diff --git a/.github/workflows/hybridsql-docker.yml b/.github/workflows/hybridsql-docker.yml
index a23786743f6..02d52355f4e 100644
--- a/.github/workflows/hybridsql-docker.yml
+++ b/.github/workflows/hybridsql-docker.yml
@@ -93,6 +93,6 @@ jobs:
with:
context: docker
push: ${{ github.event_name == 'push' }}
- platforms: linux/amd64,linux/arm64
+ platforms: linux/amd64
tags: ${{ steps.meta.outputs.tags }}
labels: ${{ steps.meta.outputs.labels }}
diff --git a/.github/workflows/udf-doc.yml b/.github/workflows/udf-doc.yml
index b18263fcbc7..492ea6ebd47 100644
--- a/.github/workflows/udf-doc.yml
+++ b/.github/workflows/udf-doc.yml
@@ -50,11 +50,10 @@ jobs:
make -C hybridse/tools/documentation/udf_doxygen sync
- name: Create Pull Request
- uses: peter-evans/create-pull-request@v4
+ uses: peter-evans/create-pull-request@v6
if: github.event_name != 'pull_request'
with:
add-paths: |
- docs/en/reference/sql/udfs_8h.md
docs/zh/openmldb_sql/udfs_8h.md
labels: |
udf
diff --git a/CHANGELOG.md b/CHANGELOG.md
index 6afc9e2df69..ea3629755ac 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -1,5 +1,14 @@
# Changelog
+## [0.9.2] - 2024-07-26
+
+### Bug Fixes
+- Fix upgrade openmldb sdk version in self host (#3962 @aceforeverd)
+- Fix select from JOB_INFO should always in online mode (#3963 @aceforeverd)
+- Fix update create-pull-request action to v6 in udf-doc-gen workflow & rm deprecated file sync (#3964 @Jayaprakash0511)
+- Fix build in centos7 EOL (#3965 @aceforeverd)
+- Fix numpy version lock (#3966 @aceforeverd)
+
## [0.9.1] - 2024-07-17
### Features
diff --git a/CMakeLists.txt b/CMakeLists.txt
index 81cd36a375a..7fc334f8566 100644
--- a/CMakeLists.txt
+++ b/CMakeLists.txt
@@ -41,7 +41,7 @@ message (STATUS "CMAKE_PREFIX_PATH: ${CMAKE_PREFIX_PATH}")
message (STATUS "CMAKE_BUILD_TYPE: ${CMAKE_BUILD_TYPE}")
set(OPENMLDB_VERSION_MAJOR 0)
set(OPENMLDB_VERSION_MINOR 9)
-set(OPENMLDB_VERSION_BUG 0)
+set(OPENMLDB_VERSION_BUG 1)
function(get_commitid CODE_DIR COMMIT_ID)
find_package(Git REQUIRED)
diff --git a/demo/Dockerfile b/demo/Dockerfile
index 90e4317d5b2..6fd4df3bbd7 100644
--- a/demo/Dockerfile
+++ b/demo/Dockerfile
@@ -16,7 +16,7 @@ RUN apt-get update \
&& rm -rf /var/lib/apt/lists/*
RUN if [ -f "/additions/pypi.txt" ] ; then pip config set global.index-url $(cat /additions/pypi.txt) ; fi
-RUN pip install --no-cache-dir py4j==0.10.9 numpy lightgbm==3 tornado requests pandas==1.5 xgboost==1.4.2
+RUN pip install --no-cache-dir py4j==0.10.9 lightgbm==3 tornado requests pandas==1.5 xgboost==1.4.2 numpy==1.26.4
COPY init.sh /work/
COPY predict-taxi-trip-duration/script /work/taxi-trip/
diff --git a/demo/java_quickstart/demo/pom.xml b/demo/java_quickstart/demo/pom.xml
index 4d05e486276..70c901fa7be 100644
--- a/demo/java_quickstart/demo/pom.xml
+++ b/demo/java_quickstart/demo/pom.xml
@@ -29,7 +29,7 @@
<dependency>
<groupId>com.4paradigm.openmldb</groupId>
<artifactId>openmldb-jdbc</artifactId>
- <version>0.9.0</version>
+ <version>0.9.2</version>
</dependency>
<dependency>
<groupId>org.testng</groupId>
diff --git a/demo/predict-taxi-trip-duration/README.md b/demo/predict-taxi-trip-duration/README.md
index ba537210237..a80a418f06e 100644
--- a/demo/predict-taxi-trip-duration/README.md
+++ b/demo/predict-taxi-trip-duration/README.md
@@ -28,7 +28,7 @@ w2 as (PARTITION BY passenger_count ORDER BY pickup_datetime ROWS_RANGE BETWEEN
**Start docker**
```
-docker run -it 4pdosc/openmldb:0.9.0 bash
+docker run -it 4pdosc/openmldb:0.9.2 bash
```
**Initialize environment**
```bash
@@ -138,7 +138,7 @@ python3 predict.py
**Start docker**
```bash
-docker run -it 4pdosc/openmldb:0.9.0 bash
+docker run -it 4pdosc/openmldb:0.9.2 bash
```
**Initialize environment**
diff --git a/demo/talkingdata-adtracking-fraud-detection/README.md b/demo/talkingdata-adtracking-fraud-detection/README.md
index 085eb37b2a5..77e9214588d 100644
--- a/demo/talkingdata-adtracking-fraud-detection/README.md
+++ b/demo/talkingdata-adtracking-fraud-detection/README.md
@@ -15,7 +15,7 @@ We recommend you to use docker to run the demo. OpenMLDB and dependencies have b
**Start docker**
```
-docker run -it 4pdosc/openmldb:0.9.0 bash
+docker run -it 4pdosc/openmldb:0.9.2 bash
```
#### Run locally
diff --git a/docker/Dockerfile b/docker/Dockerfile
index aab88ecc4b8..37027cd43cc 100644
--- a/docker/Dockerfile
+++ b/docker/Dockerfile
@@ -21,9 +21,13 @@ ARG TARGETARCH
LABEL org.opencontainers.image.source https://github.com/4paradigm/OpenMLDB
-COPY setup_deps.sh /
+COPY ./*.sh /
# hadolint ignore=DL3031,DL3033
-RUN yum update -y && yum install -y centos-release-scl epel-release && \
+RUN sed -i s/mirror.centos.org/vault.centos.org/g /etc/yum.repos.d/*.repo && \
+ sed -i s/^#.*baseurl=http/baseurl=http/g /etc/yum.repos.d/*.repo && \
+ sed -i s/^mirrorlist=http/#mirrorlist=http/g /etc/yum.repos.d/*.repo && \
+ yum update -y && yum install -y centos-release-scl epel-release && \
+ /patch_yum_repo.sh && \
yum install -y devtoolset-8 rh-git227 devtoolset-8-libasan-devel flex doxygen java-1.8.0-openjdk-devel rh-python38-python-devel rh-python38-python-wheel rh-python38-python-requests rh-python38-python-pip && \
curl -Lo lcov-1.15-1.noarch.rpm https://github.com/linux-test-project/lcov/releases/download/v1.15/lcov-1.15-1.noarch.rpm && \
yum localinstall -y lcov-1.15-1.noarch.rpm && \
@@ -33,7 +37,7 @@ RUN yum update -y && yum install -y centos-release-scl epel-release && \
tar xzf zookeeper.tar.gz -C /deps/src && \
rm -v ./*.tar.gz && \
/setup_deps.sh -a "$TARGETARCH" -z "$ZETASQL_VERSION" -t "$THIRDPARTY_VERSION" && \
- rm -v /setup_deps.sh
+ rm -v /*.sh
ENV THIRD_PARTY_DIR=/deps/usr
ENV THIRD_PARTY_SRC_DIR=/deps/src
diff --git a/docker/patch_yum_repo.sh b/docker/patch_yum_repo.sh
new file mode 100755
index 00000000000..b771ec2ed53
--- /dev/null
+++ b/docker/patch_yum_repo.sh
@@ -0,0 +1,11 @@
+#!/bin/bash
+
+set -e
+
+sed -i s/mirror.centos.org/vault.centos.org/g /etc/yum.repos.d/*.repo
+sed -i s/^#.*baseurl=http/baseurl=http/g /etc/yum.repos.d/*.repo
+sed -i s/^mirrorlist=http/#mirrorlist=http/g /etc/yum.repos.d/*.repo
+
+if [[ "$ARCH" = "aarch64" ]]; then
+ sed -i s/vault.centos.org\\/centos/vault.centos.org\\/altarch/g /etc/yum.repos.d/*.repo
+fi
diff --git a/docs/en/blog_post/20240402_OpenmldbVsRedis.md b/docs/en/blog_post/20240402_OpenmldbVsRedis.md
index 19c95361d2a..415c9b37b05 100644
--- a/docs/en/blog_post/20240402_OpenmldbVsRedis.md
+++ b/docs/en/blog_post/20240402_OpenmldbVsRedis.md
@@ -44,7 +44,7 @@ We plan to test with 1 million (referred to as 1M) keys, each corresponding to 1
Deployment can be done through containerization or directly on physical machines using software packages. There is no significant difference between the two methods. Below is an example of using containerization for deployment:
- OpenMLDB
- - Docker image: `docker pull 4pdosc/openmldb:0.9.0`
+ - Docker image: `docker pull 4pdosc/openmldb:0.9.2`
- Documentation: [https://openmldb.ai/docs/zh/main/quickstart/openmldb_quickstart.html](https://openmldb.ai/docs/zh/main/quickstart/openmldb_quickstart.html)
- Redis:
diff --git a/docs/en/blog_post/20240503_OpenmldbRelease.md b/docs/en/blog_post/20240503_OpenmldbRelease.md
new file mode 100644
index 00000000000..adac57fa0c2
--- /dev/null
+++ b/docs/en/blog_post/20240503_OpenmldbRelease.md
@@ -0,0 +1,56 @@
+# OpenMLDB v0.9.0 Release: Major Upgrade in SQL Capabilities Covering the Entire Feature Servicing Process
+
+OpenMLDB has just released a new version v0.9.0, including SQL syntax extensions, MySQL protocol compatibility, TiDB storage support, online feature computation, feature signatures, and more. Among these, the most noteworthy features are the MySQL protocol and ANSI SQL compatibility, along with the extended SQL syntax capabilities.
+
+Firstly, MySQL protocol compatibility allows OpenMLDB users to access OpenMLDB clusters using any MySQL client, not limited to GUI applications like NaviCat or Sequal Ace but also Java JDBC MySQL Driver, Python SQLAlchemy, Go MySQL Driver, and various programming language SDKs. For more information, you can refer to "[**Ultra High-Performance Database OpenM(ysq)LDB: Seamless Compatibility with MySQL Protocol and Multi-Language MySQL Client**](20240322_Openmysqldb.md)".
+
+Secondly, the new version significantly expands SQL capabilities, especially implementing OpenMLDB’s unique request mode and stored procedure execution within standard SQL syntax. Compared to traditional SQL databases, OpenMLDB covers the entire machine learning process, including offline and online modes. In online mode, users can input sample data, and get feature results through SQL feature extraction. On the contrary, in the past, we needed to deploy SQL as a stored procedure through the `Deploy` command and then perform online feature computation through SDKs or HTTP interfaces. The new version adds `SELECT CONFIG` and `CALL` statements, allowing users to directly specify request mode and sample data in SQL to compute feature results, as shown below:
+
+```
+-- Execute online request mode query for action (10, "foo", timestamp(4000))
+SELECT id, count(val) over (partition by id order by ts rows between 10 preceding and current row)
+FROM t1
+CONFIG (execute_mode = 'online', values = (10, "foo", timestamp(4000)))
+```
+You can also use the ANSI SQL `CALL` statement to invoke stored procedures with sample rows as parameters, as shown below:
+
+```
+-- Execute online request mode query for action (10, "foo", timestamp(4000))
+DEPLOY window_features SELECT id, count(val) over (partition by id order by ts rows between 10 preceding and current row)
+FROM t1;
+
+CALL window_features(10, "foo", timestamp(4000))
+```
+For detailed release notes, please refer to: [https://github.com/4paradigm/OpenMLDB/releases/tag/v0.9.0](https://github.com/4paradigm/OpenMLDB/releases/tag/v0.9.0)
+
+Please feel free to download and explore the latest release. Your feedback is highly valued and appreciated. We encourage you to share your thoughts and suggestions to help us improve and enhance the platform. Thank you for your support!
+
+## Release Date
+
+April 25, 2024
+
+## Release Note
+
+[https://github.com/4paradigm/OpenMLDB/releases/tag/v0.9.0](https://github.com/4paradigm/OpenMLDB/releases/tag/v0.9.0)
+
+## Highlighted Features
+
+* Added support for the latest version of SQLAlchemy 2, seamlessly integrating with popular Python frameworks such as Pandas and Numpy.
+
+* Expanded support for more data backends, integrating TiDB’s distributed file storage capability with OpenMLDB’s high-performance in-memory feature computation capability.
+
+* Enhanced ANSI SQL support, fixed `first_value` semantics, supported `MAP` type and feature signatures, and added offline mode support for `INSERT` statements.
+
+* Added support for MySQL protocol, allowing access to OpenMLDB clusters using MySQL clients like NaviCat, Sequal Ace, and various MySQL SDKs for programming languages.
+
+* Extended SQL syntax support, enabling online feature computation directly through `SELECT CONFIG` or `CALL` statements.
+
+--------------------------------------------------------------------------------------------------------------
+
+**For more information on OpenMLDB:**
+* Official website: [https://openmldb.ai/](https://openmldb.ai/)
+* GitHub: [https://github.com/4paradigm/OpenMLDB](https://github.com/4paradigm/OpenMLDB)
+* Documentation: [https://openmldb.ai/docs/en/](https://openmldb.ai/docs/en/)
+* Join us on [**Slack**](https://join.slack.com/t/openmldb/shared_invite/zt-ozu3llie-K~hn9Ss1GZcFW2~K_L5sMg)!
