France ou des instituts de conjoncture).
+Cette information a été traitée, secteur par secteur, pour donner un ordre de grandeur de perte d'activité à hauteur d'un tiers du PIB.
+Pour consolider ce résultat, il a été choisi d'exploiter d'autres sources de données disponibles à haute fréquence. Ont été envisagées mais écartées plusieurs pistes : consommation d'électricité, indicateurs de pollution, Google Trends, vocabulaire utilisé dans la presse, etc.
+Finalement, des statistiques issues des transactions par cartes bancaires fournies par le Groupement des Cartes Bancaires CB[^3], ont été privilégiées.
+
+[^3]: Dans le domaine de la monétique, le Groupement des cartes bancaires est un groupement d'intérêt économique privé qui réunit la plupart des établissements financiers français dans le but d'assurer l'interbancarité des cartes de paiement.
+
+Ces données ont permis, très tôt dans le confinement,
+de confirmer l'ordre de grandeur d'une chute d'un tiers pour la consommation.
+Le 26 mars, l'Insee publie donc une estimation de chute de PIB (en instantané par rapport à un régime normal) de 35 % et de chute de la consommation des ménages du même ordre de grandeur. Cet ordre de grandeur s'est révélé assez fiable. Il a été confirmé par deux mises à jour ultérieures et par des évaluations de la Banque de France et des instituts de conjoncture nationaux.
+
+Des données de téléphonie mobile à haute fréquence ont également été utilisées pour mesurer les déplacements de populations au moment des confinement et déconfinement
+[@galiana-20]. Plus d'éléments sont présentés à ce propos
+dans le chapitre sur les données géolocalisées.
diff --git a/styles.css b/styles.css
new file mode 100644
index 0000000..2ddf50c
--- /dev/null
+++ b/styles.css
@@ -0,0 +1 @@
+/* css styles */
diff --git a/textes.qmd b/textes.qmd
new file mode 100644
index 0000000..9278ca4
--- /dev/null
+++ b/textes.qmd
@@ -0,0 +1,344 @@
+---
+title: "Données textuelles et non structurées"
+---
+
+Les données textuelles sont aujourd'hui parmi les types de données les
+plus prometteurs pour la statistique publique
+et l'un des champs les plus actifs de la recherche
+en _data science_.
+Pour cause, de plus en plus de services existent
+sur le _web_ qui conduisent à la collecte de données textuelles. En outre,
+des nouvelles méthodes pour collecter et traiter ces
+traces numériques particulières ont été développées dans les
+dernières années.
+
+Une partie des méthodes d'analyse qui appartiennent
+à la palette des compétences des _data scientists_
+spécialistes du traitement de données textuelles sont en réalité assez
+anciennes.
+Par exemple, la [distance de Levensthein](https://en.wikipedia.org/wiki/Levenshtein_distance)
+a été proposée
+pour la première fois en 1965, l'ancêtre des réseaux
+de neurone actuels est le perceptron qui date de 1957, etc.[^1]
+Néanmoins, le fait que certaines entreprises du net
+basent leur _business model_ sur le traitement
+et la valorisation de la donnée
+textuelle, notamment Google, Facebook et Twitter, a amené
+à renouveler le domaine.
+
+[^1]: Pour remonter plus loin dans la ligne du temps des
+données textuelles, on peut penser
+au [`Soundex`](https://en.wikipedia.org/wiki/Soundex),
+un algorithme d'indexation des textes dans
+les annuaires dont l'objectif était de permettre
+de classer à la suite des noms qui ne déviaient que
+par une différence typographique et non sonore.
+
+La statistique publique s'appuie également sur la collecte
+et le traitement de données textuelles. Les collectes
+de données officielles ne demandent pas exclusivement
+d'informations sous le forme de texte. Les premières informations
+demandées sont généralement un état civil, une adresse, etc.
+C'est ensuite, en fonction du thème de l'enquête, que d'autres
+informations textuelles seront collectées: un nom
+d'entreprise, un titre de profession, etc. Les données
+administratives elles-aussi comportent souvent des informations
+textuelles. Ces données défient l'analyse statistique car
+cette dernière, qui vise à détecter des grandes structures
+à partir d'observations multiples, doit s'adapter à la différence
+des données textuelles: le langage est un champ où
+certaines des notions usuelles de la statistique (distance, similarité notamment)
+doivent être revues.
