YES, there are already a million btrfs/rsync scripts out there, I know. I checked them out. It happened that every tool I tested was either:
- made to manage snapshots for native btrfs filesystems (based on btrfs-send)
- having too many impositions/assumptions about how you should structure your backups: you must name or initialize your destinations in some specific way, or cron the executions in another way
- too restrictive in the granularity and retention of snapshots, for example: you can have only N yearly backups, or X monthly, etc
- dependent on things like a database in which to store metadata, or some extra language interpreter to understand, or yet another config file syntax to learn
I wanted something lean and mean, that does the job and gets out of the way, with minimal dependencies. I needed a snapshot structure that was easy to work with, and I also wanted a retention / rotation scheme. I wanted ease of use and above everything, ease of understanding.
So I wrote this little piece and I've been pretty happy with the results:
- instead of new languages, the native syntax and features of rsync, bash and sed/grep regular expressions are exposed through the script, simplifying adoption and leveraging documentation and implementation already there
- the only state is the backup store itself, which holds the only metadata used so far: the timestamp for each backup, that is also nicely encoding the navigational structure. In other words: the database is the filesystem. If more metadata support is added in the future, it will be done through extended attributes, so if you want indexes or caches, you can add them as you need with any of the many external tools available
- internally, liberal use of stream operations allows for a high degree of code reutilization, rendering the code clean and making easy to modify and extend it
Update
The recent commits include bugfixes and improvements (upgrading is recommended). Your help with testing and reporting back any issues observed, as well as any other feedback or request, is very appreciated.
The code has grown beyond the original count from ~50 lines. It's still small for what it packs, but not so as when it was created. Feel free to check the earlier versions, I might add tags to the best ones to aid in their use should that be needed. Note that prior versions might present bugs as no backporting (or even versioning) is in place for old patches.
- Plain bash. No DSL, no complex parameters, no nothing
- ~350 lines of code omitting config, comments and blank lines
- No impositions. It may be used as needed, manually or via cron. It does its job and gets out of the way.
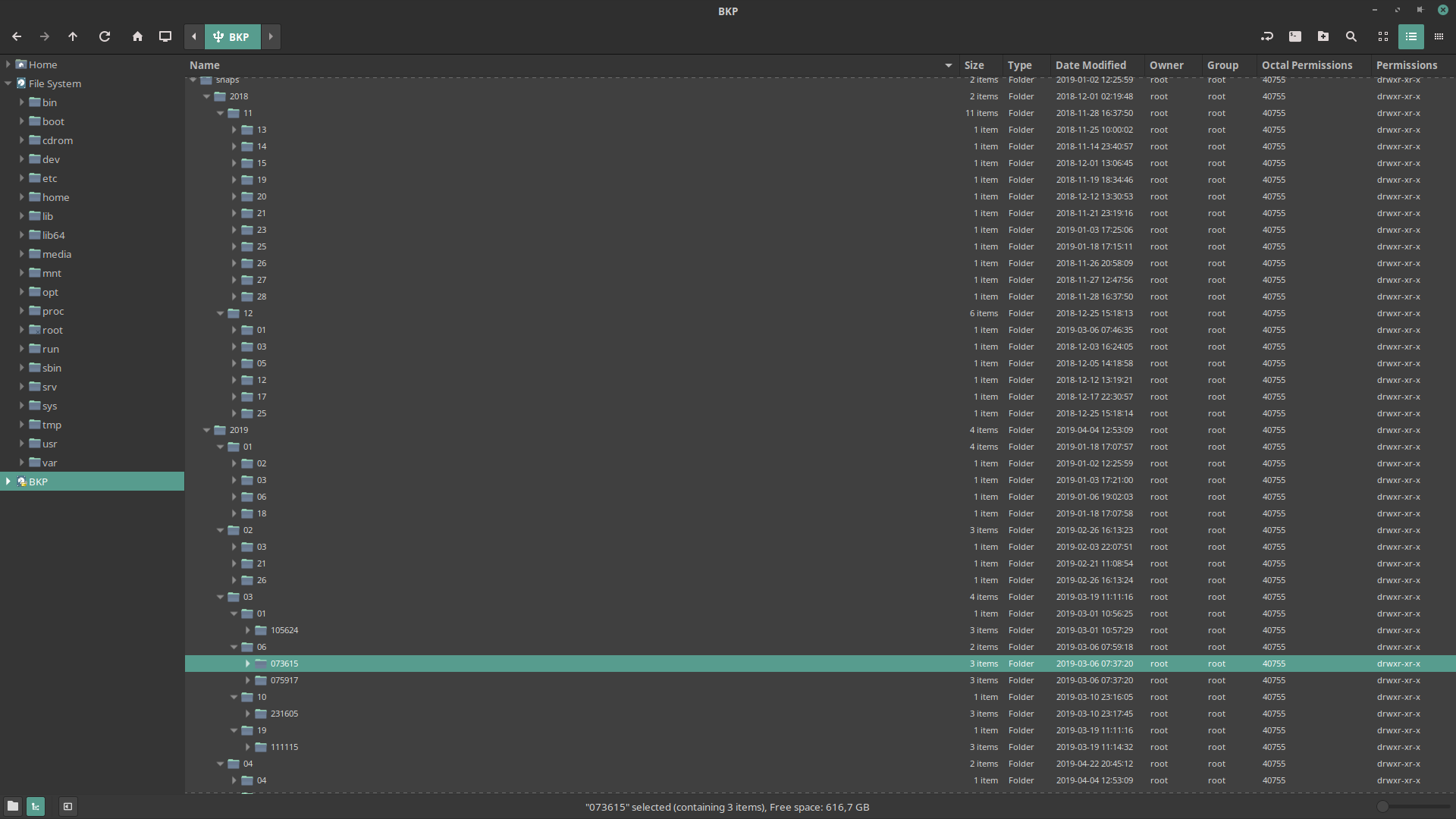
- Does Incremental, in place, COW powered snapshots out of any file system Rsync can read, courtesy of Btrfs
- Custom GFS-style rotation algorithm to maintain arbitrary copies at the snapshot, day, week, month and year levels
- Compact data source specification in extended bash "glob" pattern syntax
- Compact per-data-source filter specification in rsync's own pattern syntax
- Queued operations
- Dry-run mode
- Global defaults / config file / command line option overrides
- Configuration file helpers (showcfg/editcfg/dumpcfg)
- Selectable options for rsync progress report
- Pipeable standard output: non-essential messages are directed to standard error