{kind=link}
{kind=link}
![]()
This project is a python framework for sentiment analysis on Twitter data. Essentially, this framework is an experimental work on a submitted paper about US elections 2016. However, it should work with any other subjects with positive, negative and neutral opinions polarity.
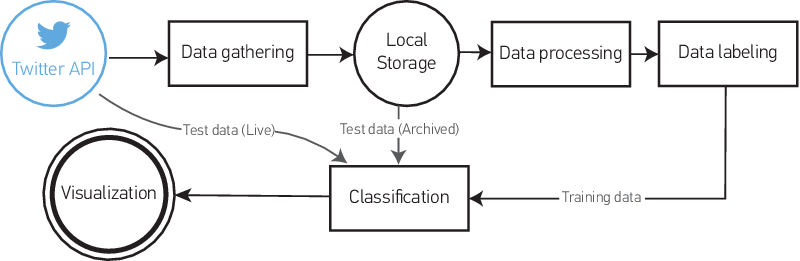
The general framework of our approach is as follows (See figure above):
First, we collect data from Twitter about a specific topic using related seed keywords as filters then we store these gathered data on a local storage system.
Next, we normalize and filter the collected data in order to prepare it for analysis.
Then, we create a set of labeled data using a semi-supervised manner in order to reduce human intervention in the tweet-clusters labeling instead of labeling each tweet separately. We use the final set of labeled data to train a set of supervised classifiers that will be combined for stable and accurate predictions.
Finally, the obtained results are stored into a local storage for visualization, where we couple well established visualization techniques to provide summarized sentiment analysis statistics that resolve the information overload of results efficiently.
There are some requirements in order to use this project. First you have to install python (version 3).
1. Installing Packages The required packages could be easily installed using pip (Python package index).
Open a terminal and access the project directory, Then type this command:
pip install -r requirements.txt
Once the install is finished, you have to install NLTK additional data. For more info read Installing NLTK Data.
2. Installing ElasticSearch and Kibana
Now you are ready to move on to the usage section.
Work in progress
Work in progress
This project is licensed under the MIT License