+
+> _This post is a re-post from [OpenMLDB Blogs](https://openmldb.medium.com/)._
diff --git a/docs/en/blog_post/20240523_OpenmldbFeatureSignatures.md b/docs/en/blog_post/20240523_OpenmldbFeatureSignatures.md
new file mode 100644
index 00000000000..abb91bd4bf0
--- /dev/null
+++ b/docs/en/blog_post/20240523_OpenmldbFeatureSignatures.md
@@ -0,0 +1,108 @@
+# Introducing OpenMLDB’s New Feature: Feature Signatures — Enabling Complete Feature Engineering with SQL
+
+## Background
+
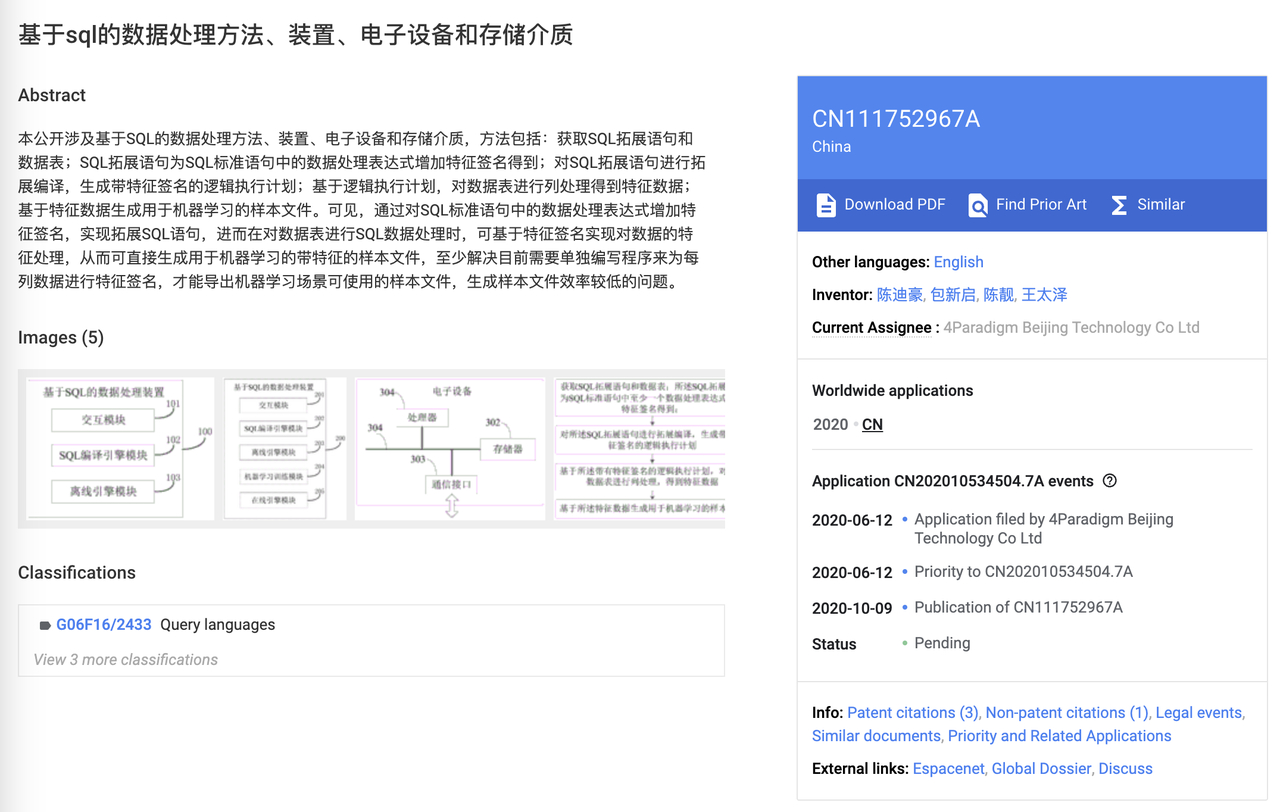
+Rewinding to 2020, the Feature Engine team of Fourth Paradigm submitted and passed an invention patent titled “[Data Processing Method, Device, Electronic Equipment, and Storage Medium Based on SQL](https://patents.google.com/patent/CN111752967A)”. This patent innovatively combines the SQL data processing language with machine learning feature signatures, greatly expanding the functional boundaries of SQL statements.
+
+
+
+At that time, no SQL database or OLAP engine on the market supported this syntax, and even on Fourth Paradigm’s machine learning platform, the feature signature function could only be implemented using a custom DSL (Domain-Specific Language).
+
+Finally, in version v0.9.0, OpenMLDB introduced the feature signature function, supporting sample output in formats such as CSV and LIBSVM. This allows direct integration with machine learning training or prediction while ensuring consistency between offline and online environments.
+
+## Feature Signatures and Label Signatures
+
+The feature signature function in OpenMLDB is implemented based on a series of OpenMLDB-customized UDFs (User-Defined Functions) on top of standard SQL. Currently, OpenMLDB supports the following signature functions:
+
+* `continuous(column)`: Indicates that the column is a continuous feature; the column can be of any numerical type.
+
+* `discrete(column[, bucket_size])`: Indicates that the column is a discrete feature; the column can be of boolean type, integer type, or date and time type. The optional parameter `bucket_size` sets the number of buckets. If `bucket_size` is not specified, the range of values is the entire range of the int64 type.
+
+* `binary_label(column)`: Indicates that the column is a binary classification label; the column must be of boolean type.
+
+* `multiclass_label(column)`: Indicates that the column is a multiclass classification label; the column can be of boolean type or integer type.
+
+* `regression_label(column)`: Indicates that the column is a regression label; the column can be of any numerical type.
+
+These functions must be used in conjunction with the sample format functions `csv` or `libsvm` and cannot be used independently. `csv` and `libsvm` can accept any number of parameters, and each parameter needs to be specified using functions like `continuous` to determine how to sign it. OpenMLDB handles null and erroneous data appropriately, retaining the maximum amount of sample information.
+
+## Usage Example
+
+First, follow the [quick start](https://openmldb.ai/docs/en/main/tutorial/standalone_use.html) guide to get the image and start the OpenMLDB server and client.
+```bash
+docker run -it 4pdosc/openmldb:0.9.2 bash
+/work/init.sh
+/work/openmldb/sbin/openmldb-cli.sh
+```
+
+Create a database and import data in the OpenMLDB client.
+```sql
+--OpenMLDB CLI
+CREATE DATABASE demo_db;
+USE demo_db;
+CREATE TABLE t1(id string, vendor_id int, pickup_datetime timestamp, dropoff_datetime timestamp, passenger_count int, pickup_longitude double, pickup_latitude double, dropoff_longitude double, dropoff_latitude double, store_and_fwd_flag string, trip_duration int);
+SET @@execute_mode='offline';
+LOAD DATA INFILE '/work/taxi-trip/data/taxi_tour_table_train_simple.snappy.parquet' INTO TABLE t1 options(format='parquet', header=true, mode='append');
+```
+
+Use the `SHOW JOBS` command to check the task running status. After the task is successfully executed, perform feature engineering and export the training data in CSV format.
+
+Currently, OpenMLDB does not support overly long column names, so specifying the column name of the sample as `instance` using `SELECT csv(...)` AS instance is necessary.
+
+```sql
+--OpenMLDB CLI
+USE demo_db;
+SET @@execute_mode='offline';
+WITH t1 as (SELECT trip_duration,
+ passenger_count,
+ sum(pickup_latitude) OVER w AS vendor_sum_pl,
+ count(vendor_id) OVER w AS vendor_cnt,
+ FROM t1
+ WINDOW w AS (PARTITION BY vendor_id ORDER BY pickup_datetime ROWS_RANGE BETWEEN 1d PRECEDING AND CURRENT ROW))
+SELECT csv(
+ regression_label(trip_duration),
+ continuous(passenger_count),
+ continuous(vendor_sum_pl),
+ continuous(vendor_cnt),
+ discrete(vendor_cnt DIV 10)) AS instance
+FROM t1 INTO OUTFILE '/tmp/feature_data_csv' OPTIONS(format='csv', header=false, quote='');
+```
+
+If LIBSVM format training data is needed, simply change `SELECT csv(...)` to `SELECT libsvm(...)`. Note that the `OPTIONS` should still use the CSV format because the exported data only has one column, which already contains the complete LIBSVM format sample.
+
+Moreover, the `libsvm` function will start numbering continuous features and discrete features with a known number of buckets from 1. Therefore, specifying the number of buckets ensures that the feature encoding ranges of different columns do not conflict. If the number of buckets for discrete features is not specified, there is a small probability of feature signature conflict in some samples.
+
+```sql
+--OpenMLDB CLI
+USE demo_db;
+SET @@execute_mode='offline';
+WITH t1 as (SELECT trip_duration,
+ passenger_count,
+ sum(pickup_latitude) OVER w AS vendor_sum_pl,
+ count(vendor_id) OVER w AS vendor_cnt,
+ FROM t1
+ WINDOW w AS (PARTITION BY vendor_id ORDER BY pickup_datetime ROWS_RANGE BETWEEN 1d PRECEDING AND CURRENT ROW))
+SELECT libsvm(
+ regression_label(trip_duration),
+ continuous(passenger_count),
+ continuous(vendor_sum_pl),
+ continuous(vendor_cnt),
+ discrete(vendor_cnt DIV 10, 100)) AS instance
+FROM t1 INTO OUTFILE '/tmp/feature_data_libsvm' OPTIONS(format='csv', header=false, quote='');
+```
+
+## Summary
+
+By combining SQL with machine learning, feature signatures simplify the data processing workflow, making feature engineering more efficient and consistent. This innovation extends the functional boundaries of SQL, supporting the output of various formats of data samples, directly connecting to machine learning training and prediction, improving data processing flexibility and accuracy, and having significant implications for data science and engineering practices.
+
+OpenMLDB introduces signature functions to further bridge the gap between feature engineering and machine learning frameworks. By uniformly signing samples with OpenMLDB, offline and online consistency can be improved throughout the entire process, reducing maintenance and change costs. In the future, OpenMLDB will add more signature functions, including one-hot encoding and feature crossing, to make the information in sample feature data more easily utilized by machine learning frameworks.
+
+--------------------------------------------------------------------------------------------------------------
+
+**For more information on OpenMLDB:**
+* Official website: [https://openmldb.ai/](https://openmldb.ai/)
+* GitHub: [https://github.com/4paradigm/OpenMLDB](https://github.com/4paradigm/OpenMLDB)
+* Documentation: [https://openmldb.ai/docs/en/](https://openmldb.ai/docs/en/)
+* Join us on [**Slack**](https://join.slack.com/t/openmldb/shared_invite/zt-ozu3llie-K~hn9Ss1GZcFW2~K_L5sMg)!
+
+> _This post is a re-post from [OpenMLDB Blogs](https://openmldb.medium.com/)._
\ No newline at end of file
diff --git a/docs/en/blog_post/index.rst b/docs/en/blog_post/index.rst
index d3c1097677b..20757e3a3e2 100644
--- a/docs/en/blog_post/index.rst
+++ b/docs/en/blog_post/index.rst
@@ -11,4 +11,9 @@ OpenMLDB Blogs
Ultra High-Performance Database OpenM(ysq)LDB: Seamless Compatibility with MySQL Protocol and Multi-Language MySQL Client <20240322_Openmysqldb.md>
- Comparative Analysis of Memory Consumption: OpenMLDB vs Redis Test Report <20240402_OpenmldbVsRedis.md>
\ No newline at end of file
+ Comparative Analysis of Memory Consumption: OpenMLDB vs Redis Test Report <20240402_OpenmldbVsRedis.md>
+
+ OpenMLDB v0.9.0 Release: Major Upgrade in SQL Capabilities Covering the Entire Feature Servicing Process <20240503_OpenmldbRelease.md>
+
+ Introducing OpenMLDB’s New Feature: Feature Signatures — Enabling Complete Feature Engineering with SQL <20240523_OpenmldbFeatureSignatures.md>
+
diff --git a/docs/en/deploy/compile.md b/docs/en/deploy/compile.md
index b3659b16ab5..f6425c168d7 100644
--- a/docs/en/deploy/compile.md
+++ b/docs/en/deploy/compile.md
@@ -5,7 +5,7 @@
This section describes the steps to compile and use OpenMLDB inside its official docker image [hybridsql](https://hub.docker.com/r/4pdosc/hybridsql), mainly for quick start and development purposes in the docker container.
The docker image has packed the required tools and dependencies, so there is no need to set them up separately. To compile without the official docker image, refer to the section [Detailed Instructions for Build](#detailed-instructions-for-build) below.
-Keep in mind that you should always use the same version of both compile image and [OpenMLDB version](https://github.com/4paradigm/OpenMLDB/releases). This section demonstrates compiling for [OpenMLDB v0.9.0](https://github.com/4paradigm/OpenMLDB/releases/tag/v0.9.0) under `hybridsql:0.9.0` ,If you prefer to compile on the latest code in `main` branch, pull `hybridsql:latest` image instead.
+Keep in mind that you should always use the same version of both compile image and [OpenMLDB version](https://github.com/4paradigm/OpenMLDB/releases). This section demonstrates compiling for [OpenMLDB v0.9.2](https://github.com/4paradigm/OpenMLDB/releases/tag/v0.9.2) under `hybridsql:0.9.2` ,If you prefer to compile on the latest code in `main` branch, pull `hybridsql:latest` image instead.
1. Pull the docker image
@@ -19,11 +19,11 @@ Keep in mind that you should always use the same version of both compile image a
docker run -it 4pdosc/hybridsql:0.9 bash
```
-3. Download the OpenMLDB source code inside the docker container, and set the branch into v0.9.0
+3. Download the OpenMLDB source code inside the docker container, and set the branch into v0.9.2
```bash
cd ~
- git clone -b v0.9.0 https://github.com/4paradigm/OpenMLDB.git
+ git clone -b v0.9.2 https://github.com/4paradigm/OpenMLDB.git
```
4. Compile OpenMLDB
@@ -150,7 +150,7 @@ The built jar packages are in the `target` path of each submodule. If you want t
1. Downloading the pre-built OpenMLDB Spark distribution:
```bash
-wget https://github.com/4paradigm/spark/releases/download/v3.2.1-openmldb0.9.0/spark-3.2.1-bin-openmldbspark.tgz
+wget https://github.com/4paradigm/spark/releases/download/v3.2.1-openmldb0.9.2/spark-3.2.1-bin-openmldbspark.tgz
```
Alternatively, you can also download the source code and compile from scratch:
@@ -209,7 +209,7 @@ After forking the OpenMLDB repository, you can trigger the `Other OS Build` work
- Do not change the `Use workflow from` setting to a specific tag; it can be another branch.