+
+Ce chapitre propose un panorama très incomplet de l'apport
+des données non structurées, principalement textuelles,
+pour la statistique et l'analyse de données. Nous évoquerons
+plusieurs sources ou méthodes de collecte. Nous ferons
+quelques détours par des exemples pour aller plus
+loin.
+
+# Webscraping
+
+## Présentation
+
+Le [webscraping](https://fr.wikipedia.org/wiki/Web_scraping) est une méthode de collecte de données qui repose
+sur le moissonnage d'objets de grande dimension (des pages web)
+afin d'en extraire des informations ponctuelles (du texte, des nombres...). Elle désigne les techniques d'extraction du contenu des sites Internet. C'est une pratique très utile pour toute personne souhaitant travailler sur des informations disponibles en ligne, mais n'existant pas forcément sous la forme de fichiers exportables.
+
+## Enjeux pour la statistique publique
+
+Le *webscraping* présente un certain nombre d'enjeux en termes de légalité, qui ne seront pas enseignés dans ce cours. En particulier, la Commission nationale de l'informatique et des libertés (CNIL) a publié en 2020 de nouvelles directives sur le *webscraping* reprécisant qu'aucune donnée ne peut être réutilisée à l'insu de la personne à laquelle elle appartient.
+
+Le *webscraping* est un domaine où la reproductibilité est compliquée à mettre en oeuvre. Une page *web* évolue
+régulièrement et d'une page web à l'autre, la structure peut
+être très différente ce qui rend certains codes difficilement généralisables.
+Par conséquent, la meilleure manière d'avoir un programme fonctionnel est
+de comprendre la structure d'une page web et dissocier les éléments exportables
+à d'autres cas d'usages des requêtes *ad hoc*.
+
+Un code qui fonctionne aujourd'hui peut ainsi très bien ne plus fonctionner
+au bout de quelques semaines. Il apparaît
+préférable de privilégier les API
+qui sont un accès en apparence plus compliqué mais en fait plus fiable à moyen terme.
+Cette difficulté à construire une extraction de données pérenne par
+_webscraping_ une illustration du principe _"there is no free lunch"_.
+La donnée est au cœur du business model de nombreux acteurs, il est donc logique qu'ils essaient de restreindre la moisson de leurs données.
+
+Les APIs sont un mode d'accès de plus en plus généralisé à des données.
+Cela permet un lien direct entre fournisseurs et utilisateurs de données,
+un peu sous la forme d'un contrat. Si les données sont ouvertes avec restrictions, on utilise des clés d'authentification.
+Avec les API, on structure sa demande de données sous forme de requête paramétrée (source désirée, nombre de lignes, champs...)
+et le fournisseur de données y répond, généralement sous la forme d'un résultat au format `JSON`.
+`Python` et `JavaScript` sont deux outils très populaires pour récupérer de la donnée
+selon cette méthode.
+Pour plus de détails, vous pouvez explorer le
+[chapitre sur les API dans le cours de `Python` de l'ENSAE](https://pythonds.linogaliana.fr/api/).
+
+On n'est pas à l'abri de mauvaises surprises avec les
+APIs (indisponibilité, limite atteinte de requêtes...)
+mais cela permet un lien plus direct avec la dernière donnée publiée par un producteur.
+L'avantage de l'API est qu'il s'agit d'un service du fournisseur de données, qui en tant
+que service va amener un producteur à essayer de répondre à une
+demande dans la mesure du possible.
+Le _webscraping_ étant un mode d'accès à la donnée plus opportuniste,
+où le réel objectif du producteur de données n'est pas de fournir de la
+donnée mais une page _web_, il n'y a aucune garantie de service ou
+de continuité.
+
+
+## Exemples dans la statistique publique
+
+
+
+## Implémentations
+
+`Python` est le langage le plus utilisé
+par les _scrappers_.
+`BeautifulSoup` sera suffisant quand vous voudrez travailler sur des pages HTML statiques. Dès que les informations que vous recherchez sont générées via l'exécution de scripts [`Javascript`](https://fr.wikipedia.org/wiki/JavaScript), il vous faudra passer par des outils comme [`Selenium`](https://selenium-python.readthedocs.io/).
