欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
相信每一位录友都接触过时间复杂度,但又对时间复杂度的认识处于一种朦胧的状态,所以是时候对时间复杂度来一个深度的剖析了。
本篇从如下六点进行分析:
- 究竟什么是时间复杂度
- 什么是大O
- 不同数据规模的差异
- 复杂表达式的化简
- O(logn)中的log是以什么为底?
- 举一个例子
这可能是你见过对时间复杂度分析最通透的一篇文章。
时间复杂度是一个函数,它定性描述该算法的运行时间。
我们在软件开发中,时间复杂度就是用来方便开发者估算出程序运行的答题时间。
那么该如何估计程序运行时间呢,通常会估算算法的操作单元数量来代表程序消耗的时间,这里默认CPU的每个单元运行消耗的时间都是相同的。
假设算法的问题规模为n,那么操作单元数量便用函数f(n)来表示,随着数据规模n的增大,算法执行时间的增长率和f(n)的增长率相同,这称作为算法的渐近时间复杂度,简称时间复杂度,记为 O(f(n))。
这里的大O是指什么呢,说到时间复杂度,大家都知道O(n),O(n^2),却说不清什么是大O。
算法导论给出的解释:大O用来表示上界的,当用它作为算法的最坏情况运行时间的上界,就是对任意数据输入的运行时间的上界。
同样算法导论给出了例子:拿插入排序来说,插入排序的时间复杂度我们都说是O(n^2) 。
输入数据的形式对程序运算时间是有很大影响的,在数据本来有序的情况下时间复杂度是O(n),但如果数据是逆序的话,插入排序的时间复杂度就是O(n^2),也就对于所有输入情况来说,最坏是O(n^2) 的时间复杂度,所以称插入排序的时间复杂度为O(n^2)。
同样的同理再看一下快速排序,都知道快速排序是O(nlogn),但是当数据已经有序情况下,快速排序的时间复杂度是O(n^2) 的,所以严格从大O的定义来讲,快速排序的时间复杂度应该是O(n^2)。
但是我们依然说快速排序是O(nlogn)的时间复杂度,这个就是业内的一个默认规定,这里说的O代表的就是一般情况,而不是严格的上界。如图所示:

我们主要关心的还是一般情况下的数据形式。
面试中说道算法的时间复杂度是多少指的都是一般情况。但是如果面试官和我们深入探讨一个算法的实现以及性能的时候,就要时刻想着数据用例的不一样,时间复杂度也是不同的,这一点是一定要注意的。
如下图中可以看出不同算法的时间复杂度在不同数据输入规模下的差异。
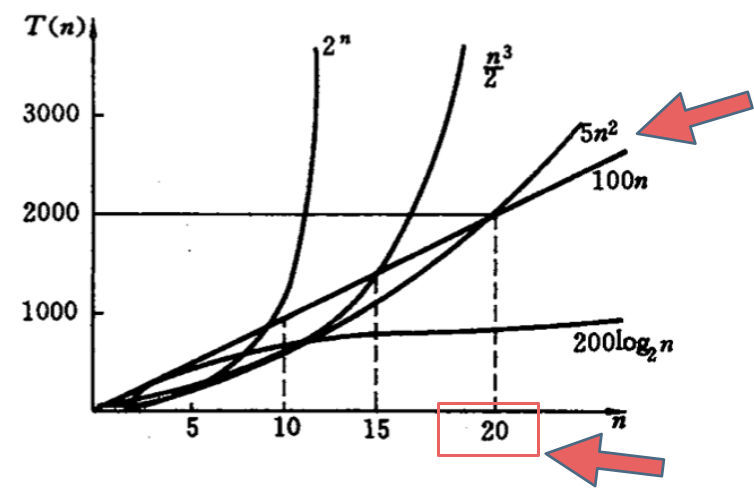
在决定使用哪些算法的时候,不是时间复杂越低的越好(因为简化后的时间复杂度忽略了常数项等等),要考虑数据规模,如果数据规模很小甚至可以用O(n^2)的算法比O(n)的更合适(在有常数项的时候)。
就像上图中 O(5n^2) 和 O(100n) 在n为20之前 很明显 O(5n^2)是更优的,所花费的时间也是最少的。
那为什么在计算时间复杂度的时候要忽略常数项系数呢,也就说O(100n) 就是O(n)的时间复杂度,O(5n^2) 就是O(n^2)的时间复杂度,而且要默认O(n) 优于O(n^2) 呢 ?