- Choose the desired `OS name`, which in this case is `centos6`.
-- If you are not compiling the main branch, provide the name of the branch, tag (e.g., v0.9.0), or SHA you want to compile in the `The branch, tag, or SHA to checkout, otherwise use the branch` field.
+- If you are not compiling the main branch, provide the name of the branch, tag (e.g., v0.9.2), or SHA you want to compile in the `The branch, tag, or SHA to checkout, otherwise use the branch` field.
- The compilation output will be accessible in "runs", as shown in an example [here](https://github.com/4paradigm/OpenMLDB/actions/runs/6044951902).
- The workflow will definitely produce the OpenMLDB binary file.
- If you don't need the Java or Python SDK, you can configure `java sdk enable` or `python sdk enable` to be "OFF" to save compilation time.
diff --git a/docs/en/deploy/install_deploy.md b/docs/en/deploy/install_deploy.md
index 6fef8791230..0bbdc165101 100644
--- a/docs/en/deploy/install_deploy.md
+++ b/docs/en/deploy/install_deploy.md
@@ -56,17 +56,17 @@ If your operating system is not mentioned above or if you want to compile from s
### Linux Platform Compatibility Pre-test
-Due to the variations among Linux platforms, the distribution package may not be entirely compatible with your machine. Therefore, it's recommended to conduct a preliminary compatibility test. Download the pre-compiled package `openmldb-0.9.0-linux.tar.gz`, and execute:
+Due to the variations among Linux platforms, the distribution package may not be entirely compatible with your machine. Therefore, it's recommended to conduct a preliminary compatibility test. Download the pre-compiled package `openmldb-0.9.2-linux.tar.gz`, and execute:
```
-tar -zxvf openmldb-0.9.0-linux.tar.gz
-./openmldb-0.9.0-linux/bin/openmldb --version
+tar -zxvf openmldb-0.9.2-linux.tar.gz
+./openmldb-0.9.2-linux/bin/openmldb --version
```
The result should display the version number of the program, as shown below:
```
-openmldb version 0.9.0-xxxx
+openmldb version 0.9.2-xxxx
Debug build (NDEBUG not #defined)
```
@@ -181,9 +181,9 @@ DataCollector and SyncTool currently do not support one-click deployment. Please
### Download OpenMLDB
```
-wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.9.0/openmldb-0.9.0-linux.tar.gz
-tar -zxvf openmldb-0.9.0-linux.tar.gz
-cd openmldb-0.9.0-linux
+wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.9.2/openmldb-0.9.2-linux.tar.gz
+tar -zxvf openmldb-0.9.2-linux.tar.gz
+cd openmldb-0.9.2-linux
```
### Environment Configuration
@@ -192,7 +192,7 @@ The environment variables are defined in `conf/openmldb-env.sh`, as shown in the
| Environment Variable | Default Value | Note |
| --------------------------------- | ------------------------------------------------------- | ------------------------------------------------------------ |
-| OPENMLDB_VERSION | 0.9.0 | OpenMLDB version |
+| OPENMLDB_VERSION | 0.9.2 | OpenMLDB version |
| OPENMLDB_MODE | standalone | standalone or cluster |
| OPENMLDB_HOME | root directory of the release folder | openmldb root directory |
| SPARK_HOME | $OPENMLDB_HOME/spark | Spark root directory, if the directory does not exist, it will be downloaded automatically.|
@@ -365,10 +365,10 @@ Note that at least two TabletServers need to be deployed, otherwise errors may o
**1. Download the OpenMLDB deployment package**
```
-wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.9.0/openmldb-0.9.0-linux.tar.gz
-tar -zxvf openmldb-0.9.0-linux.tar.gz
-mv openmldb-0.9.0-linux openmldb-tablet-0.9.0
-cd openmldb-tablet-0.9.0
+wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.9.2/openmldb-0.9.2-linux.tar.gz
+tar -zxvf openmldb-0.9.2-linux.tar.gz
+mv openmldb-0.9.2-linux openmldb-tablet-0.9.2
+cd openmldb-tablet-0.9.2
```
**2. Modify the configuration file `conf/tablet.flags`**
@@ -431,12 +431,12 @@ For clustered versions, the number of TabletServers must be 2 or more. If there'
To start the next TabletServer on a different machine, simply repeat the aforementioned steps on that machine. If starting the next TabletServer on the same machine, ensure it's in a different directory, and do not reuse a directory where the TabletServer is already running.
-For instance, you can decompress the package again (avoid using a directory where TabletServer is already running, as files generated after startup may be affected), and name the directory `openmldb-tablet-0.9.0-2`.
+For instance, you can decompress the package again (avoid using a directory where TabletServer is already running, as files generated after startup may be affected), and name the directory `openmldb-tablet-0.9.2-2`.
```
-tar -zxvf openmldb-0.9.0-linux.tar.gz
-mv openmldb-0.9.0-linux openmldb-tablet-0.9.0-2
-cd openmldb-tablet-0.9.0-2
+tar -zxvf openmldb-0.9.2-linux.tar.gz
+mv openmldb-0.9.2-linux openmldb-tablet-0.9.2-2
+cd openmldb-tablet-0.9.2-2
```
Modify the configuration again and start the TabletServer. Note that if all TabletServers are on the same machine, use different port numbers to avoid the "Fail to listen" error in the log (`logs/tablet.WARNING`).
@@ -454,10 +454,10 @@ Please ensure that all TabletServer have been successfully started before deploy
**1. Download the OpenMLDB deployment package**
````
-wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.9.0/openmldb-0.9.0-linux.tar.gz
-tar -zxvf openmldb-0.9.0-linux.tar.gz
-mv openmldb-0.9.0-linux openmldb-ns-0.9.0
-cd openmldb-ns-0.9.0
+wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.9.2/openmldb-0.9.2-linux.tar.gz
+tar -zxvf openmldb-0.9.2-linux.tar.gz
+mv openmldb-0.9.2-linux openmldb-ns-0.9.2
+cd openmldb-ns-0.9.2
````
**2. Modify the configuration file conf/nameserver.flags**
@@ -502,12 +502,12 @@ You can have only one NameServer, but if you need high availability, you can dep
To start the next NameServer on another machine, simply repeat the above steps on that machine. If starting the next NameServer on the same machine, ensure it's in a different directory and do not reuse the directory where NameServer has already been started.
-For instance, you can decompress the package again (avoid using the directory where NameServer is already running, as files generated after startup may be affected) and name the directory `openmldb-ns-0.9.0-2`.
+For instance, you can decompress the package again (avoid using the directory where NameServer is already running, as files generated after startup may be affected) and name the directory `openmldb-ns-0.9.2-2`.
```
-tar -zxvf openmldb-0.9.0-linux.tar.gz
-mv openmldb-0.9.0-linux openmldb-ns-0.9.0-2
-cd openmldb-ns-0.9.0-2
+tar -zxvf openmldb-0.9.2-linux.tar.gz
+mv openmldb-0.9.2-linux openmldb-ns-0.9.2-2
+cd openmldb-ns-0.9.2-2
```
Then modify the configuration and start.
@@ -548,10 +548,10 @@ Before running APIServer, ensure that the TabletServer and NameServer processes
**1. Download the OpenMLDB deployment package**
```
-wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.9.0/openmldb-0.9.0-linux.tar.gz
-tar -zxvf openmldb-0.9.0-linux.tar.gz
-mv openmldb-0.9.0-linux openmldb-apiserver-0.9.0
-cd openmldb-apiserver-0.9.0
+wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.9.2/openmldb-0.9.2-linux.tar.gz
+tar -zxvf openmldb-0.9.2-linux.tar.gz
+mv openmldb-0.9.2-linux openmldb-apiserver-0.9.2
+cd openmldb-apiserver-0.9.2
```
**2. Modify the configuration file conf/apiserver.flags**
@@ -615,18 +615,18 @@ Download the Spark distribution from the [Spark official website](https://spark.
Alternatively, use the OpenMLDB Spark distribution.
```shell
-wget https://github.com/4paradigm/spark/releases/download/v3.2.1-openmldb0.9.0/spark-3.2.1-bin-openmldbspark.tgz
-# Image address (China):https://www.openmldb.com/download/v0.9.0/spark-3.2.1-bin-openmldbspark.tgz
+wget https://github.com/4paradigm/spark/releases/download/v3.2.1-openmldb0.9.2/spark-3.2.1-bin-openmldbspark.tgz
+# Image address (China):https://www.openmldb.com/download/v0.9.2/spark-3.2.1-bin-openmldbspark.tgz
tar -zxvf spark-3.2.1-bin-openmldbspark.tgz
export SPARK_HOME=`pwd`/spark-3.2.1-bin-openmldbspark/
```
OpenMLDB deployment package:
```
-wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.9.0/openmldb-0.9.0-linux.tar.gz
-tar -zxvf openmldb-0.9.0-linux.tar.gz
-mv openmldb-0.9.0-linux openmldb-taskmanager-0.9.0
-cd openmldb-taskmanager-0.9.0
+wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.9.2/openmldb-0.9.2-linux.tar.gz
+tar -zxvf openmldb-0.9.2-linux.tar.gz
+mv openmldb-0.9.2-linux openmldb-taskmanager-0.9.2
+cd openmldb-taskmanager-0.9.2
```
**2. Modify the configuration file conf/taskmanager.properties**
diff --git a/docs/en/integration/deploy_integration/OpenMLDB_Byzer_taxi.md b/docs/en/integration/deploy_integration/OpenMLDB_Byzer_taxi.md
index d9f9464786d..a3ba6d87e8d 100644
--- a/docs/en/integration/deploy_integration/OpenMLDB_Byzer_taxi.md
+++ b/docs/en/integration/deploy_integration/OpenMLDB_Byzer_taxi.md
@@ -13,7 +13,7 @@ This article demonstrates how to use [OpenMLDB](https://github.com/4paradigm/Ope
The command is as follows:
```
-docker run --network host -dit --name openmldb -v /mlsql/admin/:/byzermnt 4pdosc/openmldb:0.9.0 bash
+docker run --network host -dit --name openmldb -v /mlsql/admin/:/byzermnt 4pdosc/openmldb:0.9.2 bash
docker exec -it openmldb bash
/work/init.sh
echo "create database db1;" | /work/openmldb/bin/openmldb --zk_cluster=127.0.0.1:2181 --zk_root_path=/openmldb --role=sql_client
diff --git a/docs/en/integration/deploy_integration/airflow_provider_demo.md b/docs/en/integration/deploy_integration/airflow_provider_demo.md
index b8ef81f42b9..51ff8362deb 100644
--- a/docs/en/integration/deploy_integration/airflow_provider_demo.md
+++ b/docs/en/integration/deploy_integration/airflow_provider_demo.md
@@ -36,7 +36,7 @@ For smooth function, we recommend starting OpenMLDB using the docker image and i
Since Airflow Web requires an external port for login, the container's port must be exposed. Then map the downloaded file from the previous step to the `/work/airflow/dags` directory. This step is crucial for Airflow to load the DAGs from this folder correctly.
```
-docker run -p 8080:8080 -v `pwd`/airflow_demo_files:/work/airflow_demo_files -it 4pdosc/openmldb:0.9.0 bash
+docker run -p 8080:8080 -v `pwd`/airflow_demo_files:/work/airflow_demo_files -it 4pdosc/openmldb:0.9.2 bash
```
#### Download and Install Airflow and Airflow OpenMLDB Provider
diff --git a/docs/en/integration/deploy_integration/dolphinscheduler_task_demo.md b/docs/en/integration/deploy_integration/dolphinscheduler_task_demo.md
index 4b2d6260b4c..8f8f9769455 100644
--- a/docs/en/integration/deploy_integration/dolphinscheduler_task_demo.md
+++ b/docs/en/integration/deploy_integration/dolphinscheduler_task_demo.md
@@ -31,7 +31,7 @@ In addition to SQL execution in OpenMLDB, real-time prediction also requires mod
The test can be executed on macOS or Linux, and we recommend running this demo within the provided OpenMLDB docker image. In this setup, both OpenMLDB and DolphinScheduler will be launched inside the container, with the port of DolphinScheduler exposed.
```
-docker run -it -p 12345:12345 4pdosc/openmldb:0.9.0 bash
+docker run -it -p 12345:12345 4pdosc/openmldb:0.9.2 bash
```
```{attention}
For proper configuration of DolphinScheduler, the tenant should be set up as a user of the operating system, and this user must have sudo permissions. It is advised to download and initiate DolphinScheduler within the OpenMLDB container. Otherwise, please ensure that the user has sudo permissions.
diff --git a/docs/en/integration/online_datasources/kafka_connector_demo.md b/docs/en/integration/online_datasources/kafka_connector_demo.md
index e5e41531f51..eb6bcfd22ee 100644
--- a/docs/en/integration/online_datasources/kafka_connector_demo.md
+++ b/docs/en/integration/online_datasources/kafka_connector_demo.md
@@ -49,7 +49,7 @@ This article will use Docker mode to start OpenMLDB, so there is no need to down
We recommend that you bind all three downloaded file packages to the `kafka` directory. Alternatively, you can download the file packages after starting the container. For our demonstration, we assume that the file packages are all in the `/work/kafka` directory.
```
-docker run -it -v `pwd`:/work/kafka 4pdosc/openmldb:0.9.0 bash
+docker run -it -v `pwd`:/work/kafka 4pdosc/openmldb:0.9.2 bash
```
### Note
diff --git a/docs/en/integration/online_datasources/pulsar_connector_demo.md b/docs/en/integration/online_datasources/pulsar_connector_demo.md
index be53ca53541..e5478e2164d 100644
--- a/docs/en/integration/online_datasources/pulsar_connector_demo.md
+++ b/docs/en/integration/online_datasources/pulsar_connector_demo.md
@@ -43,7 +43,7 @@ Currently, only the OpenMLDB cluster version can act as the receiver of sinks, a
We recommend using the 'host network' mode to run Docker and bind the file directory 'files' where the SQL script is located.