+De même, si vous ne connaissez pas l'URL, il faudra passer par un framework comme [`Scrapy`](https://scrapy.org/), qui passe facilement d'une page à une autre ("crawl"). Scrapy est plus complexe à manipuler que `BeautifulSoup` : si vous voulez plus de détails, rendez-vous sur la page du [tutoriel `Scrapy`](https://doc.scrapy.org/en/latest/intro/tutorial.html).
+Pour plus de détails, voir le [TP sur le webscraping en 2e année de l'ENSAE](https://pythonds.linogaliana.fr/webscraping/).
+
+Les utilisateurs de `R` privilégieront `httr` and `rvest` qui sont les packages les plus
+utilisés.
+Il est intéressant d'accorder de l'attention à
+[`polite`](https://github.com/dmi3kno/polite). Ce package vise à récupérer
+des données en suivant les [recommandations de bonnes pratiques](https://towardsdatascience.com/ethics-in-web-scraping-b96b18136f01) sur
+le sujet, notamment de respecter les instructions dans
+`robots.txt` (_"The three pillars of a polite session are seeking permission, taking slowly and never asking twice"_).
+
+# Réseaux sociaux
+
+Les réseaux sociaux sont l'une des sources textuelles
+les plus
+communes. C'est leur usage à des fins commerciales
+qui a amené les entreprises du net à renouveler
+le champ de l'analyse textuelles qui bénéficie
+au-delà de leur champ d'origine.
+
+On rentre un peu plus en détail sur ces données dans le chapitre **Nowcasting**.
+
+# Les modèles de langage
+
+Un modèle de langage est un modèle statistique qui modélise la distribution de séquences de mots, plus généralement de séquences de symboles discrets (lettres, phonèmes, mots), dans une langue naturelle. Un des objectifs de ces modèles est
+de pouvoir transformer des objets (textes) situés dans un espace d'origine de très grande dimension, qui de plus
+utilise des éléments contextuels, en informations situés dans un espace de dimension réduite. Il s'agit ainsi de transformer des éléments d'un corpus,
+par exemple des mots, en vecteurs multidimensionnels sur lequel on peut
+ensuite par exemple appliquer des opérations arithmétiques.
+Un modèle de langage peut par exemple servir à prédire le mot suivant une séquence de mots
+ou la similarité de sens entre deux phrases.
+
+## Du bag of words aux modèles de langage
+
+L'objectif du _Natural Langage Processing_ (NLP)
+est de transformer une information de très haute
+dimension (une langue est un objet éminemment complexe)
+en information à dimension plus limitée qui peut
+être exploitée par un ordinateur.
+
+La première approche pour entrer dans l'analyse d'un
+texte est généralement l'approche bag of words ou topic modeling.
+Dans la première, il s'agit
+de formaliser un texte sous forme d'un ensemble de mots
+où on va piocher plus ou moins fréquemment dans un sac de
+mots possibles.
+Dans la seconde, il s'agit de modéliser le processus de choix
+de mots en deux étapes (modèle de mélange): d'abord un choix
+de thème puis, au sein de ce thème, un choix de mots plus ou
+moins fréquents selon le thème.
+
+Dans ces deux approches, l'objet central est la matrice document-terme.
+Elle formalise les fréquences d'occurrence de mots dans des textes ou
+des thèmes. Néanmoins, il s'agit d'une matrice très creuse: même
+un texte au vocabulaire très riche n'explore qu'une petite partie
+du dictionnaire des mots possibles.
+
+L’idée derrière les _embeddings_ est de proposer une information plus
+condensée qui permet néanmoins de capturer les grandes structures
+d'un texte. Il s'agit par exemple de résumer l'ensemble
+d'un corpus en un nombre relativement restreint de dimensions. Ces
+dimensions ne sont pas prédéterminées mais plutôt inférées
+par un modèle qui essaie de trouver la meilleure partition
+des dimensions pour rapprocher les termes équivalents.
+Chacune de ces dimensions va représenter un facteur latent, c’est à dire une variable inobservée, de la même manière que les composantes principales produites par une ACP.
+Techniquement,
+au lieu de représenter les documents par des vecteurs sparse de très grande dimension (la taille du vocabulaire) comme on l’a fait jusqu’à présent, on va les représenter par des vecteurs denses (continus) de dimension réduite (en général, autour de 100-300).
+
+## Intérêt des modèles de langage
+
+Par exemple, un humain sait qu'un document contenant le mot _"Roi"_
+et un autre document contenant le mot _"Reine"_ ont beaucoup de chance
+d'aborder des sujets semblables.