这里就又涉及到大O的定义,因为大O就是数据量级突破一个点且数据量级非常大的情况下所表现出的时间复杂度,这个数据量也就是常数项系数已经不起决定性作用的数据量。
例如上图中20就是那个点,n只要大于20 常数项系数已经不起决定性作用了。
所以我们说的时间复杂度都是省略常数项系数的,是因为一般情况下都是默认数据规模足够的大,基于这样的事实,给出的算法时间复杂的的一个排行如下所示:
O(1)常数阶 < O(logn)对数阶 < O(n)线性阶 < O(n^2)平方阶 < O(n^3)(立方阶) < O(2^n) (指数阶)
但是也要注意大常数,如果这个常数非常大,例如10^7 ,10^9 ,那么常数就是不得不考虑的因素了。
有时候我们去计算时间复杂度的时候发现不是一个简单的O(n) 或者O(n^2), 而是一个复杂的表达式,例如:
O(2*n^2 + 10*n + 1000)
那这里如何描述这个算法的时间复杂度呢,一种方法就是简化法。
去掉运行时间中的加法常数项 (因为常数项并不会因为n的增大而增加计算机的操作次数)。
O(2*n^2 + 10*n)
去掉常数系数(上文中已经详细讲过为什么可以去掉常数项的原因)。
O(n^2 + n)
只保留保留最高项,去掉数量级小一级的n (因为n^2 的数据规模远大于n),最终简化为:
O(n^2)
如果这一步理解有困难,那也可以做提取n的操作,变成O(n(n+1)) ,省略加法常数项后也就别变成了:
O(n^2)
所以最后我们说:这个算法的算法时间复杂度是O(n^2) 。
也可以用另一种简化的思路,其实当n大于40的时候, 这个复杂度会恒小于O(3 * n^2), O(2 * n^2 + 10 * n + 1000) < O(3 * n^2),所以说最后省略掉常数项系数最终时间复杂度也是O(n^2)。
平时说这个算法的时间复杂度是logn的,那么一定是log 以2为底n的对数么?
其实不然,也可以是以10为底n的对数,也可以是以20为底n的对数,但我们统一说 logn,也就是忽略底数的描述。
为什么可以这么做呢?如下图所示:

假如有两个算法的时间复杂度,分别是log以2为底n的对数和log以10为底n的对数,那么这里如果还记得高中数学的话,应该不难理解以2为底n的对数 = 以2为底10的对数 * 以10为底n的对数。
而以2为底10的对数是一个常数,在上文已经讲述了我们计算时间复杂度是忽略常数项系数的。
抽象一下就是在时间复杂度的计算过程中,log以i为底n的对数等于log 以j为底n的对数,所以忽略了i,直接说是logn。
这样就应该不难理解为什么忽略底数了。
通过这道面试题目,来分析一下时间复杂度。题目描述:找出n个字符串中相同的两个字符串(假设这里只有两个相同的字符串)。
如果是暴力枚举的话,时间复杂度是多少呢,是O(n^2)么?
这里一些同学会忽略了字符串比较的时间消耗,这里并不像int 型数字做比较那么简单,除了n^2 次的遍历次数外,字符串比较依然要消耗m次操作(m也就是字母串的长度),所以时间复杂度是O(m * n * n)。
接下来再想一下其他解题思路。
先排对n个字符串按字典序来排序,排序后n个字符串就是有序的,意味着两个相同的字符串就是挨在一起,然后在遍历一遍n个字符串,这样就找到两个相同的字符串了。
那看看这种算法的时间复杂度,快速排序时间复杂度为O(nlogn),依然要考虑字符串的长度是m,那么快速排序每次的比较都要有m次的字符比较的操作,就是O(m * n * logn) 。
之后还要遍历一遍这n个字符串找出两个相同的字符串,别忘了遍历的时候依然要比较字符串,所以总共的时间复杂度是 O(m * n * logn + n * m)。
我们对O(m * n * logn + n * m) 进行简化操作,把m * n提取出来变成 O(m * n * (logn + 1)),再省略常数项最后的时间复杂度是 O(m * n * logn)。
最后很明显O(m * n * logn) 要优于O(m * n * n)!
所以先把字符串集合排序再遍历一遍找到两个相同字符串的方法要比直接暴力枚举的方式更快。
这就是我们通过分析两种算法的时间复杂度得来的。
当然这不是这道题目的最优解,我仅仅是用这道题目来讲解一下时间复杂度。
本篇讲解了什么是时间复杂度,复杂度是用来干什么,以及数据规模对时间复杂度的影响。
还讲解了被大多数同学忽略的大O的定义以及log究竟是以谁为底的问题。
再分析了如何简化复杂的时间复杂度,最后举一个具体的例子,把本篇的内容串起来。
相信看完本篇,大家对时间复杂度的认识会深刻很多!