```
-docker run -dit --network host -v `pwd`/files:/work/pulsar_files --name openmldb 4pdosc/openmldb:0.9.0 bash
+docker run -dit --network host -v `pwd`/files:/work/pulsar_files --name openmldb 4pdosc/openmldb:0.9.2 bash
docker exec -it openmldb bash
```
diff --git a/docs/en/quickstart/openmldb_quickstart.md b/docs/en/quickstart/openmldb_quickstart.md
index f43fd2f480f..c27be0a2714 100644
--- a/docs/en/quickstart/openmldb_quickstart.md
+++ b/docs/en/quickstart/openmldb_quickstart.md
@@ -18,7 +18,7 @@ This sample program is developed and deployed based on OpenMLDB CLI, so you need
Execute the following command in the command line to pull the OpenMLDB image and start the Docker container:
```bash
-docker run -it 4pdosc/openmldb:0.9.0 bash
+docker run -it 4pdosc/openmldb:0.9.2 bash
```
``` {note}
diff --git a/docs/en/quickstart/sdk/java_sdk.md b/docs/en/quickstart/sdk/java_sdk.md
index ee698531a6c..8d8e809b61e 100644
--- a/docs/en/quickstart/sdk/java_sdk.md
+++ b/docs/en/quickstart/sdk/java_sdk.md
@@ -12,12 +12,12 @@ In Java SDK, the default execution mode for JDBC Statements is online, while the
<dependency>
<groupId>com.4paradigm.openmldb</groupId>
<artifactId>openmldb-jdbc</artifactId>
- <version>0.9.0</version>
+ <version>0.9.2</version>
</dependency>
<dependency>
<groupId>com.4paradigm.openmldb</groupId>
<artifactId>openmldb-native</artifactId>
- <version>0.9.0</version>
+ <version>0.9.2</version>
</dependency>
```
@@ -29,16 +29,16 @@ In Java SDK, the default execution mode for JDBC Statements is online, while the
<dependency>
<groupId>com.4paradigm.openmldb</groupId>
<artifactId>openmldb-jdbc</artifactId>
- <version>0.9.0</version>
+ <version>0.9.2</version>
</dependency>
<dependency>
<groupId>com.4paradigm.openmldb</groupId>
<artifactId>openmldb-native</artifactId>
- <version>0.9.0-macos</version>
+ <version>0.9.2-macos</version>
</dependency>
```
-Note: Since the openmldb-native package contains the C++ static library compiled for OpenMLDB, it defaults to the Linux static library. For macOS, the version of openmldb-native should be changed to `0.9.0-macos`, while the version of openmldb-jdbc remains unchanged.
+Note: Since the openmldb-native package contains the C++ static library compiled for OpenMLDB, it defaults to the Linux static library. For macOS, the version of openmldb-native should be changed to `0.9.2-macos`, while the version of openmldb-jdbc remains unchanged.
The macOS version of openmldb-native only supports macOS 12. To run it on macOS 11 or macOS 10.15, the openmldb-native package needs to be compiled from the source code on the corresponding OS. For detailed compilation methods, please refer to [Java SDK](../../deploy/compile.md#Build-java-sdk-with-multi-processes).
When using a self-compiled openmldb-native package, it is recommended to install it into your local Maven repository using `mvn install`. After that, you can reference it in your project's pom.xml file. It's not advisable to reference it using `scope=system`.
diff --git a/docs/en/reference/ip_tips.md b/docs/en/reference/ip_tips.md
index ea42d40dbba..8ffe4e22e1c 100644
--- a/docs/en/reference/ip_tips.md
+++ b/docs/en/reference/ip_tips.md
@@ -38,12 +38,12 @@ Expose the port through `-p` when starting the container, and the client can acc
The stand-alone version needs to expose the ports of three components (nameserver, tabletserver, apiserver):
```
-docker run -p 6527:6527 -p 9921:9921 -p 8080:8080 -it 4pdosc/openmldb:0.9.0 bash
+docker run -p 6527:6527 -p 9921:9921 -p 8080:8080 -it 4pdosc/openmldb:0.9.2 bash
```
The cluster version needs to expose the zk port and the ports of all components:
```
-docker run -p 2181:2181 -p 7527:7527 -p 10921:10921 -p 10922:10922 -p 8080:8080 -p 9902:9902 -it 4pdosc/openmldb:0.9.0 bash
+docker run -p 2181:2181 -p 7527:7527 -p 10921:10921 -p 10922:10922 -p 8080:8080 -p 9902:9902 -it 4pdosc/openmldb:0.9.2 bash
```
```{tip}
@@ -57,7 +57,7 @@ If the OpenMLDB service process is distributed, the "port number is occupied" ap
#### Host Network
Or more conveniently, use host networking without port isolation, for example:
```
-docker run --network host -it 4pdosc/openmldb:0.9.0 bash
+docker run --network host -it 4pdosc/openmldb:0.9.2 bash
```
But in this case, it is easy to find that the port is occupied by other processes in the host. If occupancy occurs, change the port number carefully.
diff --git a/docs/en/tutorial/standalone_use.md b/docs/en/tutorial/standalone_use.md
index e3b87ab8d00..2e7961f55bd 100644
--- a/docs/en/tutorial/standalone_use.md
+++ b/docs/en/tutorial/standalone_use.md
@@ -11,7 +11,7 @@ This article provides a guide on developing and deploying with OpenMLDB CLI. To
Execute the following command to fetch the OpenMLDB image and initiate a Docker container:
```bash
-docker run -it 4pdosc/openmldb:0.9.0 bash
+docker run -it 4pdosc/openmldb:0.9.2 bash
```
Upon successful container launch, all subsequent commands in this tutorial will assume execution within the container.
diff --git a/docs/en/use_case/JD_recommendation.md b/docs/en/use_case/JD_recommendation.md
index af7bc53b43e..8fdca081016 100644
--- a/docs/en/use_case/JD_recommendation.md
+++ b/docs/en/use_case/JD_recommendation.md
@@ -60,7 +60,7 @@ Pull the OpenMLDB docker image and run.
Since the OpenMLDB cluster needs to communicate with other components, we will use the host network straightaway. In this example, we will use downloaded scripts in the docker, therefore we map the `demodir` directory into the docker container.
```bash
-docker run -dit --name=openmldb --network=host -v $demodir:/work/oneflow_demo 4pdosc/openmldb:0.9.0 bash
+docker run -dit --name=openmldb --network=host -v $demodir:/work/oneflow_demo 4pdosc/openmldb:0.9.2 bash
docker exec -it openmldb bash
```
diff --git a/docs/en/use_case/talkingdata_demo.md b/docs/en/use_case/talkingdata_demo.md
index 0d0c2102745..2eddc17724c 100644
--- a/docs/en/use_case/talkingdata_demo.md
+++ b/docs/en/use_case/talkingdata_demo.md
@@ -13,7 +13,7 @@ It is recommended to run this demo in Docker. Please make sure that OpenMLDB and
**Start the OpenMLDB Docker Image**
```
-docker run -it 4pdosc/openmldb:0.9.0 bash
+docker run -it 4pdosc/openmldb:0.9.2 bash
```
#### 1.1.2 Run Locally
diff --git a/docs/en/use_case/taxi_tour_duration_prediction.md b/docs/en/use_case/taxi_tour_duration_prediction.md
index a99301e8152..dd99c6e4c11 100644
--- a/docs/en/use_case/taxi_tour_duration_prediction.md
+++ b/docs/en/use_case/taxi_tour_duration_prediction.md
@@ -15,7 +15,7 @@ This article is centered around the development and deployment of OpenMLDB CLI.
Execute the following command from the command line to pull the OpenMLDB image and start the Docker container:
```bash
-docker run -it 4pdosc/openmldb:0.9.0 bash
+docker run -it 4pdosc/openmldb:0.9.2 bash
```
This image comes pre-installed with OpenMLDB and encompasses all the scripts, third-party libraries, open-source tools, and training data necessary for this case.
diff --git a/docs/zh/blog_post/20240402_OpenmldbVsRedis.md b/docs/zh/blog_post/20240402_OpenmldbVsRedis.md
index 2f741015d9e..73ab1f801fd 100644
--- a/docs/zh/blog_post/20240402_OpenmldbVsRedis.md
+++ b/docs/zh/blog_post/20240402_OpenmldbVsRedis.md
@@ -47,7 +47,7 @@ OpenMLDB 是一款开源的高性能全内存 SQL 数据库,在时序数据存
#### 操作步骤(复现路径)
1. 部署 OpenMLDB 和 Redis:部署可以使用容器化部署或者使用软件包在物理机上直接部署,经过对比,两者无明显差异。下边以容器化部署为例进行举例描述。
- OpenMLDB:
- - 镜像:`docker pull 4pdosc/openmldb:0.9.0`
+ - 镜像:`docker pull 4pdosc/openmldb:0.9.2`
- 文档:https://openmldb.ai/docs/zh/main/quickstart/openmldb_quickstart.html
- Redis:
- 镜像:`docker pull redis:7.2.4`
diff --git a/docs/zh/blog_post/20240503_OpenmldbRelease.md b/docs/zh/blog_post/20240503_OpenmldbRelease.md
new file mode 100644
index 00000000000..60cb65d3e39
--- /dev/null
+++ b/docs/zh/blog_post/20240503_OpenmldbRelease.md
@@ -0,0 +1,43 @@
+# OpenMLDB v0.9.0 发布:SQL 能力大升级覆盖特征上线全流程
+
+## 发布日期
+
+25 April 2024
+
+## Release note
+
+[https://github.com/4paradigm/OpenMLDB/releases/tag/v0.9.0](https://github.com/4paradigm/OpenMLDB/releases/tag/v0.9.0)
+
+
+## 亮点特性
+- 增加最新版 SQLAlchemy 2 的支持,无缝集成 Pandas 和 Numpy 等常用 Python 框架。
+- 支持更多数据后端,融合 TiDB 的分布式文件存储能力以及 OpenMLDB 内存高性能特征计算能力。
+- 完善 ANSI SQL 支持,修复 `first_value` 语义,支持 MAP 类型和特征签名,离线模式支持 `INSERT` 语句。
+- 支持 MySQL 协议,可用 NaviCat、Sequal Ace 及各种编程语言的 MySQL SDK 访问 OpenMLDB 集群。
+- 支持 SQL 语法拓展,通过 `SELECT CONFIG` 或 `CALL` 语句直接进行在线特征计算。
+
+
+社区朋友们大家好!OpenMLDB 正常发布了一个新的版本 v0.9.0,包含了 SQL 语法拓展、MySQL 协议兼容、TiDB 存储支持、在线执行特征计算、特征签名等功能,其中最值得关注和分享的就是对 MySQL 协议和 ANSI SQL 兼容的特性,以及本地拓展的 SQL 语法能力。
+首先 MySQL 协议兼容让 OpenMLDB 的用户,可以使用任意的 MySQL 客户端来访问 OpenMLDB 集群,不仅限于 NaviCat、Sequal Ace 等 GUI 应用,还可以使用 Java JDBC MySQL Driver、Python SQLAlchemy、Go MySQL Driver 等各种编程语言的 SDK。更多介绍可以参考 《[超高性能数据库 OpenM(ysq)LDB:无缝兼容 MySQL 协议 和多语言 MySQL 客户端](20240322_Openmysqldb.md)》 。
+
+其次新版本极大拓展了 SQL 的能力,尤其是在标准 SQL 语法上实现了 OpenMLDB 特有的请求模式和存储过程的执行。相比于传统的 SQL 数据库,OpenMLDB 覆盖机器学习的全流程,包含离线模式和在线模式,在线模式下支持用户传入单行样本数据,通过 SQL 特征抽取返回特征结果。过去我们需要先通过 `Deploy` 命令部署 SQL 成存储过程,然后通过 SDK 或 HTTP 接口进行在线特征计算。新版本加入了 `SELECT CONFIG` 和 `CALL` 语句,用户在 SQL 中直接指定请求模式和请求样本就可以计算得到特征结果,示例如下。
+
+```
+-- 执行请求行为 (10, "foo", timestamp(4000)) 的在线请求模式 query
+SELECT id, count (val) over (partition by id order by ts rows between 10 preceding and current row)
+FROM t1
+CONFIG (execute_mode = 'online', values = (10, "foo", timestamp (4000)))
+```
+
+也可以通过 ANSI SQL 的 `CALL`语句,以样本行作为参数传入进行存储过程的调用,示例如下。
+
+```
+-- 执行请求行为 (10, "foo", timestamp(4000)) 的在线请求模式 query
+DEPLOY window_features SELECT id, count (val) over (partition by id order by ts rows between 10 preceding and current row)
+FROM t1;
+
+CALL window_features(10, "foo", timestamp(4000))
+```
+
+详细的 release note 参照: [https://github.com/4paradigm/OpenMLDB/releases/tag/v0.9.0](https://github.com/4paradigm/OpenMLDB/releases/tag/v0.9.0)
+欢迎大家下载试用,提供意见。