+
+::: {#fig-word2vec}
+
+
+Schéma illustratif de `word2vec`.
+:::
+
+Pourtant, une vectorisation de type comptage ou TF-IDF
+ne permet pas de saisir cette similarité :
+le calcul d'une mesure de similarité (norme euclidienne ou similarité cosinus)
+entre les deux vecteurs donnera une valeur très faible, puisque les mots utilisés sont différents.
+
+A l'inverse, un modèle `word2vec` (voir @fig-word2vec) bien entraîné va capter
+qu'il existe un facteur latent de type _"royauté"_,
+et la similarité entre les vecteurs associés aux deux mots sera forte.
+
+La magie va même plus loin : le modèle captera aussi qu'il existe un
+facteur latent de type _"genre"_,
+et va permettre de construire un espace sémantique dans lequel les
+relations arithmétiques entre vecteurs ont du sens ;
+par exemple (voir @fig-embeddings) :
+
+$$\text{king} - \text{man} + \text{woman} ≈ \text{queen}$$
+
+Chaque mot est représenté par un vecteur de taille fixe (comprenant $n$ nombres),
+de façon à ce que deux mots dont le sens est proche possèdent des représentations numériques proches. Ainsi les mots « chat » et « chaton » devraient avoir des vecteurs de plongement assez similaires, eux-mêmes également assez proches de celui du mot « chien » et plus éloignés de la représentation du mot « maison ».
+
+_Comment ces modèles sont-ils entraînés ?_
+Via une tâche de prédiction résolue par un réseau de neurones simple.
+L'idée fondamentale est que la signification d'un mot se comprend
+en regardant les mots qui apparaissent fréquemment dans son voisinage.
+Pour un mot donné, on va donc essayer de prédire les mots
+qui apparaissent dans une fenêtre autour du mot cible.
+
+En répétant cette tâche de nombreuses fois et sur un corpus suffisamment varié,
+on obtient finalement des *embeddings* pour chaque mot du vocabulaire,
+qui présentent les propriétés discutées précédemment.
+
+::: {#fig-embeddings}
+{ width=70% }
+
+Illustration des *word embeddings*.
+:::
+
+## Les modèles de langage aujourd'hui
+
+La méthode de construction d’un plongement lexical présentée ci-dessus est celle de l’algorithme [`Word2Vec`](https://fr.wikipedia.org/wiki/Word2vec).
+Il s’agit d’un modèle _open-source_ développé par une équipe de `Google` en 2013.
+`Word2Vec` a été le pionnier en termes de modèles de plongement lexical.
+
+Le modèle [`GloVe`](https://nlp.stanford.edu/projects/glove/) constitue un autre exemple [@pennington2014glove]. Développé en 2014 à Stanford,
+ce modèle ne repose pas sur des réseaux de neurones mais sur la construction d’une grande matrice de co-occurrences de mots. Pour chaque mot, il s’agit de calculer les fréquences d’apparition des autres mots dans une fenêtre de taille fixe autour de lui. La matrice de co-occurrences obtenue est ensuite factorisée par une décomposition en valeurs singulières.
+Il est également possible de produire des plongements de mots à partir du [modèle de langage `BERT`](https://jalammar.github.io/illustrated-bert/), développé par `Google` en 2019, dont il existe des déclinaisons dans différentes langues, notamment en Français (les
+modèles [`CamemBERT`](https://camembert-model.fr/) ou [`FlauBERT`](https://github.com/getalp/Flaubert)).
+
+Enfin, le modèle [`FastText`](https://fasttext.cc/), développé en 2016 par une équipe de `Facebook`, fonctionne de façon similaire à `Word2Vec` mais se distingue particulièrement sur deux points :
+
+* En plus des mots eux-mêmes, le modèle apprend des représentations pour les n-grams de caractères (sous-séquences de caractères de taille \\(n\\), par exemple _« tar »_, _« art »_ et _« rte »_ sont les trigrammes du mot _« tarte »_), ce qui le rend notamment robuste aux variations d’orthographe ;
+* Le modèle a été optimisé pour que son entraînement soit particulièrement rapide.
+
+Le modèle `GPT-3` (acronyme de Generative Pre-trained Transformer 3)
+a aujourd'hui le vent en poupe. Celui-ci
+a été développé par la société `OpenAI` et rendu
+public en 2020 [@brown2020language].