\ No newline at end of file
diff --git a/docs/zh/blog_post/20240523_OpenmldbFeatureSignatures.md b/docs/zh/blog_post/20240523_OpenmldbFeatureSignatures.md
new file mode 100644
index 00000000000..7fa7b62ec2a
--- /dev/null
+++ b/docs/zh/blog_post/20240523_OpenmldbFeatureSignatures.md
@@ -0,0 +1,95 @@
+# OpenMLDB 新功能介绍:特征签名,让 SQL 完成特征工程全流程
+
+## 背景
+
+时间回溯到2020年,第四范式的特征引擎团队提交并通过了一项发明专利[《基于SQL的数据处理方法、装置、电子设备和 存储介质》](https://patents.google.com/patent/CN111752967A/zh),这项专利创新性地把 SQL 数据处理语言和机器学习的特征签名结合起来,极大拓展了 SQL 语句的功能边界。
+
+
+
+当时市面上还没有任何一种 SQL 数据库或 OLAP 引擎支持这种语法,而第四范式的机器学习平台上也只能用自定义的 DSL 领域描述语言来实现特征签名功能。
+
+终于在 v0.9.0 版本迭代后, OpenMLDB 新增了特征签名功能,支持输出为 CSV、LIBSVM 等格式的样本,可以直接对接机器学习的训练或预估,同时保障了离线和在线的一致性。
+
+## 特征签名和标签签名
+
+OpenMLDB 的特征签名功能是在标准 SQL 的基础上,基于一系列 OpenMLDB 定制的 UDF 实现的,目前OpenMLDB支持以下几种签名函数:
+
+- `continuous(column)` 表示 column 是一个连续特征,column 可以是任意数值类型。
+- `discrete(column[, bucket_size])` 表示 column 是一个离散特征,column 可以是 bool 类型,整数类型,日期与时间类型。 `bucket_size` 是可选参数,用于设置分桶数量,在没有指定 `bucket_size` 时,值域是 int64 类型的全部取值范围。
+- `binary_label(column)` 表示 column 是一个二分类标签, column 必须是 bool 类型。
+- `multiclass_label(column)` 表示 column 是多分类标签, column 可以是 bool 类型或整数类型。
+- `regression_label(column)` 表示 column 是回归标签, column 可以是任意数值类型。
+
+这些函数必须配合样本格式函数 csv 或 libsvm 使用,而不能单独使用。csv 和 libsvm可以接收任意数量的参数,每个参数都需要经过 continuous 等函数来确定如何签名。OpenMLDB 会合理处理空数据和错误数据,保留最大的样本信息量。
+
+## 使用示例
+首先参照[快速入门](https://openmldb.ai/docs/zh/main/tutorial/standalone_use.html)获取镜像并启动 OpenMLDB 服务端和客户端。
+
+```bash
+docker run -it 4pdosc/openmldb:0.9.2 bash
+/work/init.sh
+/work/openmldb/sbin/openmldb-cli.sh
+```
+
+在 OpenMLDB 客户端中创建数据库并导入数据。
+
+```sql
+--OpenMLDB CLI
+CREATE DATABASE demo_db;
+USE demo_db;
+CREATE TABLE t1(id string, vendor_id int, pickup_datetime timestamp, dropoff_datetime timestamp, passenger_count int, pickup_longitude double, pickup_latitude double, dropoff_longitude double, dropoff_latitude double, store_and_fwd_flag string, trip_duration int);
+SET @@execute_mode='offline';
+LOAD DATA INFILE '/work/taxi-trip/data/taxi_tour_table_train_simple.snappy.parquet' INTO TABLE t1 options(format='parquet', header=true, mode='append');
+```
+
+使用命令 `SHOW JOBS` 查看任务运行状态,等待任务运行成功后,进行特征工程并导出 CSV 格式的训练数据。
+
+当前版本的 OpenMLDB 不支持过长的列名,所以通过 `SELECT csv(...) AS instance` 指定样本的列名是必要的。
+
+```sql
+--OpenMLDB CLI
+USE demo_db;
+SET @@execute_mode='offline';
+WITH t1 as (SELECT trip_duration,
+ passenger_count,
+ sum(pickup_latitude) OVER w AS vendor_sum_pl,
+ count(vendor_id) OVER w AS vendor_cnt,
+ FROM t1
+ WINDOW w AS (PARTITION BY vendor_id ORDER BY pickup_datetime ROWS_RANGE BETWEEN 1d PRECEDING AND CURRENT ROW))
+SELECT csv(
+ regression_label(trip_duration),
+ continuous(passenger_count),
+ continuous(vendor_sum_pl),
+ continuous(vendor_cnt),
+ discrete(vendor_cnt DIV 10)) AS instance
+FROM t1 INTO OUTFILE '/tmp/feature_data_csv' OPTIONS(format='csv', header=false, quote='');
+```
+
+如果需要 LIBSVM 格式的训练数据,仅需要将 `SELECT csv(...)` 改为 `SELECT libsvm(...)` 函数,需要注意的是 OPTIONS 中仍然使用 csv 格式,因为导出的数据实际上只有一列,而这一列已经包含了完整的 libsvm 格式的样本。
+
+此外 libsvm 函数会从 1 开始对连续特征和已知分桶数量的离散特征进行编号,因此在指定分桶数量后,可以保证不同列对应的特征编码范围没有冲突。如果不指定离散特征的分桶数量,一些样本的特征签名会有小概率发生冲突。
+
+```sql
+--OpenMLDB CLI
+USE demo_db;
+SET @@execute_mode='offline';
+WITH t1 as (SELECT trip_duration,
+ passenger_count,
+ sum(pickup_latitude) OVER w AS vendor_sum_pl,
+ count(vendor_id) OVER w AS vendor_cnt,
+ FROM t1
+ WINDOW w AS (PARTITION BY vendor_id ORDER BY pickup_datetime ROWS_RANGE BETWEEN 1d PRECEDING AND CURRENT ROW))
+SELECT libsvm(
+ regression_label(trip_duration),
+ continuous(passenger_count),
+ continuous(vendor_sum_pl),
+ continuous(vendor_cnt),
+ discrete(vendor_cnt DIV 10, 100)) AS instance
+FROM t1 INTO OUTFILE '/tmp/feature_data_libsvm' OPTIONS(format='csv', header=false, quote='');
+```
+
+## 总结
+特征签名通过将 SQL 与机器学习相结合,简化了数据处理流程,使得特征工程更加高效和一致。这一创新扩展了 SQL 的功能边界,支持输出多种格式的数据样本,直接对接机器学习训练和预测,提高了数据处理的灵活性和精度,对数据科学和工程实践具有重要意义。
+
+OpenMLDB 引入签名功能进一步缩小了特征工程和机器学习框架的距离,通过 OpenMLDB 统一签名样本,可以进一步提高全流程的离线在线一致性,降低维护变更成本。后续 OpenMLDB 将添加更多的签名函数,包括 onehot 编码以及特征交叉等,使样本特征数据中的信息更容易被机器学习框架充分利用。
+
diff --git a/docs/zh/blog_post/images/20240523-patent.png b/docs/zh/blog_post/images/20240523-patent.png
new file mode 100644
index 00000000000..ad64beaee91
Binary files /dev/null and b/docs/zh/blog_post/images/20240523-patent.png differ
diff --git a/docs/zh/blog_post/index.rst b/docs/zh/blog_post/index.rst
index ba6dea6b5de..baabc6aa7e0 100644
--- a/docs/zh/blog_post/index.rst
+++ b/docs/zh/blog_post/index.rst
@@ -12,4 +12,9 @@
超高性能数据库 OpenM(ysq)LDB:无缝兼容 MySQL 协议 和多语言 MySQL 客户端 <20240322_Openmysqldb.md>
- OpenMLDB vs Redis 内存占用量测试报告 <20240402_OpenmldbVsRedis.md>
\ No newline at end of file
+ OpenMLDB vs Redis 内存占用量测试报告 <20240402_OpenmldbVsRedis.md>
+
+ OpenMLDB v0.9.0 发布:SQL 能力大升级覆盖特征上线全流程 <20240503_OpenmldbRelease.md>
+
+ OpenMLDB 新功能介绍:特征签名,让 SQL 完成特征工程全流程 <20240523_OpenmldbFeatureSignatures.md>
+
diff --git a/docs/zh/deploy/compile.md b/docs/zh/deploy/compile.md
index 2108d507c08..a525416e976 100644
--- a/docs/zh/deploy/compile.md
+++ b/docs/zh/deploy/compile.md
@@ -4,7 +4,7 @@
此节介绍在官方编译镜像 [hybridsql](https://hub.docker.com/r/4pdosc/hybridsql) 中编译 OpenMLDB,主要可以用于在容器内试用和开发目的。镜像内置了编译所需要的工具和依赖,因此不需要额外的步骤单独配置它们。关于基于非 docker 的编译使用方式,请参照下面的 [从源码全量编译](#从源码全量编译) 章节。
-对于编译镜像的版本,需要注意拉取的镜像版本和 [OpenMLDB 发布版本](https://github.com/4paradigm/OpenMLDB/releases)保持一致。以下例子演示了在 `hybridsql:0.9.0` 镜像版本上编译 [OpenMLDB v0.9.0](https://github.com/4paradigm/OpenMLDB/releases/tag/v0.9.0) 的代码,如果要编译最新 `main` 分支的代码,则需要拉取 `hybridsql:latest` 版本镜像。
+对于编译镜像的版本,需要注意拉取的镜像版本和 [OpenMLDB 发布版本](https://github.com/4paradigm/OpenMLDB/releases)保持一致。以下例子演示了在 `hybridsql:0.9.2` 镜像版本上编译 [OpenMLDB v0.9.2](https://github.com/4paradigm/OpenMLDB/releases/tag/v0.9.2) 的代码,如果要编译最新 `main` 分支的代码,则需要拉取 `hybridsql:latest` 版本镜像。
1. 下载 docker 镜像
```bash
@@ -16,10 +16,10 @@
docker run -it 4pdosc/hybridsql:0.9 bash
```
-3. 在 docker 容器内, 克隆 OpenMLDB, 并切换分支到 v0.9.0
+3. 在 docker 容器内, 克隆 OpenMLDB, 并切换分支到 v0.9.2
```bash
cd ~
- git clone -b v0.9.0 https://github.com/4paradigm/OpenMLDB.git
+ git clone -b v0.9.2 https://github.com/4paradigm/OpenMLDB.git
```
4. 在 docker 容器内编译 OpenMLDB
@@ -144,7 +144,7 @@ make SQL_JAVASDK_ENABLE=ON NPROC=4
1. 下载预编译的OpenMLDB Spark发行版。
```bash
-wget https://github.com/4paradigm/spark/releases/download/v3.2.1-openmldb0.9.0/spark-3.2.1-bin-openmldbspark.tgz
+wget https://github.com/4paradigm/spark/releases/download/v3.2.1-openmldb0.9.2/spark-3.2.1-bin-openmldbspark.tgz
```
或者下载源代码并从头开始编译。
@@ -203,7 +203,7 @@ bash steps/centos6_build.sh
Fork OpenMLDB仓库后,可以使用在`Actions`中触发workflow `Other OS Build`,编译产出在`Actions`的`Artifacts`中。workflow 配置方式:
- 不要更换`Use workflow from`为某个tag,可以是其他分支。
- 选择`os name`为`centos6`。
-- 如果不是编译main分支,在`The branch, tag or SHA to checkout, otherwise use the branch`中填写想要的分支名、Tag(e.g. v0.9.0)或SHA。
+- 如果不是编译main分支,在`The branch, tag or SHA to checkout, otherwise use the branch`中填写想要的分支名、Tag(e.g. v0.9.2)或SHA。
- 编译产出在触发后的runs界面中,参考[成功产出的runs链接](https://github.com/4paradigm/OpenMLDB/actions/runs/6044951902)。
- 一定会产出openmldb binary文件。
- 如果不需要Java或Python SDK,可配置`java sdk enable`或`python sdk enable`为`OFF`,节约编译时间。
diff --git a/docs/zh/deploy/install_deploy.md b/docs/zh/deploy/install_deploy.md
index 95d246755b3..d874f95c72f 100644
--- a/docs/zh/deploy/install_deploy.md
+++ b/docs/zh/deploy/install_deploy.md
@@ -50,17 +50,17 @@ strings /lib64/libc.so.6 | grep ^GLIBC_
### Linux 平台预测试
-由于 Linux 平台的多样性,发布包可能在你的机器上不兼容,请先通过简单的运行测试。比如,下载预编译包 `openmldb-0.9.0-linux.tar.gz` 以后,运行:
+由于 Linux 平台的多样性,发布包可能在你的机器上不兼容,请先通过简单的运行测试。比如,下载预编译包 `openmldb-0.9.2-linux.tar.gz` 以后,运行:
```
-tar -zxvf openmldb-0.9.0-linux.tar.gz
-./openmldb-0.9.0-linux/bin/openmldb --version
+tar -zxvf openmldb-0.9.2-linux.tar.gz
+./openmldb-0.9.2-linux/bin/openmldb --version
```
结果应显示该程序的版本号,类似
```
-openmldb version 0.9.0-xxxx
+openmldb version 0.9.2-xxxx
Debug build (NDEBUG not #defined)
```
@@ -175,9 +175,9 @@ DataCollector和SyncTool暂不支持一键部署。请参考手动部署方式
### 下载OpenMLDB发行版
```
-wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.9.0/openmldb-0.9.0-linux.tar.gz
-tar -zxvf openmldb-0.9.0-linux.tar.gz
-cd openmldb-0.9.0-linux
+wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.9.2/openmldb-0.9.2-linux.tar.gz
+tar -zxvf openmldb-0.9.2-linux.tar.gz
+cd openmldb-0.9.2-linux
```
### 脚本使用逻辑
@@ -192,9 +192,9 @@ cd openmldb-0.9.0-linux
| 环境变量 | 默认值 | 定义 |
| -------------------------------- | ------------------------ | --------------------------------------------------------------------------------------------------------------------------------------------- |
-| OPENMLDB_VERSION | 0.9.0 | OpenMLDB版本,主要用于Spark下载,一般不改动。 |
+| OPENMLDB_VERSION | 0.9.2 | OpenMLDB版本,主要用于Spark下载,一般不改动。 |
| OPENMLDB_MODE | cluster | standalone或者cluster |
-| OPENMLDB_HOME | 当前发行版的根目录 | openmldb发行版根目录,不则使用当前根目录,也就是openmldb-0.9.0-linux所在目录。 |
+| OPENMLDB_HOME | 当前发行版的根目录 | openmldb发行版根目录,不则使用当前根目录,也就是openmldb-0.9.2-linux所在目录。 |
| SPARK_HOME | $OPENMLDB_HOME/spark | Spark发行版根目录,如果该目录不存在,自动从网上下载。**此路径也将成为TaskManager运行机器上的Spark安装目录。** |
| RUNNER_EXISTING_SPARK_HOME | | 配置此项,运行TaskManager的机器将使用该Spark环境,将不下载、部署OpenMLDB Spark发行版。 |
| OPENMLDB_USE_EXISTING_ZK_CLUSTER | false | 是否使用已经运行的ZooKeeper集群。如果是`true`,将跳过ZooKeeper集群的部署与管理。 |
@@ -415,10 +415,10 @@ bash bin/zkCli.sh -server 172.27.128.33:7181
**1. 下载OpenMLDB部署包**
```
-wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.9.0/openmldb-0.9.0-linux.tar.gz
-tar -zxvf openmldb-0.9.0-linux.tar.gz
-mv openmldb-0.9.0-linux openmldb-tablet-0.9.0
-cd openmldb-tablet-0.9.0
+wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.9.2/openmldb-0.9.2-linux.tar.gz
+tar -zxvf openmldb-0.9.2-linux.tar.gz
+mv openmldb-0.9.2-linux openmldb-tablet-0.9.2
+cd openmldb-tablet-0.9.2
```
**2. 修改配置文件`conf/tablet.flags`**
```bash
@@ -469,12 +469,12 @@ Start tablet success