+GPT-3 est le plus gros modèle de langage jamais entraîné avec 175 milliards de paramètres. Il sert de brique de base à plusieurs applications
+utilisant l'analyse textuelle pour synthétiser, à partir d'une
+instruction, des éléments importants et
+proposer un texte cohérent. `Github Copilot` l'utilise pour transformer
+une instruction en proposition de code, à partir d'un grand
+corpus de code open source. `Algolia` l'utilise pour transformer une
+instruction en mots clés de recherche afin d'améliorer
+la pertinence des résultats.
+
+En ce moment, le champ du _prompt engineering_ est en effervescence.
+Les modèles de langage comme GPT-3 permettent en effet d'extraire
+les éléments qui permettent de mieux discriminer les thèmes
+d'un texte.
+
+
+## Utilisation dans un processus de créatoin de contenu créatif
+
+La publication par l'organisation [Open AI](https://openai.com/) de
+son modèle de génération de contenu créatif [Dall-E-2](https://openai.com/dall-e-2/)
+(un jeu de mot mélangeant Dali et Wall-E) a créé un bruit inédit dans
+le monde de la _data-science_.
+Un compte Twitter ([Weird Dall-E Mini Generations](https://twitter.com/weirddalle))
+propose de nombreuses générations de contenu drôles ou incongrues.
+Le bloggeur tech Casey Newton a pu parler d'une
+[révolution créative dans le monde de l'IA](https://www.platformer.news/p/how-dall-e-could-power-a-creative).
+
+
+La @fig-shiba montre un exemple d'image générée par DALL-E-2.
+
+::: {#fig-shiba}
+{ width=70% }
+
+_"A Shiba Inu dog wearing a beret and black turtleneck"_
+:::
+
+Les modèles générateurs d'image
+`DallE` et `Stable Diffusion` peuvent, schématiquement,
+être décomposés en deux niveaux de réseaux de neurones:
+
+- le contenu de la phrase est analysé par un modèle de langage comme `GPT-3` ;
+- les éléments importants de la phrase (recontextualisés) sont ensuite transformés en image à partir de
+modèles entraînés à reconnaître des images.
+
+{ fig-align="center" }
+
+`Stable Diffusion` est une version plus accessible que `DALL-E` pour les
+utilisateurs de `Python`.
+
+{ fig-align="center" }
+
+Si vous êtes intéressés par ce type de modèle, vous pouvez
+[tester les exemples du cours de Python de l'ENSAE](https://pythonds.linogaliana.fr/dalle/). Vous pouvez tester
+__"Chuck Norris fighting against Zeus on Mount Olympus in an epic Mortal Kombat scene"__
+pour générer une image comme celle-ci dessous ou chercher à obtenir
+l'image de votre choix:
+
+{ fig-align="center" }
+
+# Modèles de langage dans la statistique publique
+
+L'analyse textuelle dans la statistique publique intervient
+principalement à deux niveaux:
+
+- pour apparier des sources à partir de champs textuels qui
+ne sont pas nécessairement identiques ;
+- pour catégoriser des données dans une nomenclature normalisée
+à partir de champs libres.
+
+## Catégorisation
+
+A `l’Insee`, plusieurs modèles de classification de libellés textuels dans des nomenclatures reposent sur l’algorithme de plongement lexical [`FastText`](https://fasttext.cc/).
+Les derniers mis en oeuvre sont les suivants:
+
+1. catégorisation des professions dans la nomenclature des PCS ;
+2. catégorisation des entreprises dans la nomenclature d'activité APE ;
+3. catégorisation des produits dans la nomenclature des COICOP.
+
+Les deux premiers devraient servir prochainement à la production de statistiques
+officielles. Le troisième est une expérimentation encore en cours.