在另一台机器启动下一个TabletServer只需在该机器上重复以上步骤。如果是在同一个机器上启动下一个TabletServer,请保证是在另一个目录中,不要重复使用已经启动过TabletServer的目录。
-比如,可以再次解压压缩包(不要cp已经启动过TabletServer的目录,启动后的生成文件会造成影响),并命名目录为`openmldb-tablet-0.9.0-2`。
+比如,可以再次解压压缩包(不要cp已经启动过TabletServer的目录,启动后的生成文件会造成影响),并命名目录为`openmldb-tablet-0.9.2-2`。
```
-tar -zxvf openmldb-0.9.0-linux.tar.gz
-mv openmldb-0.9.0-linux openmldb-tablet-0.9.0-2
-cd openmldb-tablet-0.9.0-2
+tar -zxvf openmldb-0.9.2-linux.tar.gz
+mv openmldb-0.9.2-linux openmldb-tablet-0.9.2-2
+cd openmldb-tablet-0.9.2-2
```
再修改配置并启动。注意,TabletServer如果都在同一台机器上,请使用不同端口号,否则日志(logs/tablet.WARNING)中将会有"Fail to listen"信息。
@@ -488,10 +488,10 @@ cd openmldb-tablet-0.9.0-2
```
**1. 下载OpenMLDB部署包**
````
-wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.9.0/openmldb-0.9.0-linux.tar.gz
-tar -zxvf openmldb-0.9.0-linux.tar.gz
-mv openmldb-0.9.0-linux openmldb-ns-0.9.0
-cd openmldb-ns-0.9.0
+wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.9.2/openmldb-0.9.2-linux.tar.gz
+tar -zxvf openmldb-0.9.2-linux.tar.gz
+mv openmldb-0.9.2-linux openmldb-ns-0.9.2
+cd openmldb-ns-0.9.2
````
**2. 修改配置文件conf/nameserver.flags**
```bash
@@ -529,12 +529,12 @@ NameServer 可以只存在一台,如果你需要高可用性,可以部署多
在另一台机器启动下一个 NameServer 只需在该机器上重复以上步骤。如果是在同一个机器上启动下一个 NameServer,请保证是在另一个目录中,不要重复使用已经启动过 namserver 的目录。
-比如,可以再次解压压缩包(不要cp已经启动过 namserver 的目录,启动后的生成文件会造成影响),并命名目录为`openmldb-ns-0.9.0-2`。
+比如,可以再次解压压缩包(不要cp已经启动过 namserver 的目录,启动后的生成文件会造成影响),并命名目录为`openmldb-ns-0.9.2-2`。
```
-tar -zxvf openmldb-0.9.0-linux.tar.gz
-mv openmldb-0.9.0-linux openmldb-ns-0.9.0-2
-cd openmldb-ns-0.9.0-2
+tar -zxvf openmldb-0.9.2-linux.tar.gz
+mv openmldb-0.9.2-linux openmldb-ns-0.9.2-2
+cd openmldb-ns-0.9.2-2
```
然后再修改配置并启动。
@@ -572,10 +572,10 @@ APIServer负责接收http请求,转发给OpenMLDB集群并返回结果。它
**1. 下载OpenMLDB部署包**
```
-wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.9.0/openmldb-0.9.0-linux.tar.gz
-tar -zxvf openmldb-0.9.0-linux.tar.gz
-mv openmldb-0.9.0-linux openmldb-apiserver-0.9.0
-cd openmldb-apiserver-0.9.0
+wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.9.2/openmldb-0.9.2-linux.tar.gz
+tar -zxvf openmldb-0.9.2-linux.tar.gz
+mv openmldb-0.9.2-linux openmldb-apiserver-0.9.2
+cd openmldb-apiserver-0.9.2
```
**2. 修改配置文件conf/apiserver.flags**
@@ -637,18 +637,18 @@ Spark发行版:
或者使用 OpenMLDB Spark 发行版。
```shell
-wget https://github.com/4paradigm/spark/releases/download/v3.2.1-openmldb0.9.0/spark-3.2.1-bin-openmldbspark.tgz
-# 中国镜像地址:https://www.openmldb.com/download/v0.9.0/spark-3.2.1-bin-openmldbspark.tgz
+wget https://github.com/4paradigm/spark/releases/download/v3.2.1-openmldb0.9.2/spark-3.2.1-bin-openmldbspark.tgz
+# 中国镜像地址:https://www.openmldb.com/download/v0.9.2/spark-3.2.1-bin-openmldbspark.tgz
tar -zxvf spark-3.2.1-bin-openmldbspark.tgz
export SPARK_HOME=`pwd`/spark-3.2.1-bin-openmldbspark/
```
OpenMLDB部署包:
```
-wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.9.0/openmldb-0.9.0-linux.tar.gz
-tar -zxvf openmldb-0.9.0-linux.tar.gz
-mv openmldb-0.9.0-linux openmldb-taskmanager-0.9.0
-cd openmldb-taskmanager-0.9.0
+wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.9.2/openmldb-0.9.2-linux.tar.gz
+tar -zxvf openmldb-0.9.2-linux.tar.gz
+mv openmldb-0.9.2-linux openmldb-taskmanager-0.9.2
+cd openmldb-taskmanager-0.9.2
```
**2. 修改配置文件conf/taskmanager.properties**
diff --git a/docs/zh/integration/deploy_integration/OpenMLDB_Byzer_taxi.md b/docs/zh/integration/deploy_integration/OpenMLDB_Byzer_taxi.md
index 0cf5ab7550a..d9ea4efb466 100644
--- a/docs/zh/integration/deploy_integration/OpenMLDB_Byzer_taxi.md
+++ b/docs/zh/integration/deploy_integration/OpenMLDB_Byzer_taxi.md
@@ -13,7 +13,7 @@
执行命令如下:
```
-docker run --network host -dit --name openmldb -v /mlsql/admin/:/byzermnt 4pdosc/openmldb:0.9.0 bash
+docker run --network host -dit --name openmldb -v /mlsql/admin/:/byzermnt 4pdosc/openmldb:0.9.2 bash
docker exec -it openmldb bash
/work/init.sh
echo "create database db1;" | /work/openmldb/bin/openmldb --zk_cluster=127.0.0.1:2181 --zk_root_path=/openmldb --role=sql_client
diff --git a/docs/zh/integration/deploy_integration/airflow_provider_demo.md b/docs/zh/integration/deploy_integration/airflow_provider_demo.md
index 52490aa4ecc..971aefabc3d 100644
--- a/docs/zh/integration/deploy_integration/airflow_provider_demo.md
+++ b/docs/zh/integration/deploy_integration/airflow_provider_demo.md
@@ -35,7 +35,7 @@ ls airflow_demo_files
登录Airflow Web需要对外端口,所以此处暴露容器的端口。并且直接将上一步下载的文件映射到`/work/airflow/dags`,接下来Airflow将加载此文件夹的DAG。
```
-docker run -p 8080:8080 -v `pwd`/airflow_demo_files:/work/airflow_demo_files -it 4pdosc/openmldb:0.9.0 bash
+docker run -p 8080:8080 -v `pwd`/airflow_demo_files:/work/airflow_demo_files -it 4pdosc/openmldb:0.9.2 bash
```
#### 下载安装Airflow与Airflow OpenMLDB Provider
diff --git a/docs/zh/integration/deploy_integration/dolphinscheduler_task_demo.md b/docs/zh/integration/deploy_integration/dolphinscheduler_task_demo.md
index eb3ecd03d3e..70c5eb77c32 100644
--- a/docs/zh/integration/deploy_integration/dolphinscheduler_task_demo.md
+++ b/docs/zh/integration/deploy_integration/dolphinscheduler_task_demo.md
@@ -31,7 +31,7 @@ OpenMLDB 希望能达成开发即上线的目标,让开发回归本质,而
测试可以在macOS或Linux上运行,推荐在我们提供的 OpenMLDB 镜像内进行演示测试。我们将在这个容器中启动OpenMLDB和DolphinScheduler,暴露DolphinScheduler的web端口:
```
-docker run -it -p 12345:12345 4pdosc/openmldb:0.9.0 bash
+docker run -it -p 12345:12345 4pdosc/openmldb:0.9.2 bash
```
```{attention}
DolphinScheduler 需要配置租户,是操作系统的用户,并且该用户需要有 sudo 权限。所以推荐在 OpenMLDB 容器内下载并启动 DolphinScheduler。否则,请准备有sudo权限的操作系统用户。
diff --git a/docs/zh/integration/online_datasources/kafka_connector_demo.md b/docs/zh/integration/online_datasources/kafka_connector_demo.md
index a32ed71cd08..2a7aec89909 100644
--- a/docs/zh/integration/online_datasources/kafka_connector_demo.md
+++ b/docs/zh/integration/online_datasources/kafka_connector_demo.md
@@ -47,7 +47,7 @@ Kafka利用OpenMLDB Kafka Connector导入数据到OpenMLDB集群,其性能将
我们推荐你将下载的三个文件包都绑定到文件目录`kafka`。当然,也可以在启动容器后,再进行文件包的下载。我们假设文件包都在`/work/kafka`目录中。
```
-docker run -it -v `pwd`:/work/kafka 4pdosc/openmldb:0.9.0 bash
+docker run -it -v `pwd`:/work/kafka 4pdosc/openmldb:0.9.2 bash
```
### 注意事项
diff --git a/docs/zh/integration/online_datasources/pulsar_connector_demo.md b/docs/zh/integration/online_datasources/pulsar_connector_demo.md
index c0ebba325b6..f1f1ecada8a 100644
--- a/docs/zh/integration/online_datasources/pulsar_connector_demo.md
+++ b/docs/zh/integration/online_datasources/pulsar_connector_demo.md
@@ -35,7 +35,7 @@ Apache Pulsar是一个云原生的,分布式消息流平台。它可以作为O
```
我们更推荐你使用‘host network’模式运行docker,以及绑定文件目录‘files’,sql脚本在该目录中。
```
-docker run -dit --network host -v `pwd`/files:/work/pulsar_files --name openmldb 4pdosc/openmldb:0.9.0 bash
+docker run -dit --network host -v `pwd`/files:/work/pulsar_files --name openmldb 4pdosc/openmldb:0.9.2 bash
docker exec -it openmldb bash
```
diff --git a/docs/zh/quickstart/openmldb_quickstart.md b/docs/zh/quickstart/openmldb_quickstart.md
index a239a2afed0..608689a080d 100644
--- a/docs/zh/quickstart/openmldb_quickstart.md
+++ b/docs/zh/quickstart/openmldb_quickstart.md
@@ -19,7 +19,7 @@ OpenMLDB 的主要使用场景为作为机器学习的实时特征平台。其
在命令行执行以下命令拉取 OpenMLDB 镜像,并启动 Docker 容器:
```bash
-docker run -it 4pdosc/openmldb:0.9.0 bash
+docker run -it 4pdosc/openmldb:0.9.2 bash
```
```{note}
diff --git a/docs/zh/quickstart/sdk/java_sdk.md b/docs/zh/quickstart/sdk/java_sdk.md
index adbe8ed7afd..4315ce0d438 100644
--- a/docs/zh/quickstart/sdk/java_sdk.md
+++ b/docs/zh/quickstart/sdk/java_sdk.md
@@ -12,12 +12,12 @@ Java SDK中,JDBC Statement的默认执行模式为在线,SqlClusterExecutor
<dependency>
<groupId>com.4paradigm.openmldb</groupId>
<artifactId>openmldb-jdbc</artifactId>
- <version>0.9.0</version>
+ <version>0.9.2</version>
</dependency>
<dependency>
<groupId>com.4paradigm.openmldb</groupId>
<artifactId>openmldb-native</artifactId>
- <version>0.9.0</version>
+ <version>0.9.2</version>
</dependency>
```
@@ -29,16 +29,16 @@ Java SDK中,JDBC Statement的默认执行模式为在线,SqlClusterExecutor
<dependency>
<groupId>com.4paradigm.openmldb</groupId>
<artifactId>openmldb-jdbc</artifactId>
- <version>0.9.0</version>
+ <version>0.9.2</version>
</dependency>
<dependency>
<groupId>com.4paradigm.openmldb</groupId>
<artifactId>openmldb-native</artifactId>
- <version>0.9.0-macos</version>
+ <version>0.9.2-macos</version>
</dependency>
```
-注意:由于 openmldb-native 中包含了 OpenMLDB 编译的 C++ 静态库,默认是 Linux 静态库,macOS 上需将上述 openmldb-native 的 version 改成 `0.9.0-macos`,openmldb-jdbc 的版本保持不变。
+注意:由于 openmldb-native 中包含了 OpenMLDB 编译的 C++ 静态库,默认是 Linux 静态库,macOS 上需将上述 openmldb-native 的 version 改成 `0.9.2-macos`,openmldb-jdbc 的版本保持不变。
openmldb-native 的 macOS 版本只支持 macOS 12,如需在 macOS 11 或 macOS 10.15上运行,需在相应 OS 上源码编译 openmldb-native 包,详细编译方法见[并发编译 Java SDK](https://openmldb.ai/docs/zh/main/deploy/compile.html#java-sdk)。使用自编译的 openmldb-native 包,推荐使用`mvn install`安装到本地仓库,然后在 pom 中引用本地仓库的 openmldb-native 包,不建议用`scope=system`的方式引用。
diff --git a/docs/zh/reference/ip_tips.md b/docs/zh/reference/ip_tips.md
index 8be774f38fd..4fe447e117f 100644
--- a/docs/zh/reference/ip_tips.md
+++ b/docs/zh/reference/ip_tips.md
@@ -52,15 +52,15 @@ curl http://<IP:port>/dbs/foo -X POST -d'{"mode":"online", "sql":"show component
- 暴露端口,也需要修改apiserver的endpoint改为`0.0.0.0`。这样可以使用127.0.0.1或是公网ip访问到 APIServer。
单机版:
```
- docker run -p 8080:8080 -it 4pdosc/openmldb:0.9.0 bash
+ docker run -p 8080:8080 -it 4pdosc/openmldb:0.9.2 bash
```
集群版:
```
- docker run -p 9080:9080 -it 4pdosc/openmldb:0.9.0 bash
+ docker run -p 9080:9080 -it 4pdosc/openmldb:0.9.2 bash
```
- 使用host网络,可以不用修改endpoint配置。缺点是容易引起端口冲突。
```
- docker run --network host -it 4pdosc/openmldb:0.9.0 bash
+ docker run --network host -it 4pdosc/openmldb:0.9.2 bash
```
如果是跨主机访问容器 onebox 中的 APIServer,可以**任选一种**下面的方式:
@@ -126,17 +126,17 @@ cd /work/openmldb/conf/ && ls | grep -v _ | xargs sed -i s/0.0.0.0/<IP>/g && cd
单机版需要暴露三个组件(nameserver,tabletserver,APIServer)的端口:
```
-docker run -p 6527:6527 -p 9921:9921 -p 8080:8080 -it 4pdosc/openmldb:0.9.0 bash
+docker run -p 6527:6527 -p 9921:9921 -p 8080:8080 -it 4pdosc/openmldb:0.9.2 bash
```
集群版需要暴露zk端口与所有组件的端口:
```
-docker run -p 2181:2181 -p 7527:7527 -p 10921:10921 -p 10922:10922 -p 8080:8080 -p 9902:9902 -it 4pdosc/openmldb:0.9.0 bash
+docker run -p 2181:2181 -p 7527:7527 -p 10921:10921 -p 10922:10922 -p 8080:8080 -p 9902:9902 -it 4pdosc/openmldb:0.9.2 bash
```
- 使用host网络,可以不用修改 endpoint 配置。如果有端口冲突,请修改 server 的端口配置。
```
-docker run --network host -it 4pdosc/openmldb:0.9.0 bash
+docker run --network host -it 4pdosc/openmldb:0.9.2 bash
```
如果是跨主机使用 CLI/SDK 访问问容器onebox,只能通过`--network host`,并更改所有endpoint为公网IP,才能顺利访问。
diff --git a/docs/zh/tutorial/standalone_use.md b/docs/zh/tutorial/standalone_use.md
index ea18f1dde8a..1719cd6c4e6 100644
--- a/docs/zh/tutorial/standalone_use.md
+++ b/docs/zh/tutorial/standalone_use.md
@@ -11,7 +11,7 @@
执行以下命令拉取 OpenMLDB 镜像,并启动 Docker 容器:
```bash
-docker run -it 4pdosc/openmldb:0.9.0 bash
+docker run -it 4pdosc/openmldb:0.9.2 bash
```
成功启动容器以后,本教程中的后续命令默认均在容器内执行。
diff --git a/docs/zh/use_case/JD_recommendation.md b/docs/zh/use_case/JD_recommendation.md
index 8d484ef4c4d..8fa85b0e910 100644
--- a/docs/zh/use_case/JD_recommendation.md
+++ b/docs/zh/use_case/JD_recommendation.md
@@ -74,7 +74,7 @@ docker pull oneflowinc/oneflow-serving:nightly
由于 OpenMLDB 集群需要和其他组件网络通信,我们直接使用 host 网络。本例将在容器中使用已下载的脚本,所以请将数据脚本所在目录 `demodir` 映射为容器中的目录:
```bash
-docker run -dit --name=openmldb --network=host -v $demodir:/work/oneflow_demo 4pdosc/openmldb:0.9.0 bash
+docker run -dit --name=openmldb --network=host -v $demodir:/work/oneflow_demo 4pdosc/openmldb:0.9.2 bash
docker exec -it openmldb bash
```
diff --git a/docs/zh/use_case/talkingdata_demo.md b/docs/zh/use_case/talkingdata_demo.md
index f4ac6bebde5..2ae66d7fe04 100755
--- a/docs/zh/use_case/talkingdata_demo.md
+++ b/docs/zh/use_case/talkingdata_demo.md
@@ -16,7 +16,7 @@
**启动 Docker**
```
-docker run -it 4pdosc/openmldb:0.9.0 bash
+docker run -it 4pdosc/openmldb:0.9.2 bash
```
#### 1.1.2 在本地运行
diff --git a/docs/zh/use_case/taxi_tour_duration_prediction.md b/docs/zh/use_case/taxi_tour_duration_prediction.md
index 09b40513c68..c5a788a5ad1 100644
--- a/docs/zh/use_case/taxi_tour_duration_prediction.md
+++ b/docs/zh/use_case/taxi_tour_duration_prediction.md
@@ -15,7 +15,7 @@
在命令行执行以下命令拉取 OpenMLDB 镜像,并启动 Docker 容器:
```bash
-docker run -it 4pdosc/openmldb:0.9.0 bash
+docker run -it 4pdosc/openmldb:0.9.2 bash
```
该镜像预装了OpenMLDB,并预置了本案例所需要的所有脚本、三方库、开源工具以及训练数据。
diff --git a/hybridse/.gitignore b/hybridse/.gitignore
index dda60ce8d59..707360df67d 100644
--- a/hybridse/.gitignore
+++ b/hybridse/.gitignore
@@ -14,6 +14,7 @@ thirdsrc
src/fe_version.h
src/hyhridse_version.h
+src/case/test_cfg.h
# ignore docgen
style.xml
diff --git a/hybridse/CMakeLists.txt b/hybridse/CMakeLists.txt
index 6640c5b9cd5..6a9dfeaf0a9 100644
--- a/hybridse/CMakeLists.txt
+++ b/hybridse/CMakeLists.txt
@@ -125,6 +125,12 @@ configure_file(
"${PROJECT_SOURCE_DIR}/src/version.h.in"
"${PROJECT_SOURCE_DIR}/src/hybridse_version.h"
)
+
+configure_file(
+ "${PROJECT_SOURCE_DIR}/src/case/test_cfg.h.in"
+ "${PROJECT_SOURCE_DIR}/src/case/test_cfg.h"
+)
+
if (DEFINED ENV{CI})
# suppress useless maven log (e.g download log) on CI environment
set(MAVEN_FLAGS --batch-mode)
diff --git a/hybridse/include/case/sql_case.h b/hybridse/include/case/sql_case.h
index cb2d9907b37..bdc50aa8e35 100644
--- a/hybridse/include/case/sql_case.h
+++ b/hybridse/include/case/sql_case.h
@@ -221,6 +221,9 @@ class SqlCase {
}
static std::set<std::string> HYBRIDSE_LEVEL();
+ // Get the base directory searching for yaml test cases.
+ // It is by default directory to current git repository, or you can override
+ // the base directory with 'SQL_CASE_BASE_DIR' environment variable
static std::string SqlCaseBaseDir();
static bool IsDebug() {
diff --git a/hybridse/src/case/sql_case.cc b/hybridse/src/case/sql_case.cc
index ccb712bbdf9..ac8e2459bd5 100644
--- a/hybridse/src/case/sql_case.cc
+++ b/hybridse/src/case/sql_case.cc
@@ -35,6 +35,7 @@
#include "glog/logging.h"
#include "node/sql_node.h"
#include "plan/plan_api.h"
+#include "case/test_cfg.h"
#include "vm/engine.h"
#include "zetasql/parser/parser.h"
#include "planv2/ast_node_converter.h"
@@ -1762,11 +1763,7 @@ std::string SqlCase::SqlCaseBaseDir() {
if (value != nullptr) {
return std::string(value);
}
- value = getenv("YAML_CASE_BASE_DIR");
- if (value != nullptr) {
- return std::string(value);
- }
- return "";
+ return SQL_CASE_BASE_DIR;
}
absl::StatusOr<std::vector<codec::Row>> ExtractInsertRow(vm::HybridSeJitWrapper* jit, absl::string_view insert,
diff --git a/hybridse/src/case/test_cfg.h.in b/hybridse/src/case/test_cfg.h.in
new file mode 100644
index 00000000000..76709fa9af8
--- /dev/null
+++ b/hybridse/src/case/test_cfg.h.in
@@ -0,0 +1,22 @@
+/**
+ * Copyright (c) 2024 OpenMLDB Authors
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License");
+ * you may not use this file except in compliance with the License.
+ * You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+#ifndef HYBRIDSE_SRC_CASE_TEST_CFG_H_
+#define HYBRIDSE_SRC_CASE_TEST_CFG_H_
+
+#define SQL_CASE_BASE_DIR "${CMAKE_SOURCE_DIR}"
+
+#endif // HYBRIDSE_SRC_CASE_TEST_CFG_H_
diff --git a/hybridse/src/vm/jit.cc b/hybridse/src/vm/jit.cc
index 2bcf0d7ab39..243c0d8f4e8 100644
--- a/hybridse/src/vm/jit.cc
+++ b/hybridse/src/vm/jit.cc
@@ -29,6 +29,7 @@ extern "C" {
#include "llvm/ExecutionEngine/JITSymbol.h"
#include "llvm/ExecutionEngine/Orc/CompileUtils.h"
#include "llvm/ExecutionEngine/Orc/Core.h"
+#include "llvm/ExecutionEngine/JITEventListener.h"
#include "llvm/ExecutionEngine/Orc/ExecutionUtils.h"
#include "llvm/ExecutionEngine/Orc/IRCompileLayer.h"
#include "llvm/ExecutionEngine/Orc/IRTransformLayer.h"
@@ -314,7 +315,7 @@ bool HybridSeMcJitWrapper::AddModule(
} else {
execution_engine_->addModule(std::move(module));
}
- if (jit_options_.IsEnableVTune()) {
+ if (jit_options_.IsEnableVtune()) {
auto listener = ::llvm::JITEventListener::createIntelJITEventListener();
if (listener == nullptr) {
LOG(WARNING) << "Intel jit events is not enabled";
@@ -322,7 +323,7 @@ bool HybridSeMcJitWrapper::AddModule(
execution_engine_->RegisterJITEventListener(listener);
}
}
- if (jit_options_.IsEnableGDB()) {
+ if (jit_options_.IsEnableGdb()) {
auto listener =
::llvm::JITEventListener::createGDBRegistrationListener();
if (listener == nullptr) {
diff --git a/hybridse/tools/documentation/udf_doxygen/Makefile b/hybridse/tools/documentation/udf_doxygen/Makefile
index d3e8a344ba2..ecd3dd9462d 100644
--- a/hybridse/tools/documentation/udf_doxygen/Makefile
+++ b/hybridse/tools/documentation/udf_doxygen/Makefile
@@ -27,7 +27,6 @@ doxygen2md: doxygen
sync: doxygen2md
@if [ -n "$(SYNC_DIR)" ]; then \
- cp -v "$(UDF_GEN_DIR)/Files/udfs_8h.md" "$(SYNC_DIR)/docs/en/reference/sql/udfs_8h.md"; \
cp -v "$(UDF_GEN_DIR)/Files/udfs_8h.md" "$(SYNC_DIR)/docs/zh/openmldb_sql/udfs_8h.md"; \
else \
echo "SKIP SYNC: DEFAULT Sync DIR not found"; \
diff --git a/java/hybridse-native/pom.xml b/java/hybridse-native/pom.xml
index e6e786ce5ac..ba85e0169a0 100644
--- a/java/hybridse-native/pom.xml
+++ b/java/hybridse-native/pom.xml
@@ -5,7 +5,7 @@
<parent>
<artifactId>openmldb-parent</artifactId>
<groupId>com.4paradigm.openmldb</groupId>
- <version>0.9.0</version>
+ <version>0.9.1-SNAPSHOT</version>
<relativePath>../pom.xml</relativePath>
</parent>
<modelVersion>4.0.0</modelVersion>
diff --git a/java/hybridse-proto/pom.xml b/java/hybridse-proto/pom.xml
index cbfebe70f4f..4bd333cb322 100644
--- a/java/hybridse-proto/pom.xml
+++ b/java/hybridse-proto/pom.xml
@@ -4,7 +4,7 @@
<parent>
<artifactId>openmldb-parent</artifactId>
<groupId>com.4paradigm.openmldb</groupId>
- <version>0.9.0</version>
+ <version>0.9.1-SNAPSHOT</version>
<relativePath>../pom.xml</relativePath>
</parent>
<modelVersion>4.0.0</modelVersion>
diff --git a/java/hybridse-sdk/pom.xml b/java/hybridse-sdk/pom.xml
index 72ad352fb93..ed8911fa572 100644
--- a/java/hybridse-sdk/pom.xml
+++ b/java/hybridse-sdk/pom.xml
@@ -6,7 +6,7 @@
<parent>
<artifactId>openmldb-parent</artifactId>
<groupId>com.4paradigm.openmldb</groupId>
- <version>0.9.0</version>
+ <version>0.9.1-SNAPSHOT</version>
<relativePath>../pom.xml</relativePath>
</parent>
<modelVersion>4.0.0</modelVersion>
diff --git a/java/openmldb-batch/pom.xml b/java/openmldb-batch/pom.xml
index 9f38b8d86d8..8c0371e227a 100644
--- a/java/openmldb-batch/pom.xml
+++ b/java/openmldb-batch/pom.xml
@@ -7,7 +7,7 @@
<parent>
<artifactId>openmldb-parent</artifactId>
<groupId>com.4paradigm.openmldb</groupId>
- <version>0.9.0</version>
+ <version>0.9.1-SNAPSHOT</version>
</parent>
<artifactId>openmldb-batch</artifactId>
diff --git a/java/openmldb-batchjob/pom.xml b/java/openmldb-batchjob/pom.xml
index b6074cc648e..e449320d012 100644
--- a/java/openmldb-batchjob/pom.xml
+++ b/java/openmldb-batchjob/pom.xml
@@ -7,7 +7,7 @@
<parent>
<artifactId>openmldb-parent</artifactId>
<groupId>com.4paradigm.openmldb</groupId>
- <version>0.9.0</version>
+ <version>0.9.1-SNAPSHOT</version>
</parent>
<artifactId>openmldb-batchjob</artifactId>
diff --git a/java/openmldb-common/pom.xml b/java/openmldb-common/pom.xml
index da240a18783..6be5746496c 100644
--- a/java/openmldb-common/pom.xml
+++ b/java/openmldb-common/pom.xml
@@ -5,7 +5,7 @@
<parent>
<artifactId>openmldb-parent</artifactId>
<groupId>com.4paradigm.openmldb</groupId>
- <version>0.9.0</version>
+ <version>0.9.1-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>openmldb-common</artifactId>
diff --git a/java/openmldb-jdbc/pom.xml b/java/openmldb-jdbc/pom.xml
index 456fa6ca5e7..f51395b9ac0 100644
--- a/java/openmldb-jdbc/pom.xml
+++ b/java/openmldb-jdbc/pom.xml
@@ -5,7 +5,7 @@
<parent>
<artifactId>openmldb-parent</artifactId>