+
+## Appariements
+
+{ fig-align="center" width=80% }
+
+# Conclusion
+
+# References
+
+::: {#refs}
+:::
diff --git a/textes_exemples.qmd b/textes_exemples.qmd
new file mode 100644
index 0000000..de9b18a
--- /dev/null
+++ b/textes_exemples.qmd
@@ -0,0 +1,15 @@
+---
+title: "Application"
+---
+
+L'objectif de ce TP est d'explorer les aspects suivants du traitement
+du langage naturel:
+
+- _Preprocessing_
+- `ElasticSearch`: indexation et requêtage
+
+Il est disponible sur [cette page](https://pythonds.linogaliana.fr/elastic/) en version _web_
+et peut être ouvert sur l'environnement
+`SSPCloud` où `ElasticSearch` est disponible en cliquant sur le bouton suivant:
+
+
\ No newline at end of file
diff --git a/workflows/prod.yml b/workflows/prod.yml
new file mode 100644
index 0000000..12ba105
--- /dev/null
+++ b/workflows/prod.yml
@@ -0,0 +1,45 @@
+on:
+ push:
+ branches: master
+
+name: Render and Publish
+
+jobs:
+ build-deploy:
+ runs-on: ubuntu-latest
+ steps:
+ - name: Check out repository
+ uses: actions/checkout@v3
+
+ - name: Set up Quarto
+ uses: quarto-dev/quarto-actions/setup@v2
+ with:
+ # To install LaTeX to build PDF book
+ tinytex: true
+ # uncomment below and fill to pin a version
+ # version: 0.9.600
+
+ # add software dependencies here
+
+ # To publish to Netlify, RStudio Connect, or GitHub Pages, uncomment
+ # the appropriate block below
+
+ # - name: Publish to Netlify (and render)
+ # uses: quarto-dev/quarto-actions/publish@v2
+ # with:
+ # target: netlify
+ # NETLIFY_AUTH_TOKEN: ${{ secrets.NETLIFY_AUTH_TOKEN }}
+
+ # - name: Publish to RStudio Connect (and render)
+ # uses: quarto-dev/quarto-actions/publish@v2
+ # with:
+ # target: connect
+ # CONNECT_SERVER: enter-the-server-url-here
+ # CONNECT_API_KEY: ${{ secrets.CONNECT_API_KEY }}
+
+ - name: Publish to GitHub Pages (and render)
+ uses: quarto-dev/quarto-actions/publish@v2
+ with:
+ target: gh-pages
+ env:
+ GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} # this secret is always available for github actions
diff --git a/workflows/test.yml b/workflows/test.yml
new file mode 100644
index 0000000..f3df192
--- /dev/null
+++ b/workflows/test.yml
@@ -0,0 +1,60 @@
+on:
+ pull_request:
+ branches: master
+
+name: Render and Publish
+
+jobs:
+ build-deploy:
+ runs-on: ubuntu-latest
+ steps:
+ - name: Check out repository
+ uses: actions/checkout@v3
+
+ - name: Set up Quarto
+ uses: quarto-dev/quarto-actions/setup@v2
+ with:
+ # To install LaTeX to build PDF book
+ tinytex: true
+ # uncomment below and fill to pin a version
+ # version: 0.9.600
+
+ # add software dependencies here
+
+ # To publish to Netlify, RStudio Connect, or GitHub Pages, uncomment
+ # the appropriate block below
+
+ - name: Render
+ uses: quarto-dev/quarto-actions/render@v2
+
+ - name: Install npm
+ uses: actions/setup-node@v2
+ with:
+ node-version: '14'
+
+ # - name: Deploy to Netlify
+ # # NETLIFY_AUTH_TOKEN and NETLIFY_SITE_ID added in the repo's secrets
+ # env:
+ # NETLIFY_AUTH_TOKEN: ${{ secrets.NETLIFY_AUTH_TOKEN }}
+ # NETLIFY_SITE_ID: ${{ secrets.NETLIFY_SITE_ID }}
+ # BRANCHE_REF: ${{ github.event.pull_request.head.ref }}
+ # run: |
+ # npm init -y
+ # npm install --unsafe-perm=true netlify-cli -g
+ # netlify init
+ # netlify deploy --alias=${BRANCHE_REF} --dir="_site" --message "Preview deploy"
+
+ # - name: Publish to RStudio Connect (and render)
+ # uses: quarto-dev/quarto-actions/publish@v2
+ # with:
+ # target: connect
+ # CONNECT_SERVER: enter-the-server-url-here
+ # CONNECT_API_KEY: ${{ secrets.CONNECT_API_KEY }}
+
+ - name: Publish to GitHub Pages (and render)
+ uses: quarto-dev/quarto-actions/publish@v2
+ with:
+ target: gh-pages
+ env:
+ GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} # this secret is always available for github actions
+