<groupId>com.4paradigm.openmldb</groupId>
- <version>0.9.0</version>
+ <version>0.9.1-SNAPSHOT</version>
<relativePath>../pom.xml</relativePath>
</parent>
<modelVersion>4.0.0</modelVersion>
diff --git a/java/openmldb-native/pom.xml b/java/openmldb-native/pom.xml
index 3906330d3f4..ed3c45fae8b 100644
--- a/java/openmldb-native/pom.xml
+++ b/java/openmldb-native/pom.xml
@@ -5,7 +5,7 @@
<parent>
<artifactId>openmldb-parent</artifactId>
<groupId>com.4paradigm.openmldb</groupId>
- <version>0.9.0</version>
+ <version>0.9.1-SNAPSHOT</version>
<relativePath>../pom.xml</relativePath>
</parent>
<modelVersion>4.0.0</modelVersion>
diff --git a/java/openmldb-spark-connector/pom.xml b/java/openmldb-spark-connector/pom.xml
index c7a9bda0348..529618163e0 100644
--- a/java/openmldb-spark-connector/pom.xml
+++ b/java/openmldb-spark-connector/pom.xml
@@ -6,7 +6,7 @@
<parent>
<artifactId>openmldb-parent</artifactId>
<groupId>com.4paradigm.openmldb</groupId>
- <version>0.9.0</version>
+ <version>0.9.1-SNAPSHOT</version>
</parent>
<artifactId>openmldb-spark-connector</artifactId>
diff --git a/java/openmldb-synctool/pom.xml b/java/openmldb-synctool/pom.xml
index e1eadef191a..bbdb1aa1fa8 100644
--- a/java/openmldb-synctool/pom.xml
+++ b/java/openmldb-synctool/pom.xml
@@ -6,7 +6,7 @@
<parent>
<artifactId>openmldb-parent</artifactId>
<groupId>com.4paradigm.openmldb</groupId>
- <version>0.9.0</version>
+ <version>0.9.1-SNAPSHOT</version>
</parent>
<artifactId>openmldb-synctool</artifactId>
<name>openmldb-synctool</name>
diff --git a/java/openmldb-taskmanager/pom.xml b/java/openmldb-taskmanager/pom.xml
index 59573b4320b..6fee727ff3e 100644
--- a/java/openmldb-taskmanager/pom.xml
+++ b/java/openmldb-taskmanager/pom.xml
@@ -6,7 +6,7 @@
<parent>
<artifactId>openmldb-parent</artifactId>
<groupId>com.4paradigm.openmldb</groupId>
- <version>0.9.0</version>
+ <version>0.9.1-SNAPSHOT</version>
</parent>
<artifactId>openmldb-taskmanager</artifactId>
<name>openmldb-taskmanager</name>
diff --git a/java/openmldb-taskmanager/src/main/scala/com/_4paradigm/openmldb/taskmanager/JobInfoManager.scala b/java/openmldb-taskmanager/src/main/scala/com/_4paradigm/openmldb/taskmanager/JobInfoManager.scala
index 47f1afb4d7b..7f6cd9c49b8 100644
--- a/java/openmldb-taskmanager/src/main/scala/com/_4paradigm/openmldb/taskmanager/JobInfoManager.scala
+++ b/java/openmldb-taskmanager/src/main/scala/com/_4paradigm/openmldb/taskmanager/JobInfoManager.scala
@@ -73,7 +73,7 @@ object JobInfoManager {
}
def getAllJobs(): List[JobInfo] = {
- val sql = s"SELECT * FROM $JOB_INFO_TABLE_NAME"
+ val sql = s"SELECT * FROM $JOB_INFO_TABLE_NAME CONFIG (execute_mode = 'online')"
val rs = sqlExecutor.executeSQL(INTERNAL_DB_NAME, sql)
// TODO: Reorder in output, use orderby desc if SQL supported
resultSetToJobs(rs).sortWith(_.getId > _.getId)
@@ -82,7 +82,7 @@ object JobInfoManager {
def getUnfinishedJobs(): List[JobInfo] = {
// TODO: Now we can not add index for `state` and run sql with
// s"SELECT * FROM $tableName WHERE state NOT IN (${JobInfo.FINAL_STATE.mkString(",")})"
- val sql = s"SELECT * FROM $JOB_INFO_TABLE_NAME"
+ val sql = s"SELECT * FROM $JOB_INFO_TABLE_NAME CONFIG (execute_mode = 'online')"
val rs = sqlExecutor.executeSQL(INTERNAL_DB_NAME, sql)
val jobs = mutable.ArrayBuffer[JobInfo]()
@@ -99,7 +99,7 @@ object JobInfoManager {
}
def stopJob(jobId: Int): JobInfo = {
- val sql = s"SELECT * FROM $JOB_INFO_TABLE_NAME WHERE id = $jobId"
+ val sql = s"SELECT * FROM $JOB_INFO_TABLE_NAME WHERE id = $jobId CONFIG (execute_mode = 'online')"
val rs = sqlExecutor.executeSQL(INTERNAL_DB_NAME, sql)
val jobInfo = if (rs.getFetchSize == 0) {
@@ -131,7 +131,7 @@ object JobInfoManager {
def getJob(jobId: Int): Option[JobInfo] = {
// TODO: Require to get only one row, https://github.com/4paradigm/OpenMLDB/issues/704
- val sql = s"SELECT * FROM $JOB_INFO_TABLE_NAME WHERE id = $jobId"
+ val sql = s"SELECT * FROM $JOB_INFO_TABLE_NAME WHERE id = $jobId CONFIG (execute_mode = 'online')"
val rs = sqlExecutor.executeSQL(INTERNAL_DB_NAME, sql)
if (rs.getFetchSize == 0) {
diff --git a/java/pom.xml b/java/pom.xml
index cb61ac75ec3..999ae2b8bae 100644
--- a/java/pom.xml
+++ b/java/pom.xml
@@ -7,7 +7,7 @@
<artifactId>openmldb-parent</artifactId>
<packaging>pom</packaging>
<name>openmldb</name>
- <version>0.9.0</version>
+ <version>0.9.1-SNAPSHOT</version>
<modules>
<module>hybridse-sdk</module>
<module>hybridse-native</module>
@@ -65,7 +65,8 @@
<!-- the version for hybridse-native & openmldb-native
override this to publish a variant release e.g. macOS variant
checkout java/prepare_release.sh how to prepare a variant release -->
- <variant.native.version>0.9.0</variant.native.version>
+ <variant.native.version>0.9.1-SNAPSHOT</variant.native.version>
+
<plugin.violationSeverity>error</plugin.violationSeverity>
<spotless-maven-plugin.version>2.9.0</spotless-maven-plugin.version>
<eclipse.jdt.version>4.13.0</eclipse.jdt.version>
diff --git a/python/openmldb_sdk/setup.py b/python/openmldb_sdk/setup.py
index aaf2025ee18..c682cc0c49f 100644
--- a/python/openmldb_sdk/setup.py
+++ b/python/openmldb_sdk/setup.py
@@ -18,7 +18,7 @@
setup(
name='openmldb',
- version='0.9.0',
+ version='0.9.1a0',
author='OpenMLDB Team',
author_email=' ',
url='https://github.com/4paradigm/OpenMLDB',
diff --git a/python/openmldb_tool/setup.py b/python/openmldb_tool/setup.py
index d5e361cd6a7..d43a21c1c70 100644
--- a/python/openmldb_tool/setup.py
+++ b/python/openmldb_tool/setup.py
@@ -18,7 +18,7 @@
setup(
name="openmldb-tool",
- version='0.9.0',
+ version='0.9.1a0',
author="OpenMLDB Team",
author_email=" ",
url="https://github.com/4paradigm/OpenMLDB",
diff --git a/release/conf/openmldb-env.sh b/release/conf/openmldb-env.sh
index b8b1cceb6e2..746575c1f7c 100644
--- a/release/conf/openmldb-env.sh
+++ b/release/conf/openmldb-env.sh
@@ -1,5 +1,5 @@
#! /usr/bin/env bash
-export OPENMLDB_VERSION=0.9.0
+export OPENMLDB_VERSION=0.9.2
# openmldb mode: standalone / cluster
export OPENMLDB_MODE=${OPENMLDB_MODE:=cluster}
# openmldb root path
diff --git a/src/sdk/sql_cluster_router.cc b/src/sdk/sql_cluster_router.cc
index 0a77681668d..607dd1c85b7 100644
--- a/src/sdk/sql_cluster_router.cc
+++ b/src/sdk/sql_cluster_router.cc
@@ -885,7 +885,7 @@ bool SQLClusterRouter::DropTable(const std::string& db, const std::string& table
std::string meta_table = openmldb::nameserver::PRE_AGG_META_NAME;
std::string select_aggr_info =
absl::StrCat("select aggr_db, aggr_table from ", meta_db, ".", meta_table, " where base_table = '",
- table_info->name(), "' and base_db='", table_info->db(), "';");
+ table_info->name(), "' and base_db='", table_info->db(), "' CONFIG (execute_mode = 'online');");
auto rs = ExecuteSQL("", select_aggr_info, true, true, 0, status);
WARN_NOT_OK_AND_RET(status, "get aggr info failed", false);
if (rs->Size() > 0) {
@@ -5143,7 +5143,7 @@ void SQLClusterRouter::ReadSparkConfFromFile(std::string conf_file_path, std::ma
std::shared_ptr<hybridse::sdk::ResultSet> SQLClusterRouter::GetJobResultSet(int job_id,
::hybridse::sdk::Status* status) {
std::string db = openmldb::nameserver::INTERNAL_DB;
- std::string sql = "SELECT * FROM JOB_INFO WHERE id = " + std::to_string(job_id);
+ std::string sql = absl::Substitute("SELECT * FROM JOB_INFO WHERE id = $0 CONFIG (execute_mode = 'online')", job_id);
auto rs = ExecuteSQLParameterized(db, sql, {}, status);
if (!status->IsOK()) {
@@ -5164,7 +5164,7 @@ std::shared_ptr<hybridse::sdk::ResultSet> SQLClusterRouter::GetJobResultSet(int
std::shared_ptr<hybridse::sdk::ResultSet> SQLClusterRouter::GetJobResultSet(::hybridse::sdk::Status* status) {
std::string db = openmldb::nameserver::INTERNAL_DB;
- std::string sql = "SELECT * FROM JOB_INFO";
+ std::string sql = "SELECT * FROM JOB_INFO CONFIG (execute_mode = 'online')";
auto rs = ExecuteSQLParameterized(db, sql, std::shared_ptr<openmldb::sdk::SQLRequestRow>(), status);
if (!status->IsOK()) {
return {};
@@ -5187,7 +5187,7 @@ std::shared_ptr<hybridse::sdk::ResultSet> SQLClusterRouter::GetTaskManagerJobRes
return this->GetJobResultSet(job_id, status);
}
std::string db = openmldb::nameserver::INTERNAL_DB;
- std::string sql = "SELECT * FROM JOB_INFO;";
+ std::string sql = "SELECT * FROM JOB_INFO CONFIG (execute_mode = 'online');";
auto rs = ExecuteSQLParameterized(db, sql, {}, status);
if (!status->IsOK()) {
return {};
@@ -5226,7 +5226,7 @@ std::shared_ptr<hybridse::sdk::ResultSet> SQLClusterRouter::GetNameServerJobResu
}
absl::StatusOr<bool> SQLClusterRouter::GetUser(const std::string& name, UserInfo* user_info) {
- std::string sql = absl::StrCat("select * from ", nameserver::USER_INFO_NAME);
+ std::string sql = absl::StrCat("select * from ", nameserver::USER_INFO_NAME, " CONFIG (execute_mode = 'online')");
hybridse::sdk::Status status;
auto rs =
ExecuteSQLParameterized(nameserver::INTERNAL_DB, sql, std::shared_ptr<openmldb::sdk::SQLRequestRow>(), &status);
diff --git a/test/integration-test/openmldb-test-java/openmldb-sdk-test/pom.xml b/test/integration-test/openmldb-test-java/openmldb-sdk-test/pom.xml
index 32c81920daa..28c15820eda 100644
--- a/test/integration-test/openmldb-test-java/openmldb-sdk-test/pom.xml
+++ b/test/integration-test/openmldb-test-java/openmldb-sdk-test/pom.xml
@@ -15,8 +15,8 @@
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
- <openmldb.batch.version>0.7.0-SNAPSHOT</openmldb.batch.version>
- <openmldb.native.version>0.7.0-SNAPSHOT</openmldb.native.version>
+ <openmldb.batch.version>0.9.0</openmldb.batch.version>
+ <openmldb.native.version>0.9.0</openmldb.native.version>
<spark.version>2.2.0</spark.version>
<suiteXmlFile>test_suite/test_tmp.xml</suiteXmlFile>
<aspectj.version>1.8.9</aspectj.version>
@@ -212,4 +212,4 @@
</plugin>
</plugins>
</build>
-</project>
\ No newline at end of file
+</